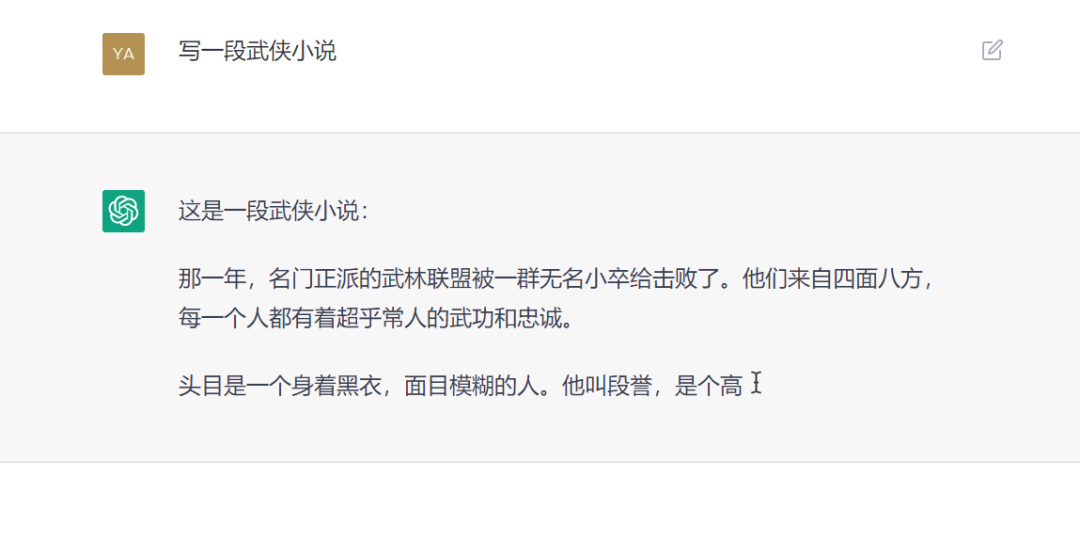
ChatGPT存在哪些局限性?如下:
a) 在训练的强化学习 (RL) 阶段,没有真相和问题标准答案的具体来源,来答复你的问题。
b) 训练模型更加谨慎,可能会拒绝回答(以避免提示的误报)。
c) 监督训练可能会误导/偏向模型倾向于知道理想的答案,而不是模型生成一组随机的响应并且只有人类评论者选择好的/排名靠前的响应
ChatGPT’s self-identified limitations are as follows.
Plausible-sounding but incorrect answers: a) There is no real source of truth to fix this issue during the Reinforcement Learning (RL) phase of training. b) Training model to be more cautious can mistakenly decline to answer (false positive of troublesome prompts). c) Supervised training may mislead / bias the model tends to know the ideal answer rather than the model generating a random set of responses and only human reviewers selecting a good/highly-ranked responseChatGPT is sensitive to phrasing. Sometimes the model ends up with no response for a phrase, but with a slight tweak to the question/phrase, it ends up answering it correctly.
Trainers prefer longer answers that might look more comprehensive, leading to a bias towards verbose responses and overuse of certain phrases.The model is not appropriately asking for clarification if the initial prompt or question is ambiguous.A safety layer to refuse inappropriate requests via Moderation API has been implemented. However, we can still expect false negative and positive responses.




 发表于 2022-12-12 18:56:47
发表于 2022-12-12 18:56:47