|
|
|
crypto之曼彻斯特编码
通过对数字信号进行编码来表示数据不归零编码、曼切斯特编码、差分曼切斯特编码都是其编码方式
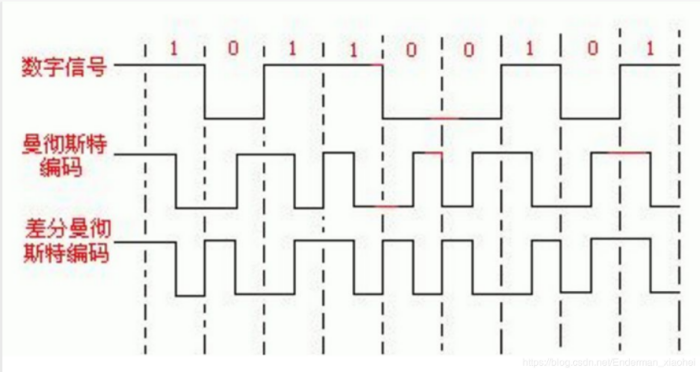
差分曼彻斯特编码是一种使用中位转变来计时的编码方案。数据通过在数据位开始处加一转变来表示。令牌环局域网就利用差分曼彻斯特编码方案。在 每个时钟周期的中间都有一次电平跳变,这个跳变做同步之用。在每个时钟周期的起始处:跳变则说明该比特是0,不跳变则说明该比特是1。差分曼彻斯特编码的优点为:收发双方可以根据编码自带的时钟信号来保持同步,无需专门传递同步信号的线路,因此成本低;缺点为:实现技术复杂。
曼彻斯特编码(Manchester Encoding),也叫做相位编码(PE),是一个同步时钟编码技术,被物理层使用来编码一个同步位流的时钟和数据。曼彻斯特编码被用在以太网媒介系统中。曼彻斯特编码提供一个简单的方式给编码简单的二进制序列而没有长的周期没有转换级别,因而防止时钟同步的丢失,或来自低频率位移在贫乏补偿的模拟链接位错误。在这个技术下,实际上的二进制数据被传输通过这个电缆,不是作为一个序列的逻辑1或0来发送的(技术上叫做反向不归零制(NRZ))。相反地,这些位被转换为一个稍微不同的格式,它通过使用直接的二进制编码有很多的优点。
差分曼彻斯特编码,每位中间的跳变仅提供时钟定时,而用每位开始时有无跳变表示"0"或"1",有跳变为"0",无跳变为"1"。
曼彻斯特编码的编码规则是:在信号位中电平从低到高跳变表示1,在信号位中电平从高到低跳变表示0。
这个图就单独的表示曼彻斯特编码的0,1原理图 从低到高就是0,从高到低就是1
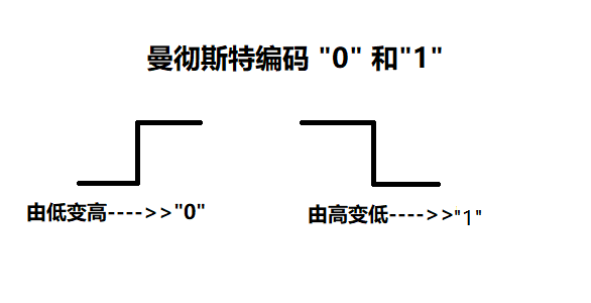 
看曼彻斯特就简单的分成一段一段看他上升还是下降就可以表示出来
而差分曼彻斯特要看他前一个信号的值,比如这图里第一个就是不跳就用1表示,第二个信号从底下升到高处就跳了表示0,第三个也是不跳用1表示,第4个同理也是1,第5个跳了就是0。而差分的意思应该就是要把一段内拆成两段只看前一段,而后一半是用来同步时钟用的,顺便可以传输下一个数据来表示是否有跳
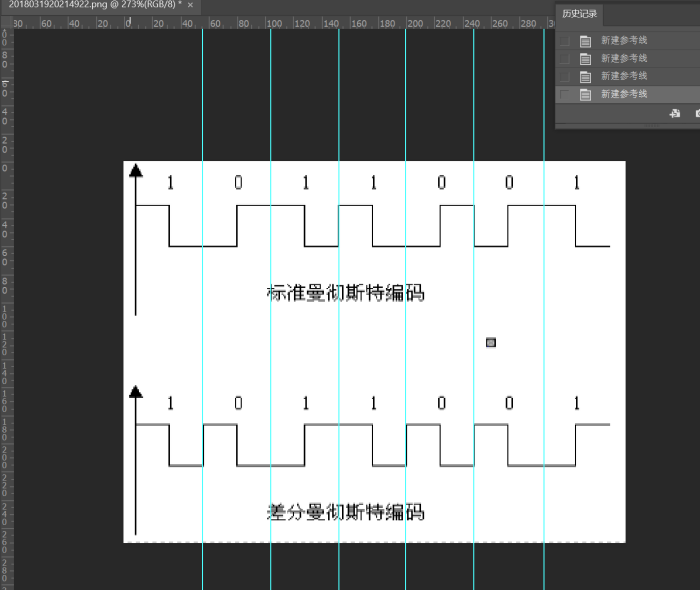
再来看下三种信号的区别
在来说下802.3曼彻斯特和标准曼彻斯特的区别,就是编码后的字符的区别。第一种G. E. Thomas, Andrew S. Tanenbaum1949年提出的,它规定0是由低-高的电平跳变表示,1是高-低的电平跳变。按此规则有:
- 编码0101(即0x5),表示原数据为00;
- 编码1001(0x9)表示10;
- 编码0110(0x6)表示01;
- 编码1010(0xA)表示11。
第二种IEEE 802.4(令牌总线)和低速版的IEEE 802.3(以太网)中规定, 按照这样的说法, 低-高电平跳变表示1, 高-低的电平跳变表示0。
- 编码0101(0x5)表示11;
- 编码1001(0x9)表示01;
- 编码0110(0x6)表示10;
- 编码1010(0xA)表示00;
顺便推荐一个可解,差分曼彻斯特和标准曼彻斯特和802.3曼彻斯特 http://www.pc6.com/softview/SoftView_606143.html
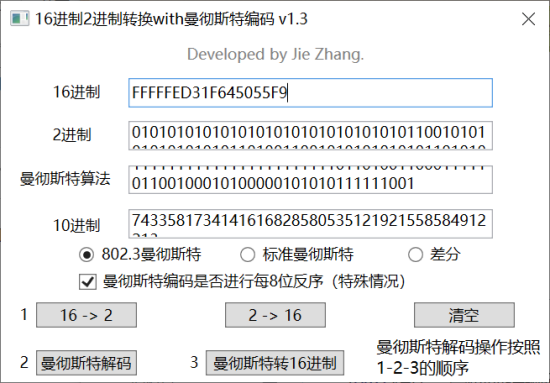
BUUOJ-Crypto-传感器
- 5555555595555A65556AA696AA6666666955
- 这是某压力传感器无线数据包解调后但未解码的报文(hex)
-
- 已知其ID为0xFED31F,请继续将报文完整解码,提交hex。
- 提示1:曼联
去网上抄了个脚本,这个脚本的转换其实就是应用了802.3曼彻斯特的规则取了1和3位,题目里给了id的话,可以看flag解出来是否含有id?吗,相当于校验是否正确的一个功能。
- cipher='5555555595555A65556AA696AA6666666955'
- def iee(cipher):
- tmp=''
- for i in range(len(cipher)):
- a=bin(eval('0x'+cipher[i]))[2:].zfill(4) #补齐四位方便取1和3位
- tmp=tmp+a[1]+a[3] #加上1和3位,就是应用了802.3的規則,或者定义一个字典替换也可以
- print(tmp)
- plain=[hex(int(tmp[i:i+8][::-1],2))[2:] for i in range(0,len(tmp),8)]
- print(''.join(plain).upper())
- iee(cipher)
- # tmp="111111111111111101111111110010111111100000100110000010101010101010011111"
- # flag=""
- # for i in range(0,len(tmp),8):
- # # plain=hex(int(tmp[i:i+8][::-1],2))[2:]
- # # print(''.join(plain).upper())
- # flag+=((hex(int(tmp[i:i+8][::-1],2)))[2:])
- # print(flag.upper())
或者用工具也可以直接出
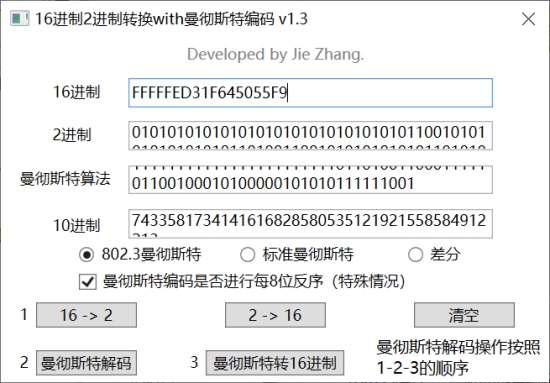
CISCN(全国大学生信息安全竞赛) 2016 传感器2
- 现有某ID为0xFED31F的压力传感器,已知测得压力为45psi时的未解码报文为:
- 5555555595555A65556A5A96AA666666A955 压力为30psi时的未解码报文为:5555555595555A65556A9AA6AA6666665665 请给出ID为0xFEB757的传感器在压力为25psi时的解码后报文,提交hex。
- 注:其他测量读数与上一个传感器一致。
- tips:flag是flag{破译出的明文}
根据进制转换,转成十进制差5的话就是11
- 0xFED31F
- 45psi fffffed31f635055f8
- 30psi fffffed31f425055d7
- 找到两个psi差的地方,相减,括号内是十进制的数
- f8(248)-d7(215)=0x21(33)
- 63(99)-42(66)=0x21(33)
- 15差33的话,5就是差11。除3即可
- 15 33
- 5 11
- 0xFEB757
- CC=215-11
- 37=66-11
- 拿差值替换掉
- 25psi fffffed31f375055CC
- 把检验位直接替换掉
- fffffeb757375055cc
- 转成大写
- FFFFFEB757375055CC
CISCN(全国大学生信息安全竞赛) 2017 传感器1
- 已知ID为0x8893CA58的温度传感器的未解码报文为:3EAAAAA56A69AA55A95995A569AA95565556 此时有另一个相同型号的传感器,其未解码报文为:3EAAAAA56A69AA556A965A5999596AA95656 请解出其ID,提交flag{hex(不含0x)}。
先把给的字符串转成以一位字符串转为4位2进制的01数字。然后在以两位分割,因为差分曼彻斯特编码后面的数据是同步时钟和决定下一个传输的数据的,所以加进去之后。还要等于cc,让他继续下一步的操作,判断是否为01就是是否有跳。bintohex函数就是把01数据转为字符串。可以看下面另一个脚本的单独操作
- #coding:utf-8
- import re
-
- #hex1 = 'AAAAA56A69AA55A95995A569AA95565556' # # 0x8893CA58
- hex1 = 'AAAAA56A69AA556A965A5999596AA95656'
- def bintohex(s1):
- s2 = ''
- s1 = re.findall('.{4}',s1)
- print ('每一个hex分隔:',s1)
- for i in s1:
- s2 += str(hex(int(i,2))).replace('0x','')
-
- print ('ID:',s2)
-
- def diffmqst(s):
- s1 = ''
- s = re.findall('.{2}',s)
- cc = '01'
- for i in s:
- if i == cc:
- s1 += '0'
- else:
- s1 += '1'
- cc = i # 差分加上cc = i
-
- print ('差分曼切斯特解码:',s1)
- bintohex(s1)
-
- if __name__ == '__main__':
- bin1 = bin(int(hex1,16))[2:]
- diffmqst(bin1)

再贴一个脚本
- str1 = '3EAAAAA56A69AA556A965A5999596AA95656'
- s = ''
- for i in xrange(len(str1)/2):
- ch = str1[i*2 : i*2+2]
- b = bin(int(ch, 16))[2:]
- b = '0' * (8-len(b)) + b
- s += b
- print 's:'+s
- r = ''
- #因为此处除了前六位都是10和01,很明显是曼彻斯特,因而把前六位去掉即可看到正确的结果
- s = s[6:]
- print 's:'+s
- for i in xrange(len(s)/2-1):
- c = s[i*2+1 : i*2+3]
- if c == '11' or c=='00':
- r += '1'
- else:
- r += '0'
- print "r:"+r
- ret =''
- for i in xrange(len(r)/8):
- c = r[i*8 : i*8+8]
- print str(r[i*8 : i*8+8]) + ' ' + c
- ret += hex(int(c, 2 ))[2:].upper()
- print ret
左边去掉5个字符,右边去掉4个字符
- str="10000000001001001101100010000100010110101011111100110100000100011001"
- a=0
- flag=""
- for i in range(0,len(str)/4):
- # print(str[0+(i*4):4+(i*4)])
- # a+=1
- flag+=hex(int(str[0+(i*4):4+(i*4)],2))[2:]
- # print(hex(int(str[0+(i*4):4+(i*4)],2))[2:])
- # print(str[4:8])
- print(flag)
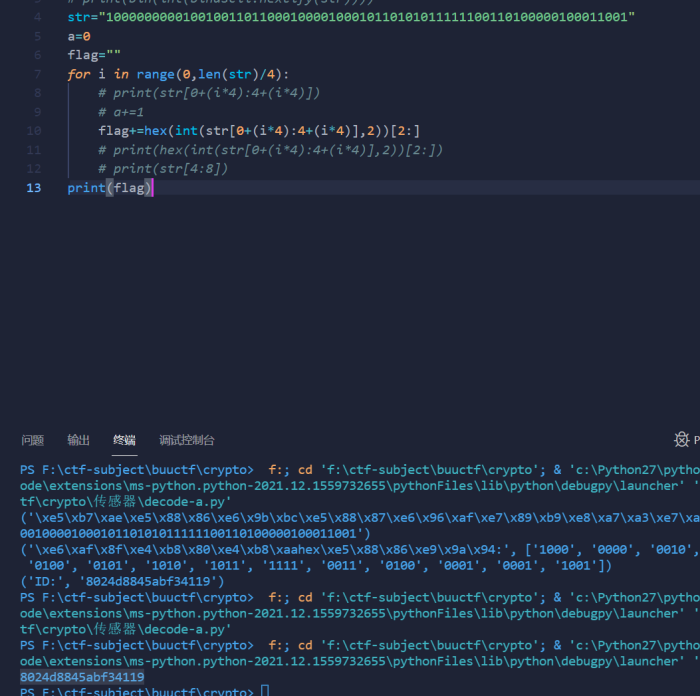
或者就是直接上工具
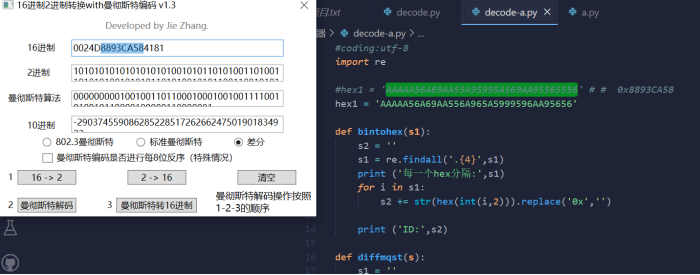
CISCN(全国大学生信息安全竞赛) 2017 传感器2
- 已知ID为0x8893CA58的温度传感器未解码报文为:3EAAAAA56A69AA55A95995A569AA95565556
- 为伪造该类型传感器的报文ID(其他报文内容不变),请给出ID为0xDEADBEEF的传感器1的报文校验位(解码后hex),以及ID为0xBAADA555的传感器2的报文校验位(解码后hex),并组合作为flag提交。
- 例如,若传感器1的校验位为0x123456,传感器2的校验位为0xABCDEF,则flag为flag{123456ABCDEF}。
- 0024D 8893CA58 41 81
- 0024D 8845ABF3 41 19
- 把上一题的数据拿过来查看,格式应该是0024+id+41+xx(校验)
- 其他格式都是固定的,即可判别最后两位为校验
把题目给的数据,分开找到校验的值。如果是按一位=4位,即为8位,可以尝试crc8
- >>> bin(int('A',16))
- '0b1010'
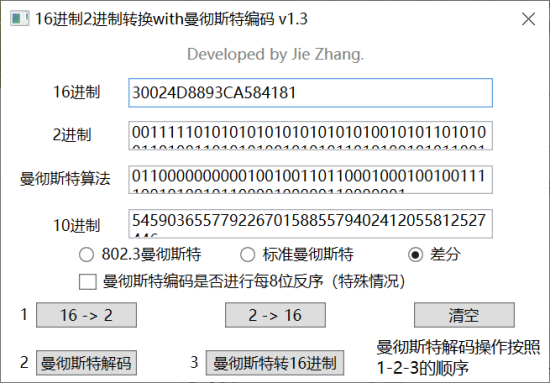
可以看到就是等于校验值的
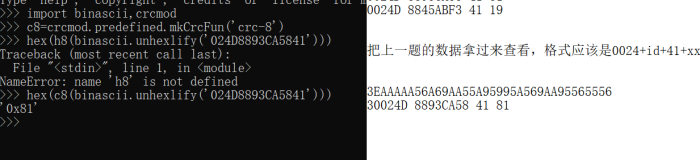
直接就拿题目要求的替换掉id即可
- 0xDEADBEEF
- 024DDEADBEEF41
- 0xBAADA555
- 024DBAADA55541
- >>> hex(c8(binascii.unhexlify('024DDEADBEEF41')))
- '0xb5'
- >>> hex(c8(binascii.unhexlify('024DBAADA55541')))
- '0x15'
或者在线解也可以

参考链接:
|
|




 发表于 2022-3-4 20:38:28
发表于 2022-3-4 20:38:28