|
|
原文链接:实战 | SRC信息收集思路总结
说到信息收集,网上已经有许多文章进行描述了,那么从正常的子域名、端口、旁站、C段等进行信息收集的话,对于正常项目已经够用了,但是挖掘SRC的话,在诸多竞争对手的“帮助”下,大家收集到的信息都差不多,挖掘的漏洞也往往存在重复的情况。
那么现在我就想分享一下平时自己进行SRC挖掘过程中,主要是如何进行入手的。以下均为小弟拙见,大佬勿喷。
0x01 确定目标无目标随便打,有没有自己对应的SRC应急响应平台不说,还往往会因为一开始没有挖掘到漏洞而随意放弃,这样往往不能挖掘到深层次的漏洞。挖到的大多数是大家都可以简单挖到的漏洞,存在大概率重复可能。所以在真的想要花点时间在SRC漏洞挖掘上的话,建议先选好目标。
那么目标怎么选呢,考虑到收益回报与付出的比例来看,建议是从专属SRC入手,特别在一些活动中,可以获取比平时更高的收益。
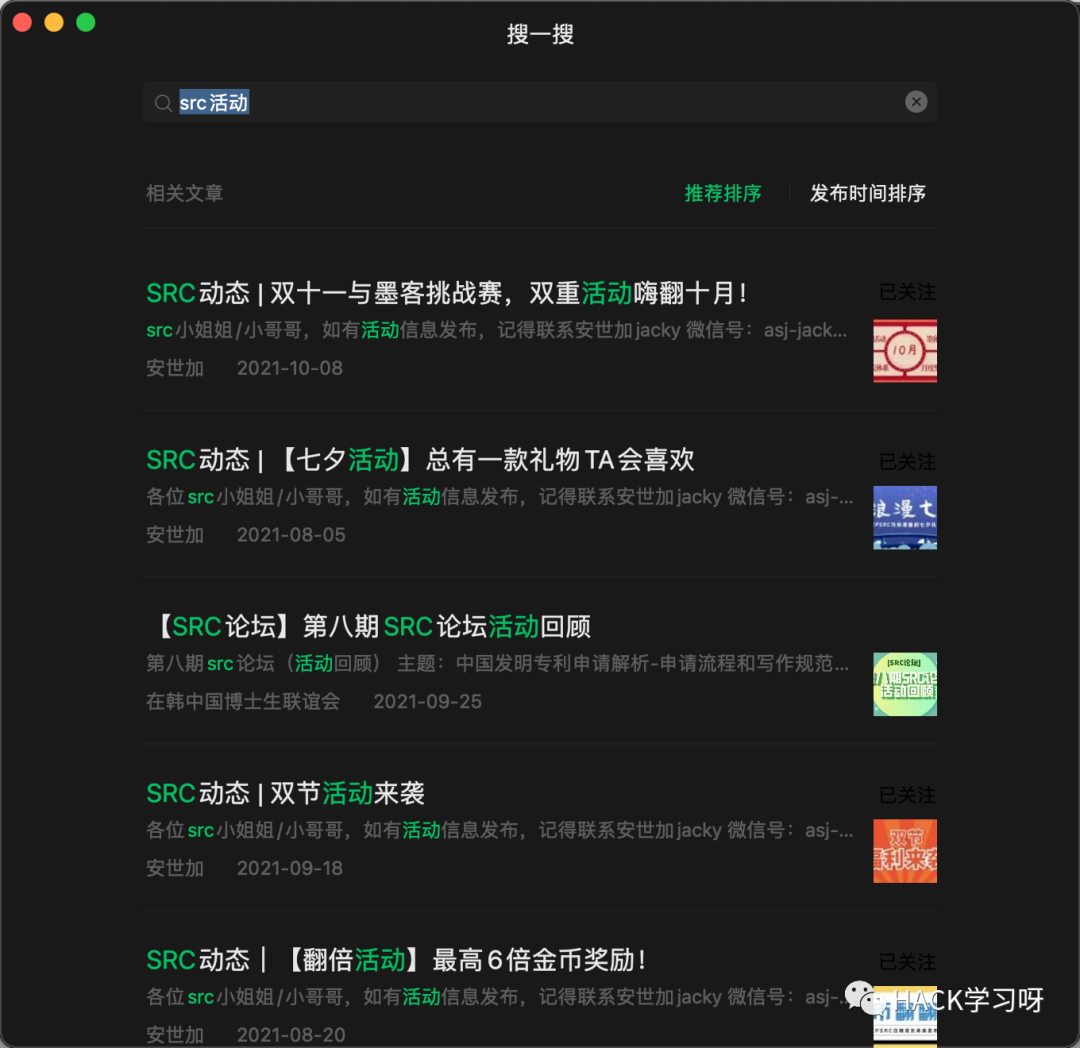
微信搜一搜:
百度搜一搜:
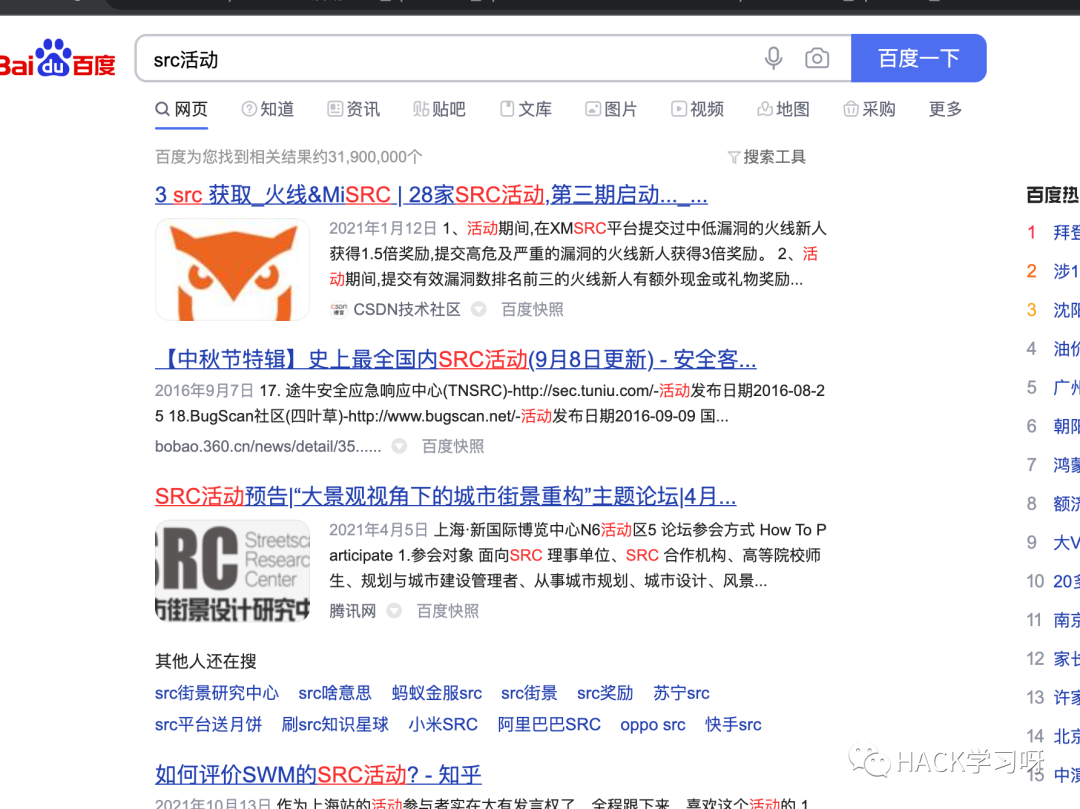
现在有活动的src已经浮现水面了,那么我们就可与从中选择自己感兴趣的SRC。
0x02 确认测试范围前面说到确定测什么SRC,那么下面就要通过一些方法,获取这个SRC的测试范围,以免测偏。
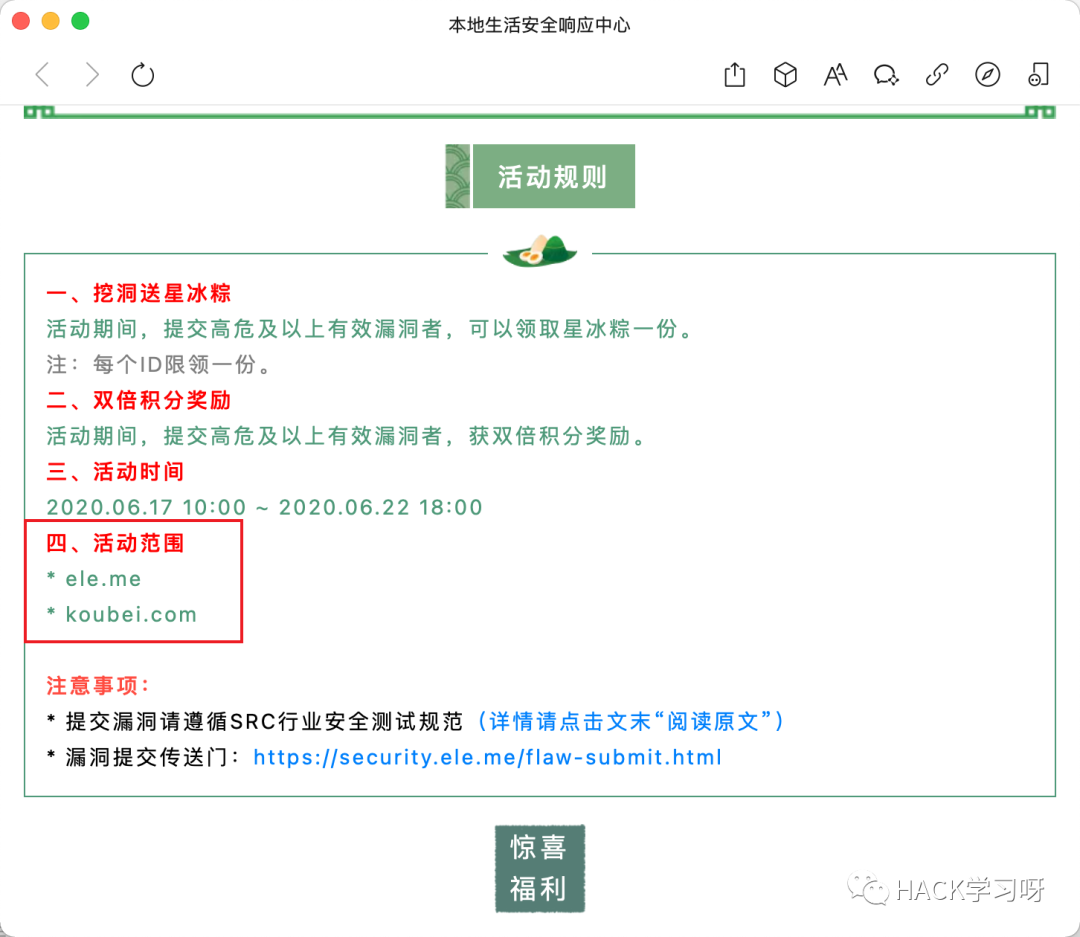
1、公众号从公众号推文入手,活动页面中可以发现测试范围

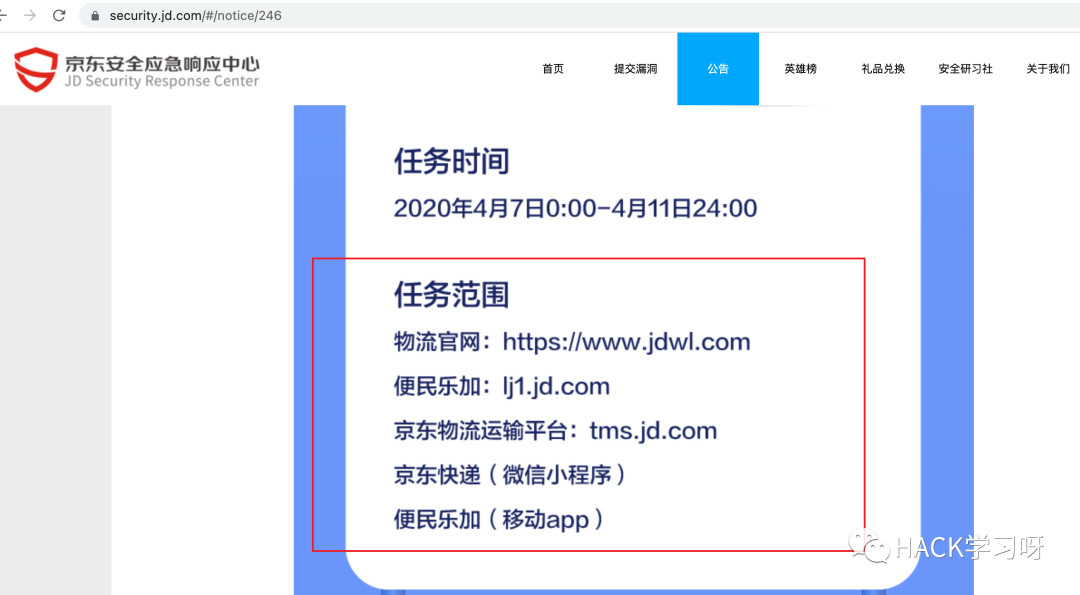
2、应急响应官网在应急响应官网,往往会有一些活动的公告,在里面可以获取到相应的测试范围。
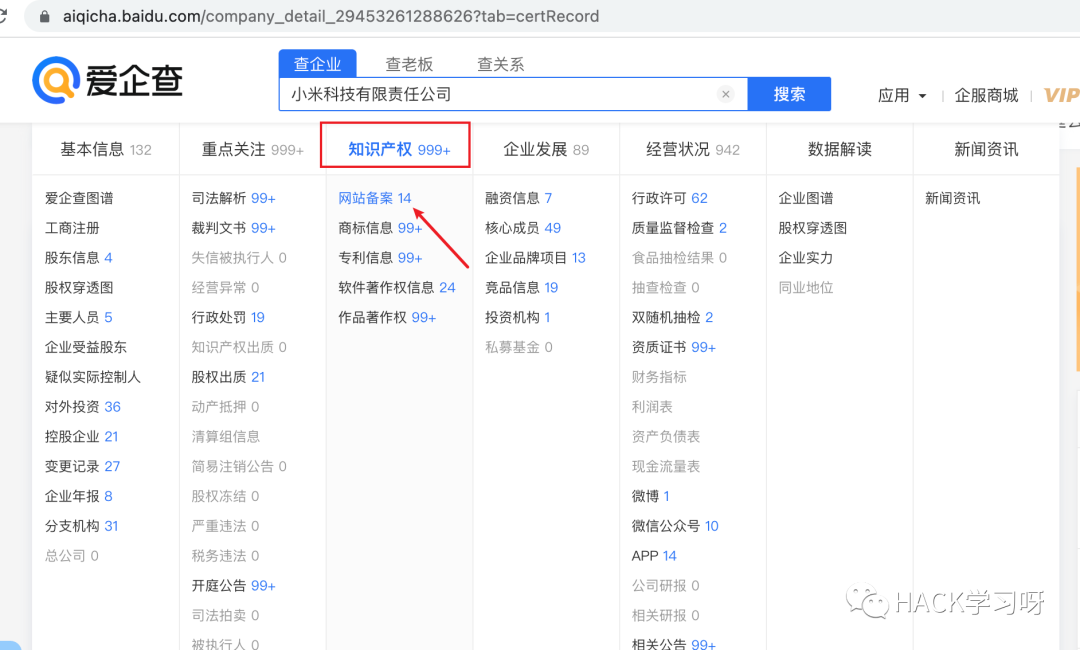
3、爱企查从爱企查等商业查询平台获取公司所属域名
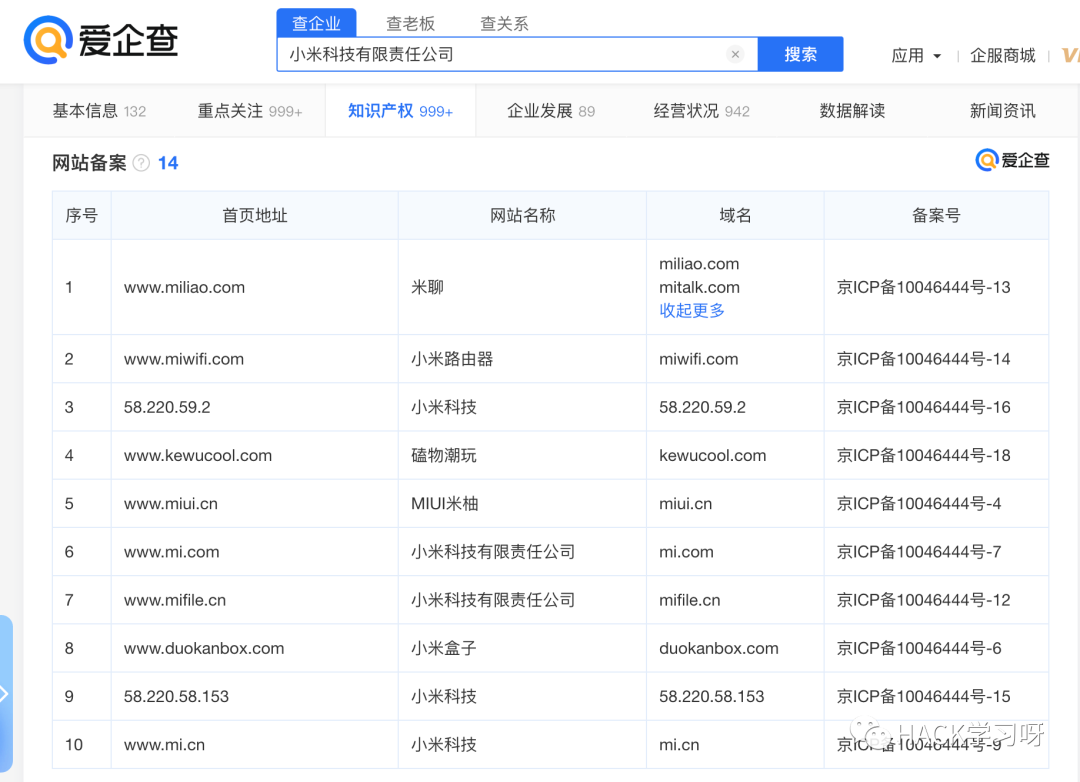
搜索想要测试等SRC所属公司名称,在知识产权->网站备案中可以获取测试范围。
0x03 子域名(oneforall)拿到域名之后,下一步我考虑使用oneforall扫描获取子域名,就像网上信息收集的文章一样,主域名的站点不是静态界面就是安全防护等级极强,不是随便就能够发现漏洞的,我们挖掘SRC也是要从子域名开始,从边缘资产或一般资产中发现漏洞。
工具下载:
https://github.com/shmilylty/OneForAll
具体用法如下:
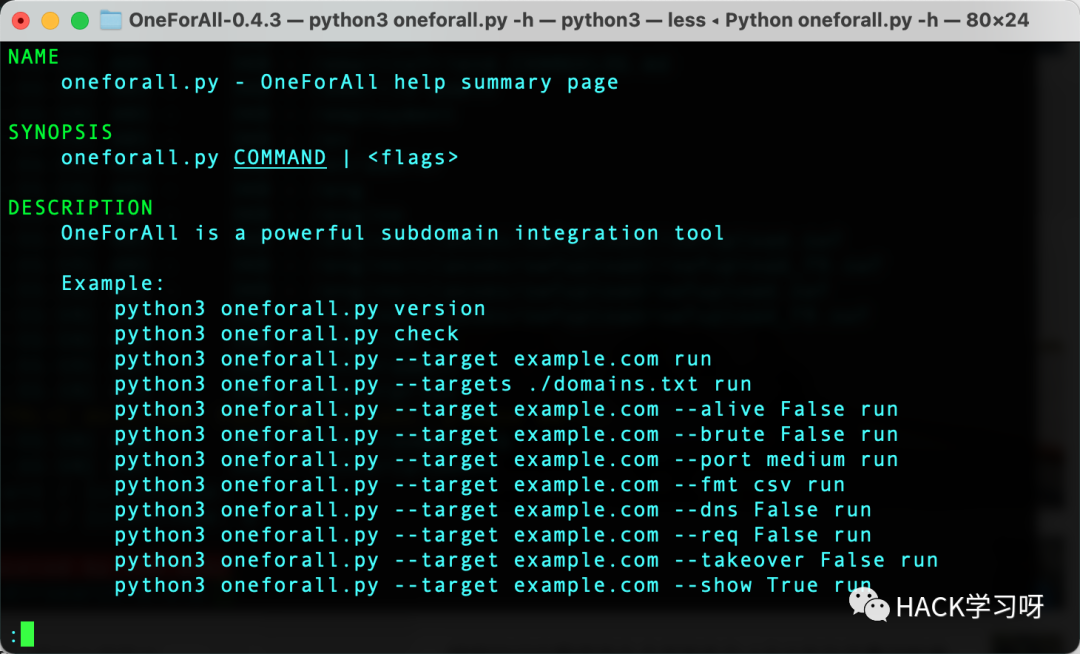
常用的获取子域名有2种选择,一种使用--target指定单个域名,一种使用--targets指定域名文件。
python3 oneforall.py --target example.com runpython3 oneforall.py --targets ./domains.txt run
其他获取子域名的工具还有layer子域名挖掘机、Sublist3r、证书透明度、在线工具等,这里就不一一阐述了,大体思路是一样等,获取子域,然后从中筛选边缘资产,安全防护低资产。
0x04 系统指纹探测通过上面的方法,我们可以在/OneForAll-0.4.3/results/路径下获取以域名为名字的csv文件。里面放入到便是扫描到到所有子域名以及相应信息了。
下一步便是将收集到到域名全部进行一遍指纹探测,从中找出一些明显使用CMS、OA系统、shiro、Fastjson等的站点。下面介绍平时使用的2款工具:
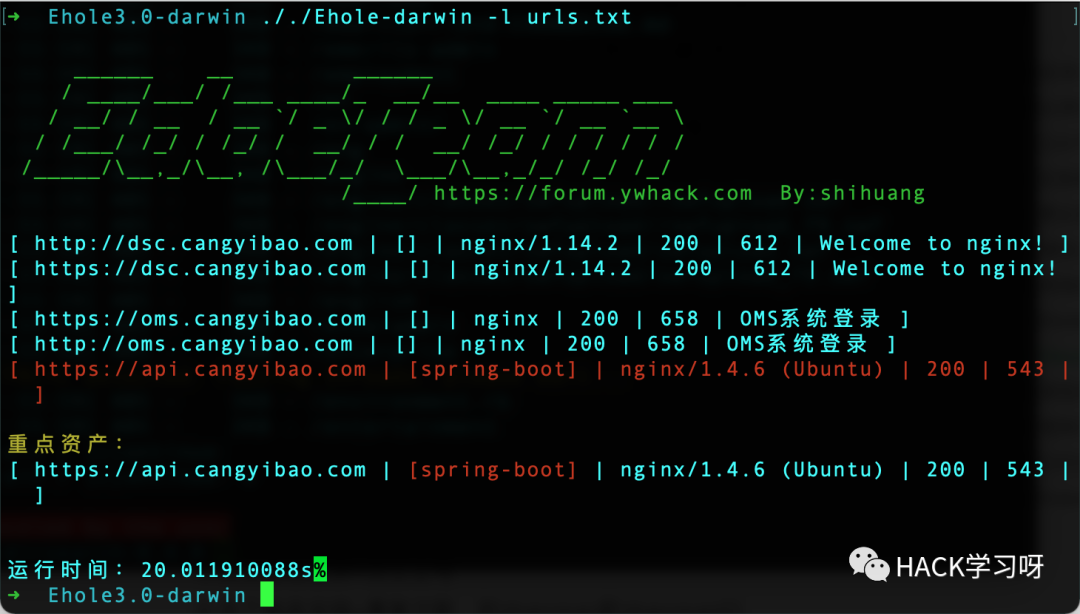
1、Ehole下载地址:
https://github.com/EdgeSecurityTeam/EHole
使用方法:
./Ehole-darwin -l url.txt //URL地址需带上协议,每行一个./Ehole-darwin -f 192.168.1.1/24 //支持单IP或IP段,fofa识别需要配置fofa密钥和邮箱./Ehole-darwin -l url.txt -json export.json //结果输出至export.json文件
2、Glass下载地址:
https://github.com/s7ckTeam/Glass
使用方法:
python3 Glass.py -u http://www.examples.com // 单url测试python3 Glass.py -w domain.txt -o 1.txt // url文件内

0x05 框架型站点漏洞测试前面经过了子域名收集以及对收集到的子域名进行了指纹信息识别之后,那么对于框架型的站点,我们可以优先进行测试。
类似用友NC、通达OA、蓝凌OA等,可以通过尝试现有的Nday漏洞进行攻击。
0x06 非框架型站点漏洞测试前面测试完框架型的站点了,之后就应该往正常网站,或者经过了二开未能直接检测出指纹的站点进行渗透了。那么对于这类站点,最经常遇到的便是登录框,在这里,我们便可以开始测试了。
1、用户名枚举
抓包尝试是否用户名存在与不存在的情况,返回结果不同。
2、验证码
是否存在验证码,验证码是否可以抓包截断绕过,验证码是否可以为空。
3、暴力破解
下面是我收集的集中常见的用户名
1.弱口令用户名如admin,test,ceshi等2.员工姓名全拼,员工姓名简拼3.公司特征+员工工号/员工姓名4.员工工号+姓名简拼5.员工姓名全拼+员工工号6.员工姓名全拼+重复次数,如zhangsan和zhangsan017.其他
关于暴力破解我要扯一句了,就是关于密码字典的问题。经常会听到某人说他的字典多么多么的大,有好几个G之类的,但是在我觉得,这很没有必要,有些密码是你跑几天都跑不出来的,就算字典确实够大,也没有必要这样跑,可能影响心情不说,大规模地暴力破解,很容易让人觉得你在拒绝服务攻击。
其实我的话一般跑一跑弱口令就差不多了。
关于弱口令字典的问题,我也想说一嘴,你最好看看,你字典里面的admin、123456、password处在什么位置。记得之前玩CTF的时候,默认密码123456,但是那个师傅死活做不出来,后面一看,字典里面居然没有123456这个密码。。。
这里推荐一个字典,个人感觉还是挺好用的。当然更多的是需要自己不断更新。
https://github.com/fuzz-security/SuperWordlist
4、工具cupp和cewl
对于一些情况,密码不是直接使用弱口令,而是通过一些公司的特征+个人信息制作的,那么这个时候,我们的字典便不能直接使用了,需要在这之前加上一些特征,例如阿里SRC可能是a;百度SRC可能是bd等。
下面2款kali自带等工具,可以通过收集信息,生成好用的字典,方便渗透。说真的,在渗透测试过程中,弱口令,YYDS!
具体使用说明和工具介绍,可以查看文章:
https://mp.weixin.qq.com/s/HOlPaJ4EMY7PfHh7p2d95A
5、自行注册
如果能够注册那就好办了,自己注册一下账户即可。
6、小总结
对于非框架的站点,登录接口一般是必不可少的,可能就在主页,也可能在某个路径下,藏着后台的登录接口,在尝试了多种方法成功登录之后,记得尝试里面是否存在未授权漏洞、越权等漏洞。
这里借用来自WS师傅的建议:可以直接扫描出来的洞,基本都被交完了,可以更多往逻辑漏洞方面找。登录后的漏洞重复率,比登录前的往往会低很多。
0x07 端口扫描前面就是正常的渗透了,那么一个域名只是在80、443端口才有web服务吗?不可否认有些时候真的是,但是绝大多数情况下,类似8080、8443、8081、8089、7001等端口,往往会有惊喜哦~
端口扫描也算是老生常谈了,市面上也有很多介绍端口扫描的工具使用方法,这里也不细说了,就放出平时使用的命令吧。
sudo nmap -sS -Pn -n --open --min-hostgroup 4 --min-parallelism 1024 --host-timeout 30 -T4 -v examples.comsudo nmap -sS -Pn -n --open --min-hostgroup 4 --min-parallelism 1024 --host-timeout 30 -T4 -v -p 1-65535 examples.com
0x08 目录扫描dirsearch目录扫描在渗透测试过程中我认为是必不可少的,一个站点在不同目录下的不同文件,往往可能有惊喜哦。
个人是喜欢使用dirserach这款工具,不仅高效、页面也好看。市面上还有例如御剑、御剑t00ls版等,也是不错的选择。
dirsearch下载地址:
https://github.com/maurosoria/dirsearch
具体使用方法可以查看github介绍,这里我一般是使用如下命令(因为担心线程太高所以通过-t参数设置为2)
python3 dirsearch.py -u www.xxx.com -e * -t 2
关键的地方是大家都可以下载这款工具,获取它自带的字典,那么路径的话,便是大家都能够搜得到的了,所以这里我推荐是可以适当整合一些师傅们发出来的路径字典到/dirsearch-0.4.2/db/dicc.txt中。例如我的话,是增加了springboot未授权的一些路径、swagger的路径以及一些例如vmvare-vcenter的漏洞路径。
0x09 JS信息收集在一个站点扫描了目录、尝试登录失败并且没有自己注册功能的情况下,我们还可以从JS文件入手,获取一些URL,也许某个URL便能够未授权访问获取敏感信息呢。
1、JSFinder
工具下载:
https://github.com/Threezh1/JSFinder
JSFinder是一款用作快速在网站的js文件中提取URL,子域名的工具。个人觉得美中不足的地方便是不能对获取到到URL进行一些过滤,在某些情况下,JS文件中可以爬取非常多的URL,这其中可能大部分是页面空或者返回200但是页面显示404的。来自HZ师傅的建议,可以修改一下工具,基于当前的基础上,检测获取的URL是否可以访问,访问后的页面大小为多少,标题是什么。。。
思路放这了,找个时间改一改?
- <div aria-label="代码段 小部件" class="cke_widget_wrapper cke_widget_block cke_widget_codeSnippet cke_widget_selected" data-cke-display-name="代码段" data-cke-filter="off" data-cke-widget-id="332" data-cke-widget-wrapper="1" role="region" tabindex="-1" contenteditable="false"><pre class="cke_widget_element" data-cke-widget-data="%7B%22code%22%3A%22%23%E6%A3%80%E6%B5%8BURL%E7%8A%B6%E6%80%81%E7%A0%81%23-----------------------%23!%20%2Fusr%2Fbin%2Fenv%20python%23coding%3Dutf-8import%20sysimport%20requestsurl%3D'xxxx'request%20%3D%20requests.get(url)httpStatusCode%20%3D%20request.status_codeif%20httpStatusCode%20%3D%3D%20200%3A%20%20%20%20xxxxelse%3A%20%20%20%20%20%20%20%20xxxx%22%2C%22classes%22%3Anull%7D" data-cke-widget-keep-attr="0" data-cke-widget-upcasted="1" data-widget="codeSnippet"><code class="hljs">#检测URL状态码#-----------------------#! /usr/bin/env python#coding=utf-8import sysimport requestsurl='xxxx'request = requests.get(url)httpStatusCode = request.status_codeif httpStatusCode == 200: xxxxelse: xxxx</code></pre>
- <span class="cke_reset cke_widget_drag_handler_container" style="background:rgba(220,220,220,0.5);background-image:url(https://csdnimg.cn/release/blog_editor_html/release1.9.4/ckeditor/plugins/widget/images/handle.png);display:none;"><img class="cke_reset cke_widget_drag_handler" data-cke-widget-drag-handler="1" role="presentation" src="data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==" title="点击并拖拽以移动" width="15" height="15"></span></div>
- <div aria-label="代码段 小部件" class="cke_widget_wrapper cke_widget_block cke_widget_codeSnippet cke_widget_selected" data-cke-display-name="代码段" data-cke-filter="off" data-cke-widget-id="331" data-cke-widget-wrapper="1" role="region" tabindex="-1" contenteditable="false">
- <pre class="cke_widget_element" data-cke-widget-data="%7B%22code%22%3A%22%23%E6%A3%80%E6%B5%8BURL%E8%BF%94%E5%9B%9E%E5%8C%85%E5%A4%A7%E5%B0%8F%23-----------------------import%20requestsdef%20hum_convert(value)%3A%20%20%20%20units%20%3D%20%5B%5C%22B%5C%22%2C%20%5C%22KB%5C%22%2C%20%5C%22MB%5C%22%2C%20%5C%22GB%5C%22%2C%20%5C%22TB%5C%22%2C%20%5C%22PB%5C%22%5D%20%20%20%20size%20%3D%201024.0%20%20%20%20for%20i%20in%20range(len(units))%3A%20%20%20%20%20%20%20%20if%20(value%20%2F%20size)%20%3C%201%3A%20%20%20%20%20%20%20%20%20%20%20%20return%20%5C%22%25.2f%25s%5C%22%20%25%20(value%2C%20units%5Bi%5D)%20%20%20%20%20%20%20%20value%20%3D%20value%20%2F%20sizer%20%3D%20requests.get('https%3A%2F%2Fwww.baidu.com')r.status_coder.headerslength%20%3D%20len(r.text)print(hum_convert(length))%22%2C%22classes%22%3Anull%7D" data-cke-widget-keep-attr="0" data-cke-widget-upcasted="1" data-widget="codeSnippet"><code class="hljs"></code></pre></div>
- <div aria-label="代码段 小部件" class="cke_widget_wrapper cke_widget_block cke_widget_codeSnippet cke_widget_selected" data-cke-display-name="代码段" data-cke-filter="off" data-cke-widget-id="331" data-cke-widget-wrapper="1" role="region" tabindex="-1" contenteditable="false"><pre class="cke_widget_element" data-cke-widget-data="%7B%22code%22%3A%22%23%E6%A3%80%E6%B5%8BURL%E8%BF%94%E5%9B%9E%E5%8C%85%E5%A4%A7%E5%B0%8F%23-----------------------import%20requestsdef%20hum_convert(value)%3A%20%20%20%20units%20%3D%20%5B%5C%22B%5C%22%2C%20%5C%22KB%5C%22%2C%20%5C%22MB%5C%22%2C%20%5C%22GB%5C%22%2C%20%5C%22TB%5C%22%2C%20%5C%22PB%5C%22%5D%20%20%20%20size%20%3D%201024.0%20%20%20%20for%20i%20in%20range(len(units))%3A%20%20%20%20%20%20%20%20if%20(value%20%2F%20size)%20%3C%201%3A%20%20%20%20%20%20%20%20%20%20%20%20return%20%5C%22%25.2f%25s%5C%22%20%25%20(value%2C%20units%5Bi%5D)%20%20%20%20%20%20%20%20value%20%3D%20value%20%2F%20sizer%20%3D%20requests.get('https%3A%2F%2Fwww.baidu.com')r.status_coder.headerslength%20%3D%20len(r.text)print(hum_convert(length))%22%2C%22classes%22%3Anull%7D" data-cke-widget-keep-attr="0" data-cke-widget-upcasted="1" data-widget="codeSnippet"><code class="hljs">#检测URL返回包大小#-----------------------import requestsdef hum_convert(value): units = ["B", "KB", "MB", "GB", "TB", "PB"] size = 1024.0 for i in range(len(units)): if (value / size) < 1: return "%.2f%s" % (value, units[i]) value = value / sizer = requests.get('https://www.baidu.com')r.status_coder.headerslength = len(r.text)print(hum_convert(length))</code></pre>
- <span class="cke_reset cke_widget_drag_handler_container" style="background:rgba(220,220,220,0.5);background-image:url(https://csdnimg.cn/release/blog_editor_html/release1.9.4/ckeditor/plugins/widget/images/handle.png);display:none;"><img class="cke_reset cke_widget_drag_handler" data-cke-widget-drag-handler="1" role="presentation" src="data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==" title="点击并拖拽以移动" width="15" height="15"></span></div>
- <div aria-label="代码段 小部件" class="cke_widget_wrapper cke_widget_block cke_widget_codeSnippet cke_widget_selected" data-cke-display-name="代码段" data-cke-filter="off" data-cke-widget-id="330" data-cke-widget-wrapper="1" role="region" tabindex="-1" contenteditable="false">
- <pre class="cke_widget_element" data-cke-widget-data="%7B%22code%22%3A%22%23%E8%8E%B7%E5%8F%96%E7%BD%91%E7%AB%99%E6%A0%87%E9%A2%98%23-----------------------%23!%2Fusr%2Fbin%2Fpython%23coding%3Dutf-8urllib.requestimport%20urllib.requestimport%20reurl%20%3D%20urllib.request.urlopen('http%3A%2F%2Fwww.xxx.com')html%20%3D%20url.read().decode('utf-8')title%3Dre.findall('%3Ctitle%3E(.%2B)%3C%2Ftitle%3E'%2Chtml)print%20(title)%22%2C%22classes%22%3Anull%7D" data-cke-widget-keep-attr="0" data-cke-widget-upcasted="1" data-widget="codeSnippet"><code class="hljs"></code></pre></div>
- <div aria-label="代码段 小部件" class="cke_widget_wrapper cke_widget_block cke_widget_codeSnippet cke_widget_selected" data-cke-display-name="代码段" data-cke-filter="off" data-cke-widget-id="330" data-cke-widget-wrapper="1" role="region" tabindex="-1" contenteditable="false"><pre class="cke_widget_element" data-cke-widget-data="%7B%22code%22%3A%22%23%E8%8E%B7%E5%8F%96%E7%BD%91%E7%AB%99%E6%A0%87%E9%A2%98%23-----------------------%23!%2Fusr%2Fbin%2Fpython%23coding%3Dutf-8urllib.requestimport%20urllib.requestimport%20reurl%20%3D%20urllib.request.urlopen('http%3A%2F%2Fwww.xxx.com')html%20%3D%20url.read().decode('utf-8')title%3Dre.findall('%3Ctitle%3E(.%2B)%3C%2Ftitle%3E'%2Chtml)print%20(title)%22%2C%22classes%22%3Anull%7D" data-cke-widget-keep-attr="0" data-cke-widget-upcasted="1" data-widget="codeSnippet"><code class="hljs">#获取网站标题#-----------------------#!/usr/bin/python#coding=utf-8urllib.requestimport urllib.requestimport reurl = urllib.request.urlopen('http://www.xxx.com')html = url.read().decode('utf-8')title=re.findall('<title>(.+)</title>',html)print (title)</code></pre>
- <span class="cke_reset cke_widget_drag_handler_container" style="background:rgba(220,220,220,0.5);background-image:url(https://csdnimg.cn/release/blog_editor_html/release1.9.4/ckeditor/plugins/widget/images/handle.png);display:none;"><img class="cke_reset cke_widget_drag_handler" data-cke-widget-drag-handler="1" role="presentation" src="data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==" title="点击并拖拽以移动" width="15" height="15"></span></div>
- <p></p>
2、JS文件
JS文件与HTML、CSS等文件统一作为前端文件,是可以通过浏览器访问到的,相对于HTML和CSS等文件的显示和美化作用,JS文件将会能够将页面的功能点进行升华。

对于渗透测试来说,JS文件不仅仅能够找到一些URL、内网IP地址、手机号、调用的组件版本等信息,还存在一些接口,因为前端需要,所以一些接口将会在JS文件中直接或间接呈现。下面我将介绍如何发现这些隐藏的接口。
1、首先在某个页面中,鼠标右键,选择检查
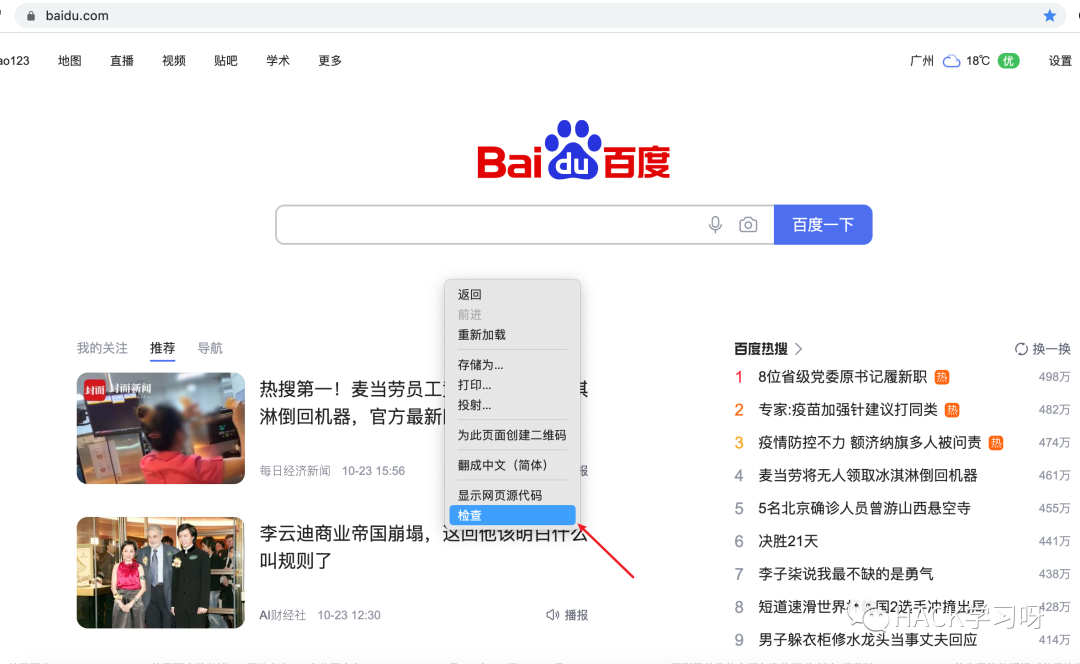
2、点击Application
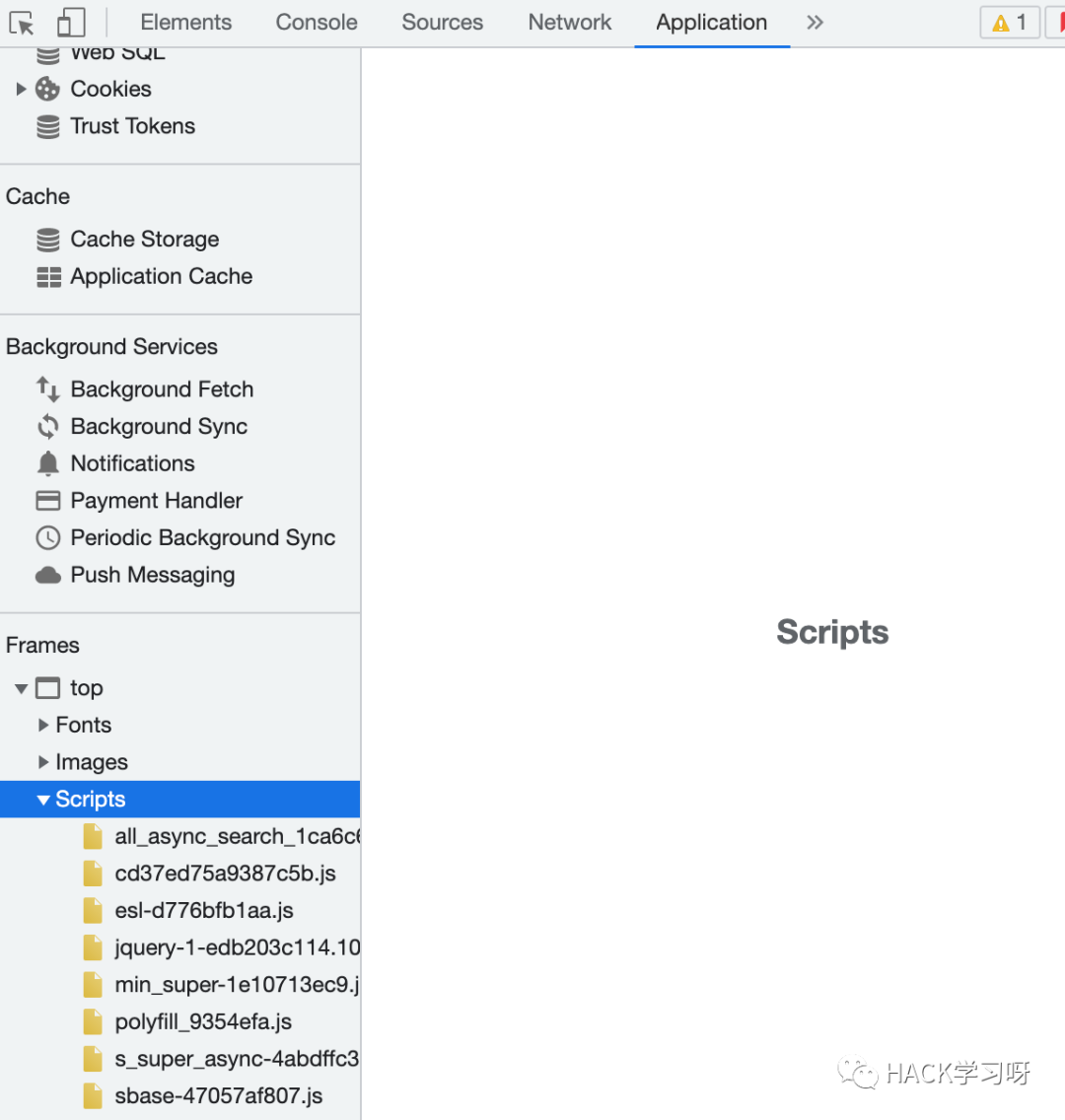
 3、在Frames->top->Scripts中能够获取当前页面请求到的所有JS 3、在Frames->top->Scripts中能够获取当前页面请求到的所有JS
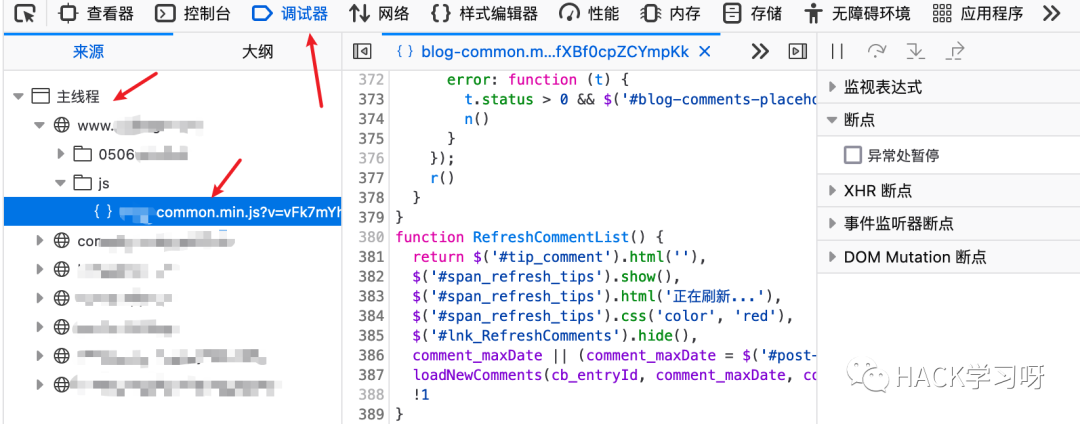
4、火狐浏览器的话,则是在调试中
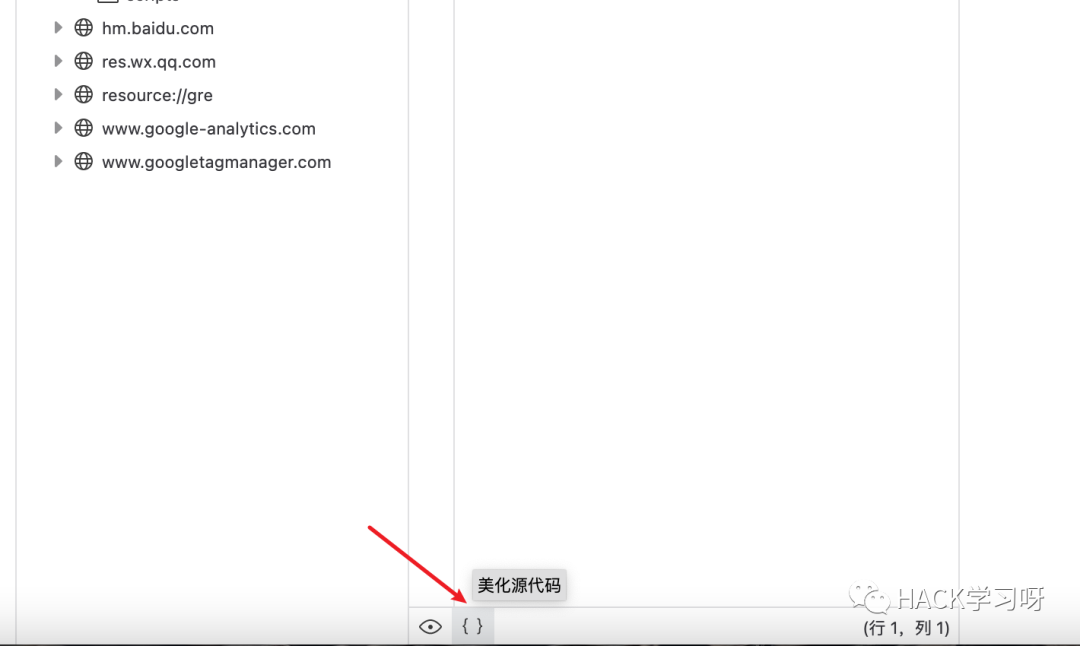
5、如果你请求的JS文件内容都叠在了前几行的话,下面这个键可以帮你美化输出
6、在JS文件中,可以尤为注意带有api字眼的文件或内容,例如下面这里我发现了一个接口。
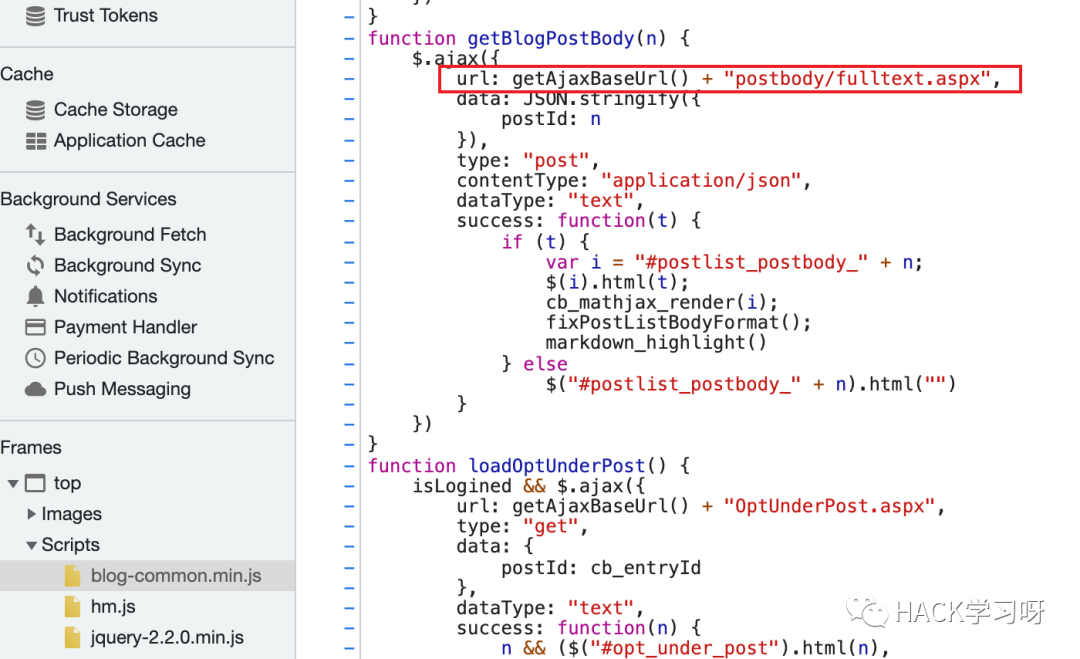
0xA 小程序、APPweb端没有思路的时候,可以结合小程序、APP来进行渗透。小程序或APP的服务端其实可以在一定程度上与web应用的服务端相联系。也就是说,我们在小程序或者APP上,一样能够挖掘web端的漏洞如SQL注入、XSS等,并且相对来说,这类等服务端安全措施会相对没有那么完备,所以在web端确实没有思路的时候,可以迂回渗透,从小程序、APP中进行。
- #小程序抓包、APP抓包参考链接:
- https://mp.weixin.qq.com/s/xuoVxBsN-t5KcwuyGpR56g
- https://mp.weixin.qq.com/s/45YF4tBaR-TUsHyF5RvEsw
- https://mp.weixin.qq.com/s/M5xu_-_6fgp8q0KjpzvjLg
- https://mp.weixin.qq.com/s/Mfkbxtrxv5AvY-n_bMU7ig
0xB 总结
以上就是我个人挖掘SRC的一些信息收集思路,挖掘SRC有的时候真的很看运气,也许别人对一个接口简单Fuzz,便出了一个注入,而我们花了几天,还是一直看到返回内容为404。所以有的时候真的可以换个站试试,也许就挖到高危甚至严重了~
作为一名SRC小白,以上内容均为小弟拙见,希望能够通过这篇文章,帮到更多的网络安全小白,没能帮上大佬们真的很抱歉~后续也会持续提高自己,将学到的更多的东西分享给大家。
0XC 推荐一个网站
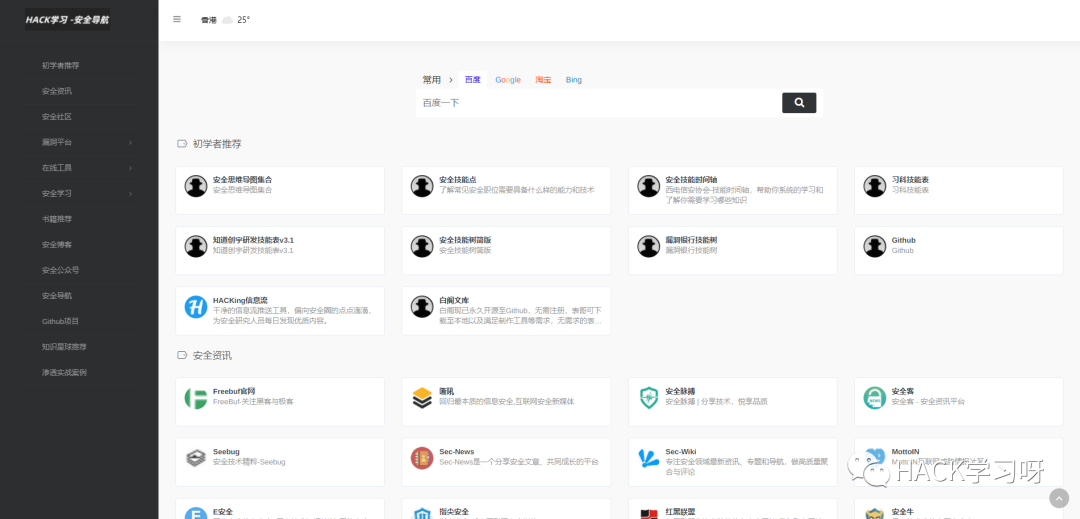
有SRC的厂商列表,可以自己去专属的SRC提交漏洞
|
|




 发表于 2021-11-5 15:39:46
发表于 2021-11-5 15:39:46