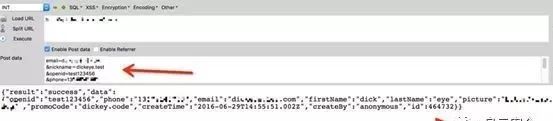
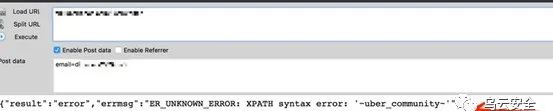
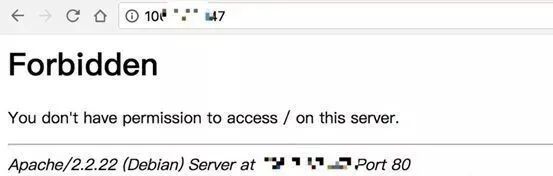
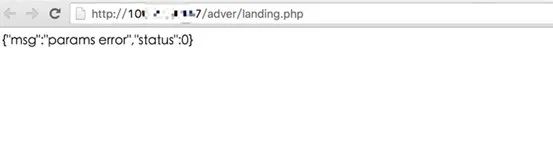
之后,我做了这样一个事情,我下载了1000多个网络上开源的web源码,通过正则提取这些源码的目录结构,可执行脚本文件名,参数名, JS脚本名。收集目录结构是为了爆破目录,收集可执行脚本文件名是为了爆破一些爬虫获取不到的可执行脚本文件,参数名当然也是为了爆破可执行脚本的参数,收集JS脚本名是因为其实我碰到很多站都会把一些重要的API存放在JS文件中,这种针对性的收集,肯定会减少爆破时遗漏的情况。(字典将整理后上传 Blog )
我们可以将字典入库,增加keywordcount字段用于计数,当我们的关键词命中时,对应的keywordcount值加1。每次使用字典时,从数据库中order by keyword_count desc提取关键词,这样会生成一个根据关键词命中次数降序的字典,这样经常命中的关键词就会靠前,我们使用的字典的效率也会提高,循环往复我们的字典将会越加成熟。




 发表于 2021-6-5 09:34:51
发表于 2021-6-5 09:34:51