本帖最后由 CDxiaodong 于 2021-10-19 19:47 编辑
觉得python这方面的技术我十分的欠缺,光看书是不够的,还需要配合动手,不经会吃饭还要会做饭
在网上浏览时我看到了这个网站
专门练习python的解谜网站,听说练完python技术会有质的飞跃。那我就定个目标,在一个工作周内搞定它
配合书的使用
第0题就不用写了,比较简单
0x01

凯撒加密(提示)
写一个代码
```python
text = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp.\n" + \
"bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle.\n" + \
"sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj."
in_table = "abcdefghijklmnopqrstuvwxyz"
out_table = "cdefghijklmnopqrstuvwxyzab"
trans_table = str.maketrans(in_table, out_table)
text = text.translate(trans_table)
print(text)
```

根据凯撒密码把网址后缀列移位两位即可
0x02

源代码找到一些乱码
通过正则表达式查找有效字符
需要用到re库

这样
输出结果equality
0x03
来到第三题

看像是解密
即一个小写字母,其左右各有“恰好”三个大写字母环绕,即寻找形如“AAAaAAA”的字符串
源代码里面有个字符串
即是从这个字符串里面找出类似各个字母‘a’然后拼出来


这样的话找出了这么多字符
原来要寻找形如“AAAaAAA”的字符串,但“AAAAaAAA”和“AAAaAAAA”不满足条件
需要筛选
最终代码如下
```python
data = "\n" + data + "\n"
pattern_0 = r"[A-Z]{3}([a-z])[A-Z]{3}"
pattern_1 = r"[a-z][A-Z]{3}[a-z][A-Z]{3}[a-z]"
pattern_2 = r"[a-z][A-Z]{3}[a-z][A-Z]{3}\n"
pattern_3 = r"\n[A-Z]{3}[a-z][A-Z]{3}[a-z]"
letters_list = re.findall(rf"{pattern_1}|{pattern_2}|{pattern_3}", data)
letters = '\n'.join(letters_list)
letters_list = re.findall(rf"{pattern_0}", letters)
letters = ''.join(letters_list)
print(letters)
```

0x04 网络爬虫
源代码给了提示

本关考察Python的网络爬虫,首先根据提示将“linkedlist.html”改成“linkedlist.php”。网页源代码中提示,以“nothing=12345”为参数构造请求,即图片超链接到的页面,新页面显示“and the next nothing is 44827”。
使用urllib构造爬虫程序


还要再爬一次
```python
from urllib import request
nothing = "12345"
epoch = 0
while True:
epoch += 1
url = f"http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing={nothing}"
response = request.urlopen(url) #网站内容响应包
text = response.read().decode() #对网站的内容进行读写
print(f"{epoch:3}\t{url}\n\t{text}")
nothing = str(text.split(' ')[-1])
```
最后得到peak.html
0x05
Python的pickle模块,根据提示,“peak hell”的发音类似“pickle”,在网页源代码中下载文件“banner.p”,注意要直接“另存为”,不要复制粘贴到文件,否则可能会有问题
使用pickle模块解包


发现是一些表
列表中每行数字之和都是95,结合文件名“banner”,,把表的字符对应的位置用*号打出来打印出一个横幅
```python
import pickle
with open("banner.p", "rb") as file:
data_list = pickle.load(file)
for line_list in data_list:
for item_tuple in line_list:
char, num = item_tuple
print(char * num, end='')
print()
```

得到英文字符channel
0x06
提示我们购物zipfile
修改网页后缀得到zip文件
解压文件后有个提示
hint1: start from 90052
hint2: answer is inside the zip
“根据提示2,答案就在压缩包内,其实是每个文件的注释(comment)
用zipfile模块从“90052.txt”开始遍历,同时保存每个文件的注释,并打印出来

点开这个后缀的网址,得到oxygen
0x07
本题是利用这个PIL库

图片中间有一条灰色的带状区域,类似于条形码,其中隐藏着信息。每一个小块的宽度都是7个像素,每一小块中的所有像素点是同一个颜色,且RGB分量一样,例如第一块的RGBA数据值是(115, 115, 115, 255),115对应的ASCII字符是‘s’。将每一小块的字符拼接起来
```python
from PIL import Image
im = Image.open("oxygen.png")
char_list = []
for width in range(0,629,7): #总共横向有629个像素,用循环来取间隔为7的像素
pixel = im.getpixel((width,im.height / 2)) #将RGBA数值取出且取两次
char = chr(pixel[0]) # #对上述数值定义转成字符
char_list.append(char) #再char表中附加每个循环的char值
print(f"{width:3d}\t{str(pixel):20s}\t{char}")
print(''.join(char_list))
```

得到这些
“/2”代表着运行两次 因为im.getpixel()括号内只能有两个字符值
那为什么那个 pixel要运行两次呢?
这就和RGBA数值以及char的定义有关系了,前三个代表这个颜色的RGB值,
后面的数字代表透明度,范围在0-1之间
如果运行一次的话,没有满足三个值,只有两个值,所以运行两次,但是第四个值再RGBA里面是透明度的意思,这个透明度只在0到1之间,我想可能是因为PIL库对此没有定义,所以都为255
转ascii码 得到 integrity
0x08
需要输入账号密码

这明显就是加密的题目
两个比特流是以“BZ”开头的,这是经bzip2压缩后的数据,直接使用bz2模块解码即可。
```python
import bz2
un = b'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084'
pw = b'BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08'
username = bz2.decompress(un).decode()
password = bz2.decompress(pw).decode()
print(f"username = {username}\npassword = {password}")
```

0x09

本关考察Python的PIL模块,网页源代码中有两组数据,根据提示需要连点成线。这两组数据分别对应两个图形,每组数据表述一系列点的坐标,写得清楚一点就是
first = [(146, 399), (163, 403), (170, 393), ……, (146, 399)]
second = [(156, 141), (165, 135), (169, 131), ……, (156, 136)]

```python
from PIL import Image,ImageDraw
im = Image.new("RGBA",(500,500),"#FFFFFF") #FFFFFF是将底片设置为了白色
draw = ImageDraw.Draw(im)
draw.line(first, fill="#000000") #0000000,即将fill值设置成了黑色
draw.line(second, fill="#000000")
im.save("1.png")
```

得到答案 null牛
0x10

本关主要是解谜,点击图片中的公牛,得到一个序列
a = [1, 11, 21, 1211, 111221, ……
后一个数字是对前一个数字的解释,具体来说就是:
①“1”是初始值;
②“1”有“1个1”,得到“11”;
③“11”有“2个1”,得到“21”;
④“21”有“1个2+1个1”,得到“1211”;
⑤“1211”有“1个1+1个2+2个1”,得到“111221”;
在求出第三十个的长度
```python
pre_string = "1"
for k in range(31):
print(f"{k}\t{len(pre_string):4d}\t{pre_string}")
cnt_string = ""
char = pre_string[0]
pos = 0
for i, c in enumerate(pre_string):
if c == char:
continue
cnt_string += f"{i - pos}{char}"
char = c
pos = i
cnt_string += f"{len(pre_string) - pos}{char}"
pre_string = cnt_string
```

得到5808
0x11

放大图片,可以看到黑色像素和彩色像素是间隔排列的。
对每一行进行操作,有彩色像素移到左边,所有黑色像素移到右边。其实这里说黑色像素并不严谨,因为黑色像素并不都是纯黑的像素。根据标题提示,我们需要根据奇偶性进行操作。设row和column都从0开始,则:
①若(row+column) % 2 == 0,则将该像素移到该行右边;
②若(row+column) % 2 == 1,则将该像素移到该行左边;
```python
import numpy as np
from PIL import Image
im0 = Image.open("cave.jpg")
mat0 = np.asarray(im0) #将结构数据转换为ndarray类型,ndarray是numpy的一种特有数据型,比如矩阵
mat1 = np.zeros_like(mat0) #numpy.zeros_like(a):a是一个ndarray,翻译过来应该数组更容易理解一点吧。生成一个和你所给数组mat0相同shape的全0数组。
for i, row in enumerate(mat0):
j1, j2 = -1, 319
for j, pixel in enumerate(row):
if (i + j) % 2 == 0:
j2 += 1
mat1[j2] = mat0[j] #若(row+column) % 2 == 0,则将该像素移到该行右边
else:
j1 += 1
mat1[j1] = mat0[j] #若(row+column) % 2 == 1,则将该像素移到该行左边
im1 = Image.fromarray(mat1)
im1.save("result.jpg")
```

得到evil
0x12
本关考察对比特流(bit stream)的操作,网页中的图片名是“evil1.jpg”,试图获取“evil2.jpg”、“evil3.jpg”,得到三张图片。
其实还有“evil4.jpg”,不过貌似只能在ie浏览器中打开,是一段文字“Bert is evil! go back!”,后面的关卡中会用到。

根据“evil2.jpg”的提示,尝试获取“evil2.gfx”,得到一个文件。“evil1.jpg”将牌分成5堆,由此得到启发,将文件中的数据分成5份,分别写入5个文件中.最终得到5张图片
```python
with open("evil2.gfx", "rb") as file:
file_bytes = file.read() #读取字节流
for i in range(5):
piece_bytes = file_bytes[i::5] #分割字节流
with open(f"{i}.jpeg", "wb") as file: #循环通过字节流粗存并将其转换成jepg文件
file.write(piece_bytes)
```

得到disproportional
0x13
点击电话上的5调转到php界面,感觉在提示我们用php魔法字符

根据提示“phone that evil”,我们使用RPC(Remote Procedure Call,远程过程调用),那这个phone就可能是pp字符。尝试调用phone()方法,记得上一关说“Bert is evil! go back!”,所以这个evil应该就是Bert
```python
from xmlrpc.client import ServerProxy
server = ServerProxy("http://www.pythonchallenge.com/pc/phonebook.php")
response = server.phone("Bert")
print(response)
```
得到

答案就是“italy”。
0x14
打开是个甜甜圈,下面是个多色条纹

这些是提示
Python的PIL模块,需要一点简单的算法。标题、图片、公式都提示,需要将下面的带状图案绕成一张图片,进一步根据公式的提示,绕成的图片尺寸是100*100,要从外向里绕,这里需要生成“螺旋矩阵”的算法。
```python
def next_pos(x,y,f):
if f == 0:
if y!= 99 and mat1[x][y + 1] == 0:
y+=1
else:
x,f = x+1,1
elif f == 1:
if x != 99 and mat1[x+1][y] == 0:
x += 1
else:
y,f = y-1,2
elif f == 2:
if y != 0 and mat1[x][y-1] == 0:
x -= 1
else:
y,f = y+1 ,0
mat1[x][y] = 1
return x,y,f
print(f"\033[31mLevel 14\033[0m")
import numpy as np
from PIL import Image
im0 = Image.open("wire.png")
im1 = Image.new("RGB", (100, 100), "#FFFFFF")
mat1 = np.zeros((100, 100), dtype=np.int) #zeros(shape, dtype=float, order='C')返回:返回来一个给定形状和类型的用0填充的数组;参数:shape:形状dtype:数据类型,可选参数,默认numpy.float6
i, j, d = 0, -1, 0
for k in range(10000):
i, j, d = next_pos(i, j, d)
pixel = im0.getpixel((k, 0)) #getpixel该函数检索指定坐标点的像素的RGB颜色值
im1.putpixel((i, j), pixel)
im1 = im1.rotate(-90) #rotate旋转函数
im1.save("result.png")
```

得到一只

得到cat。进去之后是uzi
0x15

题目是找个人
本关考察Python的datetime模块和calendar模块,考察对日期和时间的处理。要找一个年份,以1开头以6结尾,即形如“1XY6”的年份,且1月1日是星期四,仔细观察发现2月有29日,说明这是一个闰年。
```python
import calendar
from datetime import date
d = date(1006,1,1)
while d.year < 2000:
if d.isoweekday() == 4 and calendar.isleap(d.year): #1月1日是星期四且是闰年。
print(d.isoformat())
d=d.replace(year=d.year +10)
```
说明这是一个闰年。最终符合条件的年份共有5个,又根据提示“he ain’t the youngest, he is the second”,他是第二年轻的,说明是1756年,“buy flowers for tomorrow”意味着是圈出来日期的第二天,即1756年01月27日
搜索一下
mozart
0x16
这一关又是考察对于图片的处理,可以验证每一行都有一个粉色的小条(5个粉色像素两边各有1个白色像素),标题提示需要将它们拉直,要把每一行的粉色小条向左拉到同一个位置,这里我们统一把粉色小条拉到开头处。
```python
from PIL import Image
im0 = Image.open("mozart.gif")
im1 = Image.new("P", (640, 480))
im1.putpalette(im0.getpalette())
for h in range(480):
for w in range(4, 640): #一个粉色条有四个像素点
p1 = im0.getpixel((w - 4, h))
p2 = im0.getpixel((w - 3, h))
p3 = im0.getpixel((w - 2, h))
p4 = im0.getpixel((w - 1, h))
p5 = im0.getpixel((w, h))
if p1 == p2 == p3 == p4 == p5 == 195: #195为粉色
for ww in range(640):
pixel = im0.getpixel(((ww + w - 4) % 640, h))
im1.putpixel((ww, h), pixel)
break
im1.save("result.gif"
```

0x17 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211013183942042.png?lastModify=1634643505 本关考察爬虫、bz2、RPC的综合运用,其实把之前几关的代码改改再组合一下就行了。 首先是爬虫部分,图片上是小饼干(cookies),cookies又指存在客户端上的数据,查看cookies发现确实有这么一条{name = “info”, value = “you+should+have+followed+busynothing…”} file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211013193929559.png?lastModify=1634643505 经过118轮循环后结束,将每次请求的“info”信息拼接起来,得到一条字节流数据。 其次是bz2解码部分,直接用bz2模块解码即可,可复用第8关的代码。得到一个字符串“is it the 26th already? call his father and inform him that “the flowers are on their way”. he’ll understand.”。 最后是RPC,这句话中“call his father”是切入点,莫扎特的父亲是列奥波尔得·莫扎特(Leopold Mozart),复用第13关代码,尝试RPC调用phone(“Leopold”),得到相应信息“555-VIOLIN”,答案是“violin”。 访问“violin.html”,但提示跳转到“http://www.pythonchallenge.com/pc/stuff/violin.php”,但并没有进一步的信息,看看解码得到的那句话,再看看网页标题,这里需要带着{name = “info”, value = “the flowers are on their way”}这条cookies一并访问服务器,可以直接在Chrome里面手动添加这条cookies。再次访问发现人像下面多了一句话“oh well, don’t you dare to forget the balloons.”,最终答案是“balloons”,注意是“…/pc/return/balloons.html”,而不是“…/pc/stuff/balloons.html”。 from urllib import request, parse
from http import cookiejar
from xmlrpc.client import ServerProxy
import bz2
def crawl():
epochs = 0
busynothing = "12345"
info = ""
while str.isdigit(busynothing):
epochs += 1
url = f"http://www.pythonchallenge.com/pc/def/linkedlist.php?busynothing={busynothing}"
cookie = cookiejar.MozillaCookieJar()
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
response = opener.open(url)
text = response.read().decode()
print(f"{epochs:<3d}\tbusynothing = {busynothing}\n\t{text}")
for c in cookie:
print(f"\t{c.name} = {c.value}")
if c.name == "info":
info += c.value
busynothing = str(text.split(' ')[-1])
print(info.encode())
def decompress():
info = "BZh91AY%26SY%94%3A%E2I%00%00%21%19%80P%81%11%00%AFg%9E%A0+%00hE%3DM%B5%23%D0%D4%D1%E2%8D%06%A9%FA" + \
"%26S%D4%D3%21%A1%EAi7h%9B%9A%2B%BF%60%22%C5WX%E1%ADL%80%E8V%3C%C6%A8%DBH%2632%18%A8x%01%08%21%8DS" + \
"%0B%C8%AF%96KO%CA2%B0%F1%BD%1Du%A0%86%05%92s%B0%92%C4Bc%F1w%24S%85%09%09C%AE%24%90"
info = info.replace("+", "%20")
info = parse.unquote_to_bytes(info)
info = bz2.decompress(info).decode()
print(info)
def phone():
server = ServerProxy("http://www.pythonchallenge.com/pc/phonebook.php")
response = server.phone("Leopold")
print(response)
0x18 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211013195511154.png?lastModify=1634643505 本关也要分步解谜,首先标题问你有什么区别,提示说这很明显,不要想复杂了,这两张图片的区别明显是亮度,答案就是“brightness”,如果输入“bright”会提示你加上“ness”。 访问“brightness.html”,但页面貌似一模一样,但网页源代码中的注释不一样了, file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211013195610959.png?lastModify=1634643505提示下载文件“deltas.gz”。查看字节流数据,发现数据分成了左右两块,大体一样但又略有不同。 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211013195809375.png?lastModify=1634643505 接下来考察Python的difflib模块,difflib模块可以比较两组数据d1和d2的差异,“-”表示d1有但d2没有,“+”表示d1没有但d2有,“ ”表示d1和d2内容一致。根据每行以哪种符号开头,由此可以把数据分成三类,分别存入三个文件中 import gzip
import difflib
from PIL import Image
from io import BytesIO
data1_list,data2_list = [], []
with gzip.open ("deltas.gz","rb") as file: #rb是读取二进制文件
for data in file:
data = data.decode("utf-8")
data1, data2 = data[:53].rstrip(' ') + "\n", data[56:]
if data1 != "\n":
data1_list.append(data1) #先把双方非空格的都取出来用于之后的比较
if data2 != "\n":
data2_list.append(data2)
d = difflib.Differ()
diff = d.compare(data1_list,data2_list) #提取不同的用于之后的筛选
print(''.join(list(diff)))
space_bytes, plus_bytes, minus_bytes = b"", b"", b""
for data in diff:
data_list = data[2:].strip('\n').split(' ')
byte=bytes([int(i, 16) for i in data_list]) #把list里面的i切换到16进制,以便于之后的筛选
if data[0] == '+':
plus_bytes += byte
elif data[0] == '-':
minus_bytes += bytes
elif data[0] == ' ':
space_bytes += byte #分别取出三种数据
#下面将各个数据转换成图片
stream = BytesIO(space_bytes)
image_space = Image.open(stream)
image_space.save("space.png")
stream = BytesIO(plus_bytes)
image_space = Image.open(stream)
image_space.save("plus.png")
stream = BytesIO(minus_bytes)
image_space = Image.open(stream)
image_space.save("minus.png")file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211013202459806.png?lastModify=1634643505 打开得到这三个 “ ”行组成的图片是下一关的网址,“+”行组成的图片是用户名,“-”行组成的图片是密码。 0x19(做的复现给删了,复制了一下网上的) file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015193115233.png?lastModify=1634643505 本关考察Python的base64模块和wave模块。网页源代码中有一堆编码,二话不说先保存下来,提示说是base64编码的,直接用base64模块解码,得到的数据写入文件,再根据提示修改文件名为“indian.wav”,以音频方式打开,听到一声“Sorry”和一堆杂音。 观察图片,图片上大陆和海洋的颜色颠倒了,启发需要反转文件数据。具体做法是反转每一帧内的字节流数据,得到新的音频文件,听到“You are the idiot……hhhhhhhhhhhh……”,答案就是“idiot”(笨蛋,哈哈哈哈哈哈)。 “idiot.html”出现一个中间页面,显示“Now you should apologize…”,直接点击进入下一关。 def level_19() -> None:
print(f"\033[31mLevel 19\033[0m")
import base64
import wave
with open("level_19/indian.txt", "r") as file:
text = file.read().replace("\n", "")
stream = base64.b64decode(text.encode())
with open("level_19/indian.wav", "wb") as file:
file.write(stream)
with wave.open("level_19/indian.wav", "rb") as f1:
with wave.open("level_19/reverse.wav", "wb") as f2:
f2.setparams(f1.getparams())
for _ in range(f1.getnframes()):
f2.writeframes(f1.readframes(1)[::-1])
0x20 这关也是 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015193315903.png?lastModify=1634643505 本关考察高级的网络爬虫技能,查看图片的响应头参数,发现图片采用了“断点续传”技术,并没有把全部数据传回来,以此为切入口解谜。本关爬虫需要进行身份验证,需要同时向服务器提交用户名和密码。 先从头开始爬取,得到的信息都是“入侵者……停止……尊重我的隐私”之类的,发现“invader.html”是存在的,就只有一句话“Yes! that’s you!”,但并没有实际意义。 从头开始不行,就从最后开始爬取,得到两条有用信息。第一条提示说“密码是新昵称反过来”,即invader反过来“redavni”就是密码。第二条提示说“它藏在1152983631处”,爬取这个位置发现是一个“PK”开头的字节流,这明显是一个压缩文件,写入文件“invader.zip”。解压发现需要密码,密码就是“redavni”,解压得到两个文件,阅读“readme.txt”文件,我们已经进入第21关了,过关! file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015193415561.png?lastModify=1634643505 from urllib import request, error
url = "http://www.pythonchallenge.com/pc/hex/unreal.jpg"
user = "butter"
password = "fly"
password_mgr = request.HTTPPasswordMgrWithDefaultRealm()
password_mgr.add_password(None, url, user, password)
handler = request.HTTPBasicAuthHandler(password_mgr)
opener = request.build_opener(handler)
start = -1
# start = 2123456790
# start = 1152983632
for _ in range(100):
start += 1 # this is for start = -1
# start -= 1 # this is for start = 2123456790 and start = 1152983632
print(f"{start}", end="\t")
opener.addheaders = [("range", f"bytes={start}-"), ]
try:
response = opener.open(url)
except error.HTTPError:
print("HTTP Error 416")
else:
data = response.read()
headers = dict(response.info())
content_range = str(headers['Content-Range'])
print(f"\033[31m{content_range}\t{data}\033[0m")
start = int(content_range.split('-')[1].split('/')[0]) # this is for start = -1
# start = int(content_range.split(' ')[1].split('-')[0]) # this is for start = 2123456790 and start = 1152983632
with open("level_20/invader.zip", "wb") as file:
opener.addheaders = [("range", f"bytes=1152983631-"), ]
response = opener.open(url)
data = response.read()
file.write(data)0x21 本关考察多种编码格式的运用,观察“package.pack”中的数据,发现是以b"x\x9c"开头的,这是zlib算法压缩的数据,使用zlib模块解码。重复几次,发现有以b"BZ"开头的,这是bz2压缩的数据,使用bz2模块解码。又重复几次,发现有以b"\x80\x8d"开头的,看看第2条提示,发现字节流是以b"\x9cx"结尾的,反转整个字节流。最终得到一句话“look at your logs”。 打印解压日志,若以bz2解压则打印“B”,若以zlib解压则打印空格,若反转操作则打印换行符,最终得到一幅像素画,答案是“copper”。 $$
$$
import bz2
import zlib
with open("level_21/package.pack", "rb") as file:
data = file.read()
while data != b"sgol ruoy ta kool":
if data.startswith(b"x\x9c"):
data = zlib.decompress(data)
print(' ', end='')
elif data.startswith(b"BZ"):
data = bz2.decompress(data)
print('B', end='')
elif data.endswith(b"\x9cx"):
data = data[::-1]
print()
print()
print(data[::-1])file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015195023722.png?lastModify=1634643505 0x22 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015195116414.png?lastModify=1634643505 源码提示有个gif且要是gif更亮一点 根据提示下载文件“white.gif”。发现每一帧都是黑的,但每一帧都有一个像素点不是纯黑的 RGB != (0,0,0),且该像素都在中心点(100,100)附近,再由游戏摇杆得到启发。举例来说,详见下表 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015200543011.png?lastModify=1634643505 把两次归零操作之间,每一帧的实际位置都画出来,就能得到一幅图案 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015203843699.png?lastModify=1634643505 最终发现一共有5幅图案,按顺序绘制出来,发现是一个单词“bonus”。 from PIL import Image, ImageSequence
im0 = Image.open("white.gif")
im1 = Image.new("1",(400,100))
index = 1
x, y = 50, 50
for frame in ImageSequence.Iterator(im0):
i,j = 98, 98
while i <= 102:
if frame.getpixel((i, j)) != 0:
break
if j == 102:
i, j = i+1, 98
else:
j += 1
dx, dy = i - 100, j - 100
if dx == dy == 0: #把归零之间的实际位置选取出来
index += 1
x, y = index * 50, 50 #x,y变成100,是为了定义(100,100)这样的归零点
else:
x, y = x + dx, y + dy #白像素点转换到实际位置
im1.putpixel((x, y), 1)
im1.save("result.png")
0x23
打开题目是张牛 源代码有各种提示,还包括凯撒密码 本关考察对“Python之禅”的了解,“你是否欠某人一个道歉,如果是,真诚地去表达歉意吧!”这是作者的呼吁,和本关解谜没有任何关系。 网页源代码最后有一行看不懂的话“va gur snpr bs jung?”,又是凯撒密码,但偏移量未知,复用第1关的代码,尝试所有26种偏移量,肉眼观察有没有能构成英语单词的,发现真有一句是合理的,“in the face of what?”。这是提问“Python之禅”里面的内容 “Python之禅”直接使用语句“import this”就能打印出来了 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211015204803385.png?lastModify=1634643505 其中有一句是“In the face of ambiguity, refuse the temptation to guess.”。所以答案是“ambiguity”。
0x24 本关考察高级的图片处理能力,且需要一定的算法和数据结构基础。图片明显是一个迷宫,要从右上角走到左下角,这里采用BFS(广度优先搜索)算法,得到一条路径,可以验证这也是唯一路径。但这还不够,因为路径并没有明显刻画出某个单词或图案。 仔细观察每个像素,发现除了白色像素和左上角的那个灰色区域外,每个深色像素的R通道分量都不同,但G和B通道分量都恒为0,这意味着R通道分量上蕴含着信息。将路径上每个像素点的R通道分量值都保存下来,转成字节流数据并存入文件 发现该字节流以b"PK"开头,说明这是一个压缩文件。解压得到一个压缩包“mybroken.zip”,这是后面关卡要用的,还有一张图片“maze.jpg”,图片上面写着“lake”,故答案就是“lake”。 import numpy as np
from PIL import Image
im0 = Image.open("maze.png")
rgba_array = np.asarray(im0, dtype=np.uint8).copy() #先转成矩阵格式,然后若想为图像创建一个容器,需要指定dtype=np.uint8,否则虽然你的容器矩阵中是有值的,但是无法正常imshow,还有就是uint8是专门用于存储各种图像的
im0 = im0.convert(mode="1") #PIL库将其转化为mode1 二值图像,非黑即白。但是它每个像素用8个bit表示,0表示黑,255表示白
maze_array = np.asarray(im0, dtype=np.uint8).copy()
maze_array = 1 - maze_array
n, m = maze_array.shape #迷宫矩阵形状转成n,m
queue_list = [(0, m - 2)]
path_array = np.zeros((n, m, 2), dtype = np.int) #zero返回来一个给定形状和类型的用0填充的数组;zeros(shape, dtype=float, order=‘C’)
dx_tuple, dy_tuple = (0, 0, 1, -1), (1, -1, 0, 0)
while queue_list:
x, y = queue_list.pop(0) #pop() 函数用于移除列表中的一个元素(默认最后一个元素),这里即是删除第一个元素
maze_array[x,y] = 0
if x == n - 1:
break
for dx, dy in zip(dx_tuple, dy_tuple): #将字节流转换为压缩包的数据格式
xx, yy = x + dx, y +dy
if 0 <= xx < n and 0 <= yy <m and maze_array[xx, yy]:
maze_array[xx, yy] = False
path_array[xx, yy] = [x, y]
queue_list.append((xx,yy))
im1 = Image.new(mode="1", size=(n, m), color = 1)
r_list = []
x, y = n - 1, 1
while x != 0 or y != 0:
im1.putpixel((x, y), 0)
r_list.append(rgba_array[x, y, 0])
im1.save("path.png")
r_list = r_list[-2 :: -2]
r_bytes = bytes(r_list)
with open("red.rar","wb") as file:
file.wirte(r_bytes)file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016102804498.png?lastModify=1634643505
0x25 本关考察网络爬虫和对图片字节流的处理,看到图片名是“lake1.jpg”,根据提示尝试获取“lake1.wav”,文件存在,猜测应该还有“lake2.wav”,“lake3.wav”,……于是构造一个网络爬虫,复用第20关的代码即可 from urllib import request, error
import wave
from PIL import Image
password_mgr = request.HTTPPasswordMgrWithDefaultRealm()
password_mgr.add_password(None, "http://www.pythonchallenge.com/", "butter", "fly")
handler = request.HTTPBasicAuthHandler(password_mgr)
opener = request.build_opener(handler)
for i in range(1, 30):
print(f"Processing {i:2d}...", end='\t')
url = f"http://www.pythonchallenge.com/pc/hex/lake{i}.wav"
try:
response = opener.open(url)
except error.HTTPError:
print("HTTP ERROR 404")
else:
with open(f"25/lake{i}.wav", "wb") as file: #用保存来判断是否有这个网站文件
data = response.read()
file.write(data)
print("Successfully Saved.")file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016104245243.png?lastModify=1634643505 发现一共有25个文件,从“lake1.wav”到““lake25.wav””。 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016104329410.png?lastModify=1634643505 以音频方式打开文件,发现都是杂音,根据图片中拼图的提示,尝试把这25个文件拼接起来,得到一个合成文件。尝试不同打开方式后, from urllib import request, error
import wave
from PIL import Image
im = Image.new("RGB",(300, 300))
for i in range(1, 26):
with wave.open(f"25/lake{i}.wav","rb") as file:
data = file.readframes(file.getnframes()) #readframs是属于wave的函数。以字符串格式读取音频
block_im = Image.frombytes("RGB", (60,60), data) #定义block这样一个框架来填入xy从而产生RGB像素
x, y = (i - 1) %5 *60, (i - 1) //5 * 60
im.paste(block_im, (x,y))
im.save("25/result.jpg")得到图片 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016105937650.png?lastModify=1634643505 发现其实是一张图片,上面有一个单词,很模糊,但还是能辨认出来是“decent”。 0x26 回复中提到第24关中那个破损的压缩包“mybroken.zip”,告诉我们只有一个错误,即某个字节的数据出错了,导致压缩包破损,同时还告诉了我们文件的md5码。这下问题就简单了,遍历文件的每一个字节,对于每一个字节,尝试0-255的所有可能取值,每次都重新计算md5码,直到和正确的md5码一致为止。 得到正确的压缩包,解压得到一张图片,图片上写着一个单词“speed”。但这还不是最终答案,网页上写着一句话“Hurry up, I’m missing the boat”,是的,还要加上“boat”,所以最终答案是“speedboat”。 import hashlib
with open("level_26/mybroken.zip", "rb") as file:
broken_data = file.read()
correct_digest = "bbb8b499a0eef99b52c7f13f4e78c24b"
for pos in range(len(broken_data)):
print(f"Trying position {pos} ...")
for k in range(256):
data = broken_data[:pos] + bytes([k]) + broken_data[pos + 1:]
digest = hashlib.md5(data).hexdigest()
if digest == correct_digest:
print(f"Successfully insert {k} at position {pos}")
with open("level_26/mycorrect.zip", "wb") as file:
file.write(data)
return0x27 本关也是考察对图片和编码的处理能力,此外还有keyword模块。图片直接超链接到了下一关“…/ring/bell.html”,但需要身份验证,我们需要找到用户名和密码。 根据提示下载文件“zigzag.gif”,图片名“zigzag”和标题“between the tables”都提示需要建立一个映射表,具体做法是建立一个“自增索引”到“颜色表(palette)”的映射表,映射表的前几位展示如下 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016112853737.png?lastModify=1634643505 将映射表作用到图片的字节流数据“data”上,得到一个新的字节流数据“new_data” 这些就是数据流(包括旧的和新的) file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016140149309.png?lastModify=1634643505 from PIL import Image
import bz2
import keyword
im0 = Image.open("zigzag.gif")
palette = im0.getpalette()[::3] #Image.getpalette()以列表形式返回图像调色板。 换成数组是为了针对gif图像
data = im0.tobytes()
palette_bytes = bytes(palette)
index_bytes = bytes([i for i in range(256)]) #bytes() 函数返回字节对象。
trans = bytes.maketrans(index_bytes, palette_bytes)#maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。,就是说256种字符全都要转换程byetes
new_data = data.translate(trans) #再把bytes转换成data
print(data)
print(new_data)file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016140759976.png?lastModify=1634643505 对比发现两个字数差不多 但有一些字符还是不一致的。将data中和new_data不一致的字符过滤出来 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016160638795.png?lastModify=1634643505 发现有bz的字节符 那就用bz2去解码 diff_bytes = b''.join([bytes([b1]) if b1 != b2 else b'' for b1, b2 in zip(data[1:], new_data[:-1])])
#diff_bytes为字符筛选函数,这里就是将得到的data里面的b‘’俩米娜的对比筛选出来,s[:-1] # 等价于 s[0:len(s)],除了最后一个元素的切片,将最后一个元素去掉
file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016162929357.png?lastModify=1634643505
果然有很多英文字符,但是也有很多python关键字 (比如英语中间那些/bing) 以及很多英文字符是重复的 用keyword模块过滤掉这些关键字,并用set过滤掉重复单词,留下的内容就所剩无几了。 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211016170140635.png?lastModify=1634643505 得到这个 值得注意的是,“print”和“exec”在Python2中式关键字,在Python3中变成了函数,所以没有被去掉,还有一个链接“…/ring/bell.html”指向下一关,其实就是网页上那张图片的超链接。最后剩下两个单词“repeat”和“switch”,就是用户名和密码了。尝试发现用户名是“repeat”,密码是“switch”。 完整代码如下 from PIL import Image
import bz2
import keyword
im0 = Image.open("zigzag.gif")
palette = im0.getpalette()[::3] #Image.getpalette()以列表形式返回图像调色板。 换成数组是为了针对gif图像
data = im0.tobytes()
palette_bytes = bytes(palette)
index_bytes = bytes([i for i in range(256)]) #bytes() 函数返回字节对象。
trans = bytes.maketrans(index_bytes, palette_bytes)#maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。,就是说256种字符全都要转换程byetes
new_data = data.translate(trans) #再把bytes转换成data
print(data)
print(new_data)
diff_bytes = b''.join([bytes([b1]) if b1 != b2 else b'' for b1, b2 in zip(data[1:], new_data[:-1])])
#diff_bytes为字符筛选函数,这里就是将得到的data里面的b‘’俩米娜的对比筛选出来,s[:-1] # 等价于 s[0:len(s)],除了最后一个元素的切片,将最后一个元素去掉
text = bz2.decompress(diff_bytes).decode()
content = set(s if not keyword.iskeyword(s) else'' for s in text.split(' ') ) #split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串. 再将区分好的每个块值遍历循环是否属于python的字符
print(content)
0x28 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017170107195.png?lastModify=1634643505
本关考察对图片和字节流的处理能力。提示让我们大声说“RING-RING-RING”,是指“RING”谐音“GREEN”,就是指RGB的绿色通道。我们需要将绿色通道的数据两两配对,每组作差取绝对值 from PIL import Image
im = Image.open("bell.png")
green = list(im.split()[1].getdata())
diff = [abs(p1 - p2) for p1, p2 in zip(green[0::2], green[1::2])]
print(diff)file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017172046552.png?lastModify=1634643505发现全都是42。不过有一些不是 把他们提取出来 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017172958191.png?lastModify=1634643505 得到这些值 盲猜需要转换成acii码 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017173228413.png?lastModify=1634643505 diff_filter = list(filter(lambda x: x!=42,diff)) #fiter是过滤函数,用于过滤掉不符合条件的函数,lambda函数冲diff中取出x!=42的数,
text = bytes(diff_filter).decode()
print(text)翻译出来是谁是真凶 查了一查 发现是python之父guido 完整代码如下 from PIL import Image
im = Image.open("bell.png")
green = list(im.split()[1].getdata())
diff = [abs(p1 - p2) for p1, p2 in zip(green[0::2], green[1::2])]
diff_filter = list(filter(lambda x: x!=42,diff)) #fiter是过滤函数,用于过滤掉不符合条件的函数,lambda函数冲diff中取出x!=42的数,
text = bytes(diff_filter).decode()
print(text)
0x29 提示whoisit file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017173700575.png?lastModify=1634643505 源代码发现有很多空格且空格数都不一样 将空格取下来 本关考察bz2编码,经过前面那么多的训练,这关可以说是小case 了!注意到网页源代码后面有很多空行,ctrl+A一下,发现每行空格的数量都不一样,这里面肯定隐藏了信息。获取每行的空格数量 data = “复制下来的那些空格”
space_list = data.split('\n')
count_list = [len(line) for line in space_list]
print(count_list)file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017174500845.png?lastModify=1634643505 每个数值表示一字节的数据,因为用的是bz2编码。得用到bz模块的字节数据转换 不能直接用bytes.decode进行解码 需要先把它转换到bytes space_list = data.split('\n')
count_list = [len(line) for line in space_list]
count_byte = bytes(count_list)
print(count_byte)file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017175109374.png?lastModify=1634643505 在进行bz模块进行解码 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017175204283.png?lastModify=1634643505 得到这个 下一题就是yankeedoodle 完整代码如下 import bz2
data = """
"""
space_list = data.split('\n')
count_list = [len(line) for line in space_list]
count_byte = bytes(count_list)
text = bz2.decompress(count_byte).decode()
print(text)
0x30 提示下载csv格式文件 什么是csv格式文件? 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常都是纯文本文件。建议使用WORDPAD或是记事本来开启,再则先另存新档后用EXCEL开启,也是方法之一。 打开内容如下,并发现有7367个数 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017180149816.png?lastModify=1634643505 7367 = 139*53 这两个质数,依此将转换成图片试试 import re
import numpy as np
from PIL import Image
with open("yankeedoodle.csv", "r") as file:
data = file.read()
data = re.findall(r"(0.\d*)", data) #re.findall正则表达式函数,用正则将0.后面的字符取出来\d+:一个或多个数字。\d*:0个或多个数字。
img_data = np.array(data, dtype=np.float64).reshape(139, 53) #顾名思义,先将数据转换为float浮点数值,再根据139和53进行矩阵reshape
im = Image.fromarray(256 * img_data) #fromarray的作用就是实现array到image的转换
im = im.rotate(-90, expand=True).transpose(Image.FLIP_LEFT_RIGHT).convert(mode="L")
#给它转个-90°然后.transpose()函数的作用就是调换数组的行列值的索引值(Image.FLIP_LEFT_RIGHT)Image.FLIP_LEFT_RIGHT即为左右镜像翻转
#mode = ‘L’ 代码展示为灰度图像
im.save("formula.png")file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017184443477.png?lastModify=1634643505 得到一个运算表达式 n = str(x)[5] + str(x[i+1])[5] + str(x[i+2])[6] file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017184858118.png?lastModify=1634643505
算是这样的 以字符串类型读取数据,每三个一组,每组有三个字符串,取第一个字符串的第5位,第二个字符串的第5位,第三个字符串的第6位,三个字符构成一个数值,转成一个字符。这样,我们得到了一段话 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211017185144865.png?lastModify=1634643505 得到答案grandpa 完整代码如下 import re
import numpy as np
from PIL import Image
with open("yankeedoodle.csv", "r") as file:
data = file.read()
data = re.findall(r"(0.\d*)", data) #re.findall正则表达式函数,用正则将0.后面的字符取出来\d+:一个或多个数字。\d*:0个或多个数字。
img_data = np.array(data, dtype=np.float64).reshape(139, 53) #顾名思义,先将数据转换为float浮点数值,再根据139和53进行矩阵reshape
im = Image.fromarray(256 * img_data) #fromarray的作用就是实现array到image的转换
im = im.rotate(-90, expand=True).transpose(Image.FLIP_LEFT_RIGHT).convert(mode="L")
#给它转个-90°然后.transpose()函数的作用就是调换数组的行列值的索引值(Image.FLIP_LEFT_RIGHT)Image.FLIP_LEFT_RIGHT即为左右镜像翻转
#mode = ‘L’ 代码展示为灰度图像
im.save("formula.png")
info_list = [int(x1[5] + x2[5] + x3[6]) for x1, x2, x3 in zip(data[::3], data[1::3], data[2::3])]
info = bytes(info_list).decode()
print(info)
0x31 首先,图片超链接到下一关,但又需要用户名和密码,并且提示用户名是“island”,密码是“country”,所以我们要知道这块石头在哪儿,搜索这张图片,知道这是“泰国苏梅岛祖父祖母石”。(Grandfather’s Grandmother’s Rocks - Hin Ta Hin Yai, Koh Samui Island, Thailand)所以用户名是“kohsamui”,密码是“thailand”,进入第二部分。 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211018170542708.png?lastModify=1634643505 提示这个 看着像雪花一样,这就是著名的曼德勃罗集 left=“0.34” top=“0.57” width=“0.036” height=“0.027”w = 640px —— x轴 范围 [left, left+width] = [0.34, 0.376]h = 480px —— y轴 范围 [top, top+height] = [0.57, 0.597]
对于每一个像素点 p = ( w , h ) p=(w,h) p=(w,h),由比例关系计算出其在复平面上的坐标 ( x , y ) (x,y) (x,y),记复数 c = x + y i c=x+yi c=x+yi,从 z 0 = 0 z_{0}=0 $$
z 0 =0
$$
开始迭代,迭代公式为 $$
z i+1 =z i2 +c,where z 0 =0, c=x+yi
$$
记曼德勃罗集为M MM,根据定理,若复数c∈M,则 $$
∣ z i ∣ < 2 , ∀ i ∈ N |z_{i}|<2,\ \forall i\in \mathbb{N} ∣z i ∣<2, ∀i∈N。————————————————版权声明:本文为CSDN博主「BigFatFatBrown」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/enderman19980125/article/details/102529120
$$
迭代次数由option标签给出,最多128次,若迭代完128次,其模仍小于2,则该点的颜色值为127,若 $$
∣ z i ∣ < 2 b u t ∣ z i + 1 ∣ ≥ 2 |z_{i}|<2 \ but \ |z_{i+1}|\geq 2 ∣z i ∣<2 but ∣z i+1 ∣≥2————————————————版权声明:本文为CSDN博主「BigFatFatBrown」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/enderman19980125/article/details/102529120
$$
则该点的颜色值为 i i i。其实原图片有palette颜色表,所以颜色值其实是颜色表的索引,并不是真实的颜色值。 这样,我们绘制了一幅和网页图片看起来一模一样的图片。对,这只是看起来一模一样,实际上有些许像素点的值是不同的,将这些不同的像素点提取出来。形式化地,记p0表示网页图片上的某一像素点,p1表示生成图片上对应位置的像素点,则 若p0 == p1,则跳过;
若p0 > p1,则将0(代表黑色)添加进列表;
若p0 < p1,则将255(代表白色)添加进列表;from PIL import Image
left, top, width, height = 0.34, 0.57, 0.036, 0.027
im0 = Image.open("mandelbrot.gif")
im1 = Image.new("P",(640, 480))
im1.putpalette(im0.getpalette()) #调用调色板
for w in range(640):
for h in range(480):
z = complex(0, 0) #complex() 函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
c = complex(left + w * width / 640 ,top +(479 - h) * height / 480)
for i in range(1, 128):
z = z*z + c
if abs(z) > 2:
im1.putpixel((w, h), i - 1)
break
else:
im1.putpixel((w, h), 127)
im1.save("result.png")得到这个 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211018204551538.png?lastModify=1634643505 不一样的像素点输出成列表 data0, data1 = list(im0.getdata()), list(im1.getdata())
diff = [255 * (p0 < p1) for p0, p1 in zip(data0, data1) if p0 != p1]
print(diff)file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211018205307687.png?lastModify=1634643505 我们得到一个长度为1679的列表,而1679正好可以分解成两个质数的乘积,1679 = 23*73,这显然又是一张图片。 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211018205418780.png?lastModify=1634643505 打开这张图片,感觉像某种神秘的符号,搜索后得知这是“阿雷西博信息”(Arecibo Message)。是于1974年,为庆祝 Arecibo 射电望远镜完成改建,而创作的无线电信息,并以距离地球25,000光年的球状星团M13为目标,把信息透过该望远镜射向太空。最终答案“arecibo ”。完整代码如下: from PIL import Image
left, top, width, height = 0.34, 0.57, 0.036, 0.027
im0 = Image.open("mandelbrot.gif")
im1 = Image.new("P",(640, 480))
im1.putpalette(im0.getpalette()) #调用调色板
for w in range(640):
for h in range(480):
z = complex(0, 0) #complex() 函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
c = complex(left + w * width / 640 ,top +(479 - h) * height / 480)
for i in range(1, 128):
z = z*z + c
if abs(z) > 2:
im1.putpixel((w, h), i - 1)
break
else:
im1.putpixel((w, h), 127)
im1.save("result.gif")
data0, data1 = list(im0.getdata()), list(im1.getdata())
diff = [255 * (p0 < p1) for p0, p1 in zip(data0, data1) if p0 != p1]
im2 = Image.new("L", (23, 73))
im2.putdata(diff)
im2.save("result223.jpg")
0x32 提示下载文件“warmup.txt” 根据“warmup.txt”中的数据绘制出一个“向上箭头”的图案,答案是“up”;跳转到新的up.txt文件 挺难的 考虑到数据结构和算法 下面是大佬的脚本 def level_32() -> None: print(f"\033[31mLevel 32\033[0m") import numpy as np from PIL import Image is_solved = False
ans_points = np.zeros(1)
n = 9
horizontal = [[2, 1, 2], [1, 3, 1], [5], [7], [9], [3], [2, 3, 2], [2, 3, 2], [2, 3, 2]]
vertical = [[2, 1, 3], [1, 2, 3], [3], [8], [9], [8], [3], [1, 2, 3], [2, 1, 3]]
n = 32
horizontal = [[3, 2], [8], [10], [3, 1, 1],
[5, 2, 1], [5, 2, 1], [4, 1, 1], [15],
[19], [6, 14], [6, 1, 12], [6, 1, 10],
[7, 2, 1, 8], [6, 1, 1, 2, 1, 1, 1, 1], [5, 1, 4, 1], [5, 4, 1, 4, 1, 1, 1],
[5, 1, 1, 8], [5, 2, 1, 8], [6, 1, 2, 1, 3], [6, 3, 2, 1],
[6, 1, 5], [1, 6, 3], [2, 7, 2], [3, 3, 10, 4],
[9, 12, 1], [22, 1], [21, 4], [1, 17, 1],
[2, 8, 5, 1], [2, 2, 4], [5, 2, 1, 1], [5]]
vertical = [[5], [5], [5], [3, 1],
[3, 1], [5], [5], [6],
[5, 6], [9, 5], [11, 5, 1], [13, 6, 1],
[14, 6, 1], [7, 12, 1], [6, 1, 11, 1], [3, 1, 1, 1, 9, 1],
[3, 4, 10], [8, 1, 1, 2, 8, 1], [10, 1, 1, 1, 7, 1], [10, 4, 1, 1, 7, 1],
[3, 2, 5, 2, 1, 2, 6, 2], [3, 2, 4, 2, 1, 1, 4, 1], [2, 6, 3, 1, 1, 1, 1, 1], [12, 3, 1, 2, 1, 1, 1],
[3, 2, 7, 3, 1, 2, 1, 2], [2, 6, 3, 1, 1, 1, 1], [12, 3, 1, 5], [6, 3, 1],
[6, 4, 1], [5, 4], [4, 1, 1], [5]]
def print_points(points: np.array) -> None:
# print array in console
if points[0, 0] == -2:
print("ERROR\n")
return
for i in range(n):
for j in range(n):
if points[i, j] >= 1:
print('█', end='')
elif points[i, j] == 1:
print('■', end='')
elif points[i, j] == 0:
print('.', end='')
elif points[i, j] == -1:
print('×', end='')
print()
print()
def horizontal_put(points: np.array, x: int, y0: int, y1: int) -> np.array:
# the next position of current array is already occupied
if y1 + 1 < n and np.min(points[x, y0:y1 + 1]) >= 1:
points[0, 0] = -3
return points
# some positions of current array are inaccessible
if np.min(points[x, y0:y1]) == -1 or (y1 < n and points[x, y1] > 0):
points[0, 0] = -2
return points
# set all positions of current array occupied
points[x, y0:y1] = 1
# set the next position of current array inaccessible
if y1 < n:
points[x, y1] = -1
return points
def vertical_put(points: np.array) -> np.array:
for y in range(n):
x = 0
# this column is already finished
if points[n - 1, y] != 0:
continue
for i, nums in enumerate(vertical[y]):
# find next begin position of this column
while x < n and points[x, y] <= 0:
x += 1
# at the end of this column
if x == n:
break
# goto the end position of current array
if points[x, y] == 2:
x += nums
# not enough positions to put current array
elif points[x, y] == 1 and x + nums - 1 >= n:
points[0, 0] = -2
return points
# set positions of current array occupied
elif points[x, y] == 1:
points[x, y] = 2
points[x + 1:x + nums, y] = 1
# set the next position of current array inaccessible
if x + nums < n:
points[x + nums, y] = -1
# this is the last array and set all rest positions inaccessible
if i + 1 == len(vertical[y]) and x + nums < n:
points[x + nums:, y] = -1
break
return points
def search(points: np.array, x: int, y: int, k: int) -> None:
nonlocal is_solved, ans_points
# solution is found
if x == n:
print_points(points)
ans_points = points.copy()
is_solved = True
return
# the last position of this row can start this array
j_end = n - sum(horizontal[x][k:]) - (len(horizontal[x]) - k - 1)
for j in range(y, j_end + 1):
# the previous position of current array is occupied
if j >= 1 and points[x, j - 1] > 0:
break
# create a copy
j1 = j + horizontal[x][k]
new_points = points.copy()
# try to put current array into positions row[x] column[j-j1]
new_points = horizontal_put(new_points, x, j, j1)
# error code -2
if new_points[0, 0] == -2:
continue
# error code -3
elif new_points[0, 0] == -3:
break
# check and put arrays in columns
new_points = vertical_put(new_points)
if new_points[0, 0] == -2:
continue
# this is the last array of this row, but some rest positions of this row are still occupied
if k + 1 == len(horizontal[x]) and j1 < n and np.max(new_points[x, j1:]) > 0:
continue
# recur to next
if k + 1 == len(horizontal[x]):
search(new_points, x + 1, 0, 0)
else:
search(new_points, x, j1 + 1, k + 1)
# solution is already found
if is_solved:
return
search(np.zeros((n, n), dtype=np.int), 0, 0, 0)
ans_points[ans_points > 0] = 255
ans_points[ans_points <= 0] = 0
im = Image.fromarray(ans_points.astype(np.uint8), "L")
im.save("level_32/python.jpg")
0x33 啊啊啊,最后一关啦!本关考察对图片和字节流的处理。看到图片名是“beer1.jpg”,尝试“beer2.jpg”,弹出一张图片写着“no, png”,于是尝试“png”,发现只有“beer2.png”存在。 file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211019191523650.png?lastModify=1634643505 这张图片是138*138大小的,一共有19044个像素,每个像素有一个颜色值,于是有 data(len=138*138) = [1, 43, 7, 13, 7, 1, 1, 85, 25, 85, 25, 1, 91, 103, 31, 37, 1, 13, 169, 1, …… ] 找出颜色值中最大的两个,是193和194,把所有颜色值为193或194的像素变白(255),其它像素变黑(0),得到一张图片“138.png”。现在将data中所有的193和194删除,得到新的data为 data(len=132*132) = [1, 43, 7, 13, 7, 1, 1, 85, 25, 85, 25, 1, 91, 103, 31, 37, 1, 13, 169, 1, …… ] 前20个数都没变,但data的长度变了,发现长度还是一个完全平方数。同样地,找到最大的两个颜色值,是187和188,把所有颜色值为187或188的像素变白(255),其它像素变黑(0),得到一张图片“132.png”。现在将data中所有的187和188删除,得到新的data为 data(len=130*130) = [1, 43, 7, 13, 7, 1, 1, 85, 25, 85, 25, 1, 91, 103, 31, 37, 1, 13, 169, 1, …… ]、 完整代码如下 from PIL import Image
import numpy as np
im = Image.open("beer2.png")
data_list = list(im.getdata())
data_set = set(data_list)
while data_set:
c0 = max(data_set)
data_set.remove(c0)
c1 = max(data_set)
data_set.remove(c1)
c0, c1 = max(c0, c1), min(c0, c1)
n = int(len(data_list) ** 0.5)
data_np = np.array(data_list, dtype=np.uint8).reshape(n, n)
data_np[data_np >= c1] = 255
data_np[data_np < c1] = 0
data_list = [c for c in data_list if c < c1]
im = Image.fromarray(data_np, "L")
im.save(f"{n}.png")file://C:\Users\e'e't\AppData\Roaming\Typora\typora-user-images\image-20211019192157940.png?lastModify=1634643505 得到这些.把这些带边框的英文字母连起来就是“gremlins”
ok 本系列就到此吧
|




 发表于 2021-10-8 20:33:35
发表于 2021-10-8 20:33:35






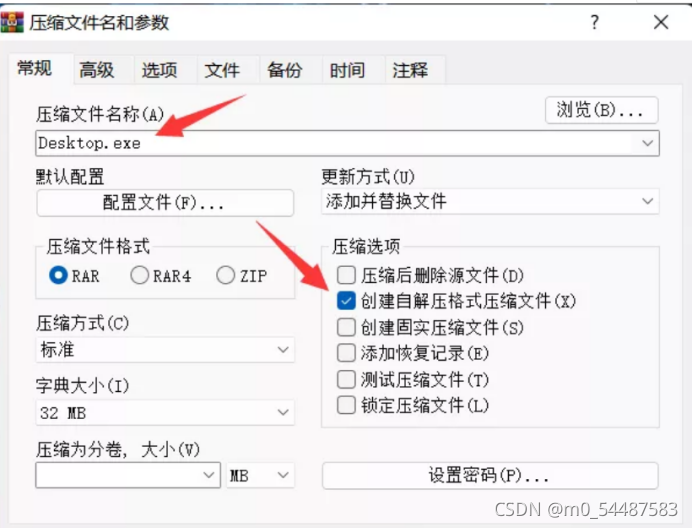
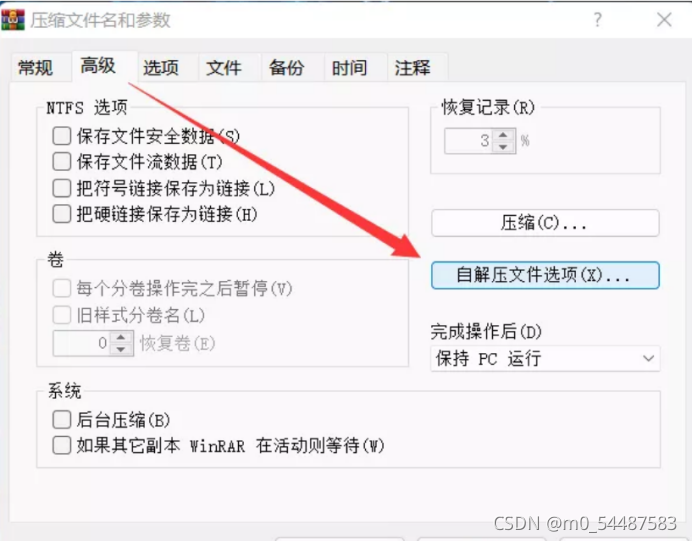
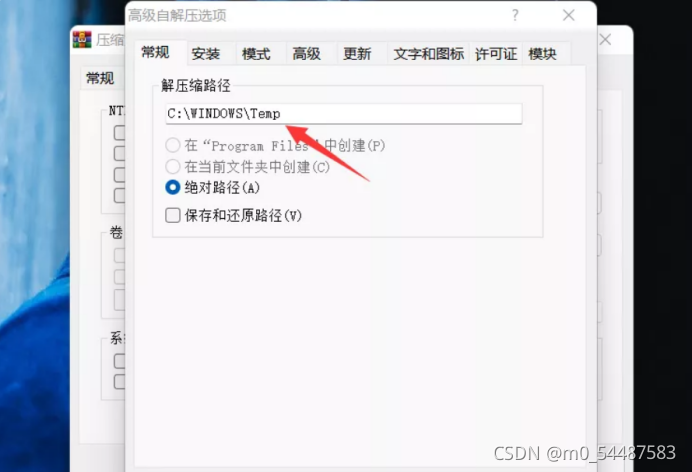

 楼主
楼主 STRENGTH and ALL
STRENGTH and ALL 前五十名也卡在外面,但是主要的是在上次比赛的时候发现我对于python这方面特别欠缺技术,对于题目有自己的想法却没办法去自己写代码实现他,只能拜托学长帮忙,还有两周就是赣网杯了。短期目标:
前五十名也卡在外面,但是主要的是在上次比赛的时候发现我对于python这方面特别欠缺技术,对于题目有自己的想法却没办法去自己写代码实现他,只能拜托学长帮忙,还有两周就是赣网杯了。短期目标:

 ort Peer Address
ort Peer Address