|
|
本帖最后由 gclome 于 2021-2-24 22:15 编辑
原文链接:Shiro权限绕过合集
CVE-2020-1957
 
影响版本
Apache Shiro <= 1.5.1
Shiro处理
- org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain,
- public FilterChain getChain(ServletRequest request, ServletResponse response, FilterChain originalChain) {
- FilterChainManager filterChainManager = getFilterChainManager();
- if (!filterChainManager.hasChains()) {
- return null;
- }
- String requestURI = getPathWithinApplication(request);
- // in spring web, the requestURI "/resource/menus" ---- "resource/menus/" bose can access the resource
- // but the pathPattern match "/resource/menus" can not match "resource/menus/"
- // user can use requestURI + "/" to simply bypassed chain filter, to bypassed shiro protect
- if(requestURI != null && !DEFAULT_PATH_SEPARATOR.equals(requestURI)
- && requestURI.endsWith(DEFAULT_PATH_SEPARATOR)) {
- requestURI = requestURI.substring(0, requestURI.length() - 1);
- }
- //the 'chain names' in this implementation are actually path patterns defined by the user. We just use them
- //as the chain name for the FilterChainManager's requirements
- for (String pathPattern : filterChainManager.getChainNames()) {
- if (pathPattern != null && !DEFAULT_PATH_SEPARATOR.equals(pathPattern)
- && pathPattern.endsWith(DEFAULT_PATH_SEPARATOR)) {
- pathPattern = pathPattern.substring(0, pathPattern.length() - 1);
- }
- // If the path does match, then pass on to the subclass implementation for specific checks:
- if (pathMatches(pathPattern, requestURI)) {
- ......
- return null;
- }
- org.apache.shiro.web.util.WebUtils#getPathWithinApplication
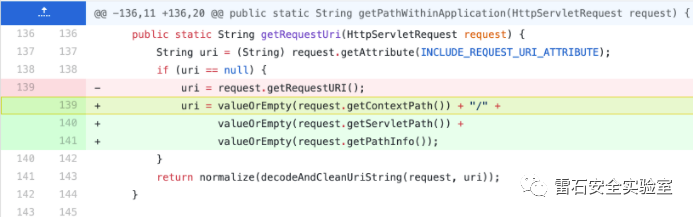
- public static String getPathWithinApplication(HttpServletRequest request) {
- String contextPath = getContextPath(request);
- String requestUri = getRequestUri(request);
- if (StringUtils.startsWithIgnoreCase(requestUri, contextPath)) {
- // Normal case: URI contains context path.
- String path = requestUri.substring(contextPath.length());
- return (StringUtils.hasText(path) ? path : "/");
- } else {
- // Special case: rather unusual.
- return requestUri;
- }
- }
- public static String getContextPath(HttpServletRequest request) {
- String contextPath = (String) request.getAttribute(INCLUDE_CONTEXT_PATH_ATTRIBUTE);
- if (contextPath == null) {
- contextPath = request.getContextPath();
- }
- contextPath = normalize(decodeRequestString(request, contextPath));
- if ("/".equals(contextPath)) {
- // the normalize method will return a "/" and includes on Jetty, will also be a "/".
- contextPath = "";
- }
- return contextPath;
- }
- public static String getRequestUri(HttpServletRequest request) {
- String uri = (String) request.getAttribute(INCLUDE_REQUEST_URI_ATTRIBUTE);
- if (uri == null) {
- uri = request.getRequestURI();
- }
- return normalize(decodeAndCleanUriString(request, uri));
- }
- public static boolean startsWithIgnoreCase(String str, String prefix) {
- if (str == null || prefix == null) {
- return false;
- }
- if (str.startsWith(prefix)) {
- return true;
- }
- if (str.length() < prefix.length()) {
- return false;
- }
- String lcStr = str.substring(0, prefix.length()).toLowerCase();
- String lcPrefix = prefix.toLowerCase();
- return lcStr.equals(lcPrefix);
- }
- public static boolean hasText(String str) {
- if (!hasLength(str)) {
- return false;
- }
- int strLen = str.length();
- for (int i = 0; i < strLen; i++) {
- if (!Character.isWhitespace(str.charAt(i))) {
- return true;
- }
- }
- return false;
- }
- private static String normalize(String path, boolean replaceBackSlash) {
- if (path == null)
- return null;
- // Create a place for the normalized path
- String normalized = path;
- if (replaceBackSlash && normalized.indexOf('\\') >= 0)
- normalized = normalized.replace('\\', '/');
- if (normalized.equals("/."))
- return "/";
- // Add a leading "/" if necessary
- if (!normalized.startsWith("/"))
- normalized = "/" + normalized;
- // Resolve occurrences of "//" in the normalized path
- while (true) {
- int index = normalized.indexOf("//");
- if (index < 0)
- break;
- normalized = normalized.substring(0, index) +
- normalized.substring(index + 1);
- }
- // Resolve occurrences of "/./" in the normalized path
- while (true) {
- int index = normalized.indexOf("/./");
- if (index < 0)
- break;
- normalized = normalized.substring(0, index) +
- normalized.substring(index + 2);
- }
- // Resolve occurrences of "/../" in the normalized path
- while (true) {
- int index = normalized.indexOf("/../");
- if (index < 0)
- break;
- if (index == 0)
- return (null); // Trying to go outside our context
- int index2 = normalized.lastIndexOf('/', index - 1);
- normalized = normalized.substring(0, index2) +
- normalized.substring(index + 3);
- }
- // Return the normalized path that we have completed
- return (normalized);
- }
- private static String decodeAndCleanUriString(HttpServletRequest request, String uri) {
- uri = decodeRequestString(request, uri);
- int semicolonIndex = uri.indexOf(';');
- return (semicolonIndex != -1 ? uri.substring(0, semicolonIndex) : uri);
- }
springboot处理分号,
- org.springframework.web.util.UrlPathHelper#removeSemicolonContentInternal
- private String removeSemicolonContentInternal(String requestUri) {
- for(int semicolonIndex = requestUri.indexOf(59); semicolonIndex != -1; semicolonIndex = requestUri.indexOf(59, semicolonIndex)) {
- int slashIndex = requestUri.indexOf(47, semicolonIndex);
- String start = requestUri.substring(0, semicolonIndex);
- requestUri = slashIndex != -1 ? start + requestUri.substring(slashIndex) : start;
- }
- return requestUri;
- }
漏洞点
在shiro处理路径时,/..;/会变为/..,从而匹配到未需授权路由,再springboot处理时,会根据;截断并重新拼接之前字符串,/..会向上跳跃目录,进一步显示页面.
修复方式
修改了获取uri的方式

CVE-2020-11989
影响范围
Apache Shiro < 1.5.3
Shiro处理
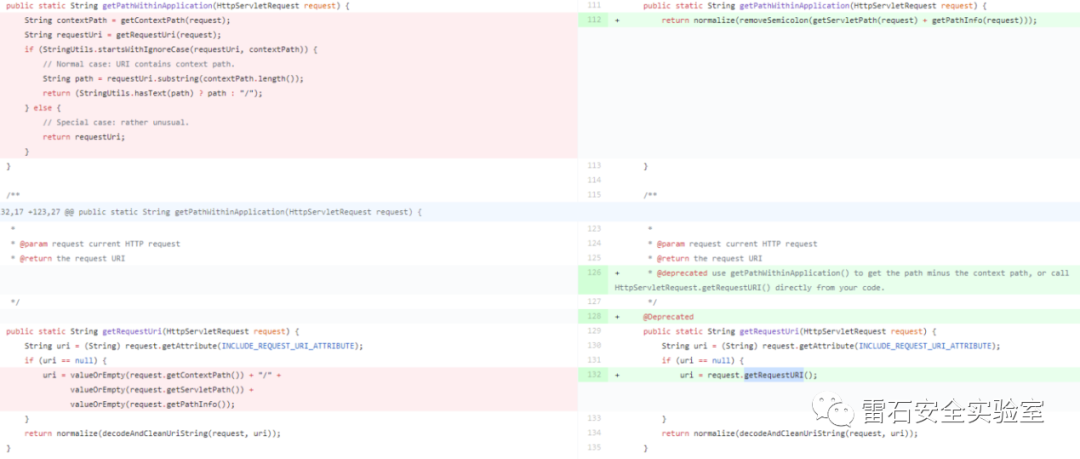
根据之前的修复手段,可以看到uri的获取已经完善,但是对于路径中带分号的情况并未处理,进而导致此次绕过,当存在context-path时,通过访问/;/的情况直接访问到根目录,而springboot会将分号删除拼接,进一步导致绕过.还有一种利用方式在于shiro中*与**路由的区别,当为*时,只对路由下的第一个路径进行鉴权,当存在/admin/a%25%2f%2f/a时,由于shiro会进行url解码,而springboot不会,在springboot设置为/admin/{name}时,导致差异解析.
修复方式
不单独对context-path以及url解码做处理.
CVE-2020-13933
影响版本
Apache Shiro < 1.6.0
Shiro处理
在除去url解码context-path解析处理后,对分号还是没有进行处理,在shiro处理uri时,当路径以/为结尾时,会截取到最后一个/之前的字符串为uri,这时如果鉴权以*为末尾,就会产生绕过无法匹配到处理后类似/admin这样的路径,而在springboot中未进行处理,导致差异解析,这个问题在1.7.0后版本中才正式得到修复.同时再此问题上,可以配合分号,因一直未对其处理,直接截断同样适用此方式.
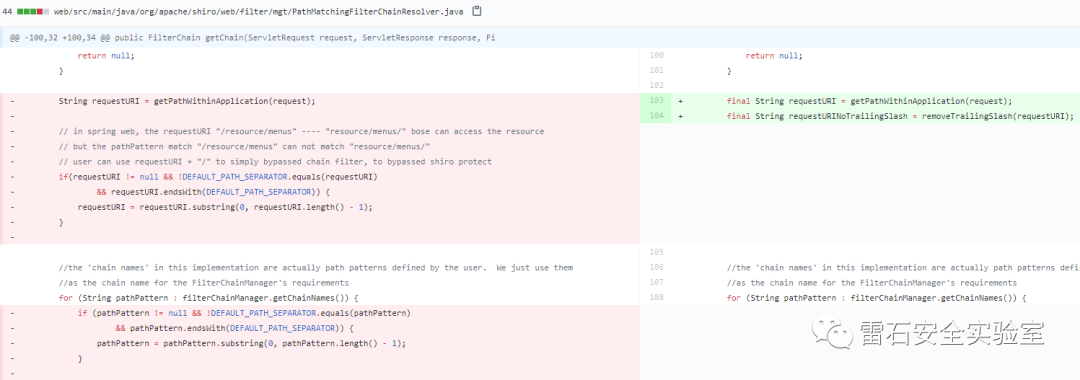
修复手段
增加了InvalidRequestFilter类,全局判断是否存在;、\和其余不可见字符.
CVE-2020-17523
影响版本
Apache Shiro < 1.7.1
Shiro处理
经过之前的修复,对于分号和路径都进行了处理,此次问题出现在pathMatches方法匹配路由中,
- org.apache.shiro.util.AntPathMatcher#doMatch
- protected boolean doMatch(String pattern, String path, boolean fullMatch) {
- if (path.startsWith(this.pathSeparator) != pattern.startsWith(this.pathSeparator)) {
- return false;
- }
- String[] pattDirs = StringUtils.tokenizeToStringArray(pattern, this.pathSeparator);
- String[] pathDirs = StringUtils.tokenizeToStringArray(path, this.pathSeparator);
- int pattIdxStart = 0;
- int pattIdxEnd = pattDirs.length - 1;
- int pathIdxStart = 0;
- int pathIdxEnd = pathDirs.length - 1;
- // Match all elements up to the first **
- while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) {
- String patDir = pattDirs[pattIdxStart];
- if ("**".equals(patDir)) {
- break;
- }
- if (!matchStrings(patDir, pathDirs[pathIdxStart])) {
- return false;
- }
- pattIdxStart++;
- pathIdxStart++;
- }
- if (pathIdxStart > pathIdxEnd) {
- // Path is exhausted, only match if rest of pattern is * or **'s
- if (pattIdxStart > pattIdxEnd) {
- return (pattern.endsWith(this.pathSeparator) ?
- path.endsWith(this.pathSeparator) : !path.endsWith(this.pathSeparator));
- }
- if (!fullMatch) {
- return true;
- }
- if (pattIdxStart == pattIdxEnd && pattDirs[pattIdxStart].equals("*") &&
- path.endsWith(this.pathSeparator)) {
- return true;
- }
- for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
- if (!pattDirs[i].equals("**")) {
- return false;
- }
- }
- return true;
- } else if (pattIdxStart > pattIdxEnd) {
- // String not exhausted, but pattern is. Failure.
- return false;
- } else if (!fullMatch && "**".equals(pattDirs[pattIdxStart])) {
- // Path start definitely matches due to "**" part in pattern.
- return true;
- }
- // up to last '**'
- while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) {
- String patDir = pattDirs[pattIdxEnd];
- if (patDir.equals("**")) {
- break;
- }
- if (!matchStrings(patDir, pathDirs[pathIdxEnd])) {
- return false;
- }
- pattIdxEnd--;
- pathIdxEnd--;
- }
- if (pathIdxStart > pathIdxEnd) {
- // String is exhausted
- for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
- if (!pattDirs[i].equals("**")) {
- return false;
- }
- }
- return true;
- }
- while (pattIdxStart != pattIdxEnd && pathIdxStart <= pathIdxEnd) {
- int patIdxTmp = -1;
- for (int i = pattIdxStart + 1; i <= pattIdxEnd; i++) {
- if (pattDirs[i].equals("**")) {
- patIdxTmp = i;
- break;
- }
- }
- if (patIdxTmp == pattIdxStart + 1) {
- // '**/**' situation, so skip one
- pattIdxStart++;
- continue;
- }
- // Find the pattern between padIdxStart & padIdxTmp in str between
- // strIdxStart & strIdxEnd
- int patLength = (patIdxTmp - pattIdxStart - 1);
- int strLength = (pathIdxEnd - pathIdxStart + 1);
- int foundIdx = -1;
- strLoop:
- for (int i = 0; i <= strLength - patLength; i++) {
- for (int j = 0; j < patLength; j++) {
- String subPat = (String) pattDirs[pattIdxStart + j + 1];
- String subStr = (String) pathDirs[pathIdxStart + i + j];
- if (!matchStrings(subPat, subStr)) {
- continue strLoop;
- }
- }
- foundIdx = pathIdxStart + i;
- break;
- }
- if (foundIdx == -1) {
- return false;
- }
- pattIdxStart = patIdxTmp;
- pathIdxStart = foundIdx + patLength;
- }
- for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
- if (!pattDirs[i].equals("**")) {
- return false;
- }
- }
- return true;
- }
- org.apache.shiro.util.StringUtils#tokenizeToStringArray
中适用了trim会清除空格,当请求路径中存在空格时,返回之前的情况,shiro鉴权适用*时,存在/admin/*无法匹配到/admin/,而在springboot中可以正确匹配,导致差异解析绕过.
修复方式
直接设置清除空格为false,默认不清除.

|
|




 发表于 2021-2-24 22:13:06
发表于 2021-2-24 22:13:06