前言
利用内存马达到命令执行/文件下载等操作已经是老生常谈的,在现在的红蓝对抗中,很多时候拿到权限,但却在内网无法伸展,这种情况已经越来越常见了。
近月,内存马的技术也产生新的变化,如利用websocket进行通信,Executor内存马进行socket通信。可以看到内存马开始寻找新的载体。本文介绍利用Poller(Executor的上层类)内存马实现全流量监控,这样,攻击方可以实时监控经过系统的每一个请求,或者增加了钓鱼等信息利用的便利。先贴出项目
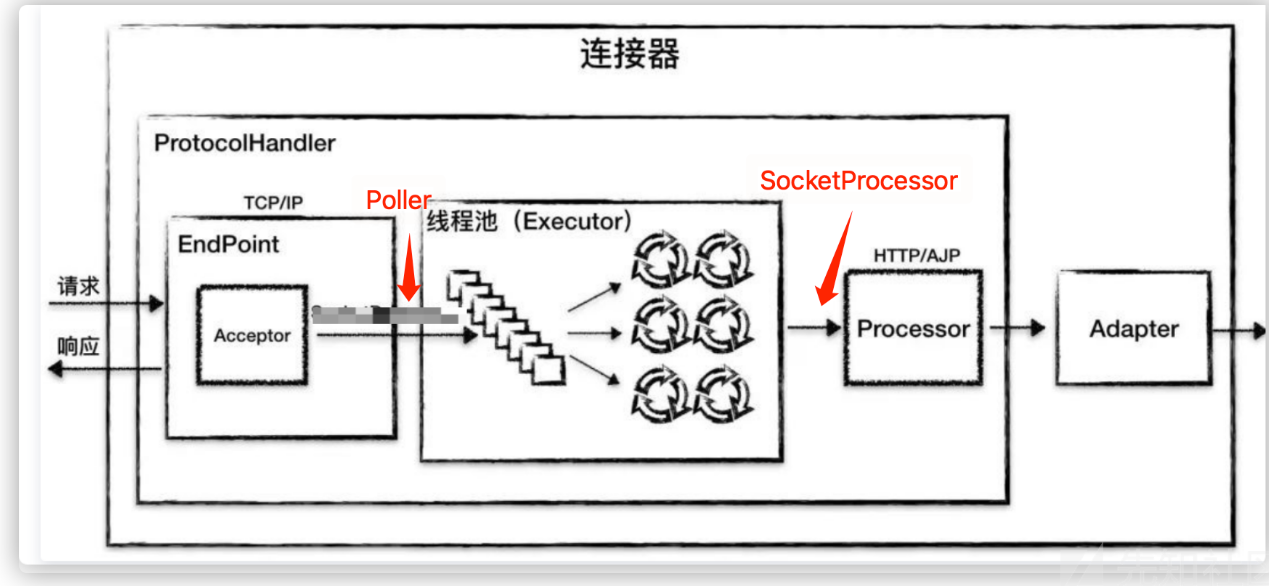
https://github.com/Kyo-w/trojan-eye这里借用深蓝师傅的图片,Poller作为TCP连接最前置的处理类,此类能够直接处理socket上完整的原始数据。我尝试过Acceptor,但是由于Acceptor只是做监听8080端口把请求的socket连接转发给Poller来处理,所以不太可能实现自定义的Acceptor来完成内存马注入。至于实现为什么不采用Executor,我从以下几点考虑:
- Poller能够决定是否提交给web业务处理,Executor是要经过web业务处理,Poller能灵活地决定web业务流程
- Executor的流程是要经过Poller的,所以意味着性能上要比Poller多几道判断与注册
- Poller存在的问题,Executor也存在,所以复杂度基本差不多
但是Executor比Poller有个非常大的优势:Executor鲁棒性比Poller好。原因很简单,Poller是全局唯一的线程(tomcat8、9/springboot),如果线程处理逻辑的时候出现不可预测的异常,线程就会终止,一旦线程终止,整个tomcat的服务直接崩溃,因为缺少了接收与创建任务的执行线程。这也就是说注入Poller的内存马一定是不能出任何bug的,一旦出了,整个服务直接崩溃。在起初做试验时,经常因为木马报错,导致整个服务不能访问,只能重启服务解决,所以风险很高!反向,Executor是一个任务类,创建后就执行一个线程任务,如果这次业务异常,最多这次的请求无法正常执行罢了。那究竟怎么写一个Poller内存马呢?其实很简单:继承Poller+重写processKey方法。(可参考
https://github.com/Kyo-w/trojan-eye/blob/master/theory/README.md)
上面的代码中,super.processKey(sk, attachment)就是会创建SocketProcessor,然后执行web业务逻辑。所以如果你需要在web业务处理之前做些什么,你就在super.processKey(sk, attachment)之前写自己的业务。如果不想执行web业务,直接return即可。如果你需要在web业务处理之后做些什么,就在super.processKey(sk, attachment)之后添加。但是需要注意的是:super.processKey(sk,attachment)是一个“启动任务线程的函数”。在调用完super.processKey(sk,attachment)之后,程序并不会等待业务的响应结果,而是直接结束processKey函数(底层就是后台开线程执行web业务,所以是一个多线程的环境)。就是这个原因,导致我们无法完成这样一个功能:等待web业务执行结束,然后查看web业务的响应结果。因为两个线程之间如果没有通信等机制,我们无法预测线程之间的执行顺序的。这个问题让我受阻了挺长的时间,如果我们只能拿到每一个流量的请求而拿不到响应,显得有点无意义了。所以经过一番思考,我终于找到新的突破点:buffer缓存的利用。
buffer缓存+websocket实现实时流量获取如果要实现读取业务所有的流量,我们要解决两个问题:
- 每次请求的request/response怎么获取
- 每次请求的请求/响应数据应该传输到哪里
针对第一个问题,其实很好解决。
每次请求到来,socket都会有一个bufHandler,而这个bufHandler存储的是上一个请求和响应。但是在高版本中,request的buffer并不记录数据。所以,这里只能通过深蓝师傅文章的unread函数去将本次请求的数据装载到缓存中。
ByteBuffer allocate = ByteBuffer.allocate(8192);try { read = attachment.read(false, allocate);} catch (IOException e) {} ByteBuffer allocate1 = ByteBuffer.allocate(read);// 有多少数据就放多少数据 allocate1.put(allocate.array(), 0, read); allocate1.position(0); attachment.unRead(allocate1); allocate.clear();
- 如果只是通过短连接,然后每次请求去读取buffer,显然我们获取的流量都是零散的,流量是不实时的
- 短连接会造成大量的HTTP请求,容易出现流量异常问题
- 由于发送大量的HTTP请求,我们可能获取的是自己的请求流量
upstream BACKEND { server 127.0.0.1:8080 weight=1 max_fails=2 fail_timeout=30s; keepalive 3000; } map $http_upgrade $connection_upgrade{ default upgrade; '' close; }
既然我们控制的是socket,理论我们是可以构造传输层上的各种协议,但是还是不得不面对现实的情况:我们的业务依旧面对的是NGINX之类的反向代理,而NGINX默认支持的协议并不支持各种高层的应用层协议,换句话说,我们只能尽可能用业务中NGINX代理最常见的协议进行通信,但是原生的HTTP已经无法做到我们的需求了。Keep-Alive虽然可以,但是也会面对几个问题:
- 连接超时。这就需要客户端实时发送心跳以维持socket的通信。
- 我们需要响应适合的响应体,由于控制整个连接过程,所以导致响应体都是由我们自己封装返回客户端,而自己封装的响应,很容易导致出现统一的特征(涉及到响应的模板)。
当然在NGINX 1.9.0版本以后,已经支持对TCP协议代理的支持
stream{ upstream test{ #这里代理socket,其端口是3307 server 127.0.0.1:3307 weight=1; #server x.x.x.x:1111 weight=1; } server { #监听3306端口 listen 3306; proxy_pass test; }}
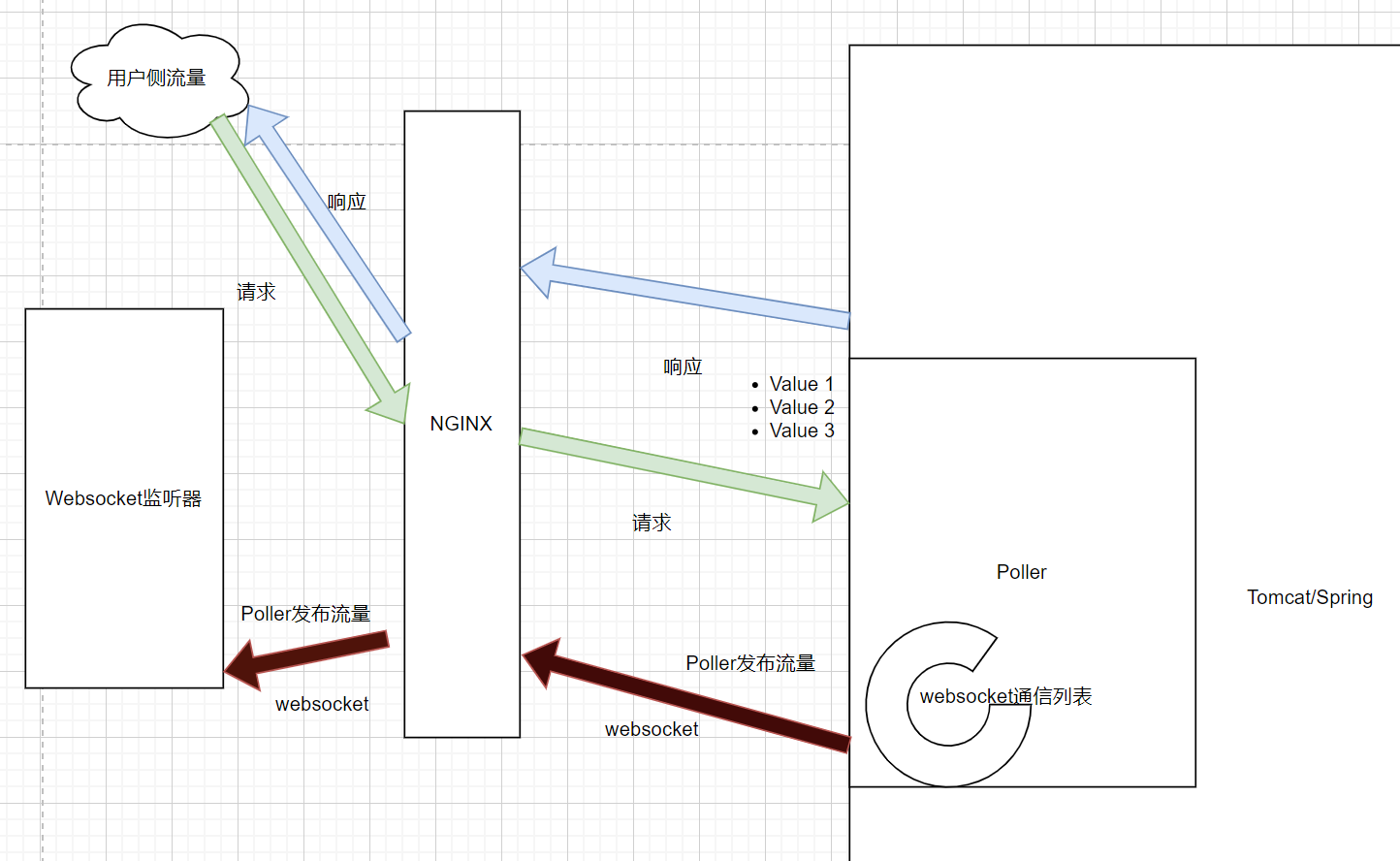
但是既然是做工具的,那必然要尽可能降低环境的需求。所以必须寻找其他更常见的协议。幸好在前段时间已经有师傅找到了新的内存马——websocket。看到websocket,让我顿时有了灵感,websocket本身就是会常见于一些web应用,这势必然增加了工具的适用范围,并且websocket在HTTP代理的日志中只能看到一条记录(由于websocket在做完一次协议升级后,就不再使用HTTP进行传输了)。所以立刻展开深入的研究,以下是整个内存马通信的核心。
下面是NGINX配置websocket的配置(供学习参考)
server { listen 80; #域名 server_name localhost; location /sell { proxy_pass http://127.0.0.1:8080/; // 代理转发地址 proxy_http_version 1.1; proxy_read_timeout 3600s; // 超时设置 // 启用支持websocket连接 proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; }}
从图像中可以看到,每次代理的流量都会经过Poller,Poller会根据存在的websocket通信列表,把上一次请求的所有数据,发送给每一个websocket监听器。现在,整个基本骨架已经基本实现了,剩下的就只剩敲代码了。最后希望这些研究能在攻防起到作用吧!




 发表于 2022-9-3 22:50:45
发表于 2022-9-3 22:50:45