|
|
[AI安全论文] 26.基于Excel可视化分析的论文实验图表绘制总结——以电影市场为例 (qq.com)
前文详细介绍了向量表征系列文章,从Word2vec和Doc2vec到Deepwalk和Graph2vec,再到Asm2vec和Log2vec。这篇文章将描述Excel可视化分析的基本知识,以2022年电影市场为例。在论文中,一个好的图表胜千言万语,而实验数据生成后如何可视化表示至关重要,之前作者通常利用Python、Echarts等编写代码实现,而这篇文章将利用Excel生成,不论是代码、工具还是Office,它们都只是论文的辅助工具,更重要的是论文的创新和实验所生成的结果。
基础性文章,希望您喜欢。一方面自己英文太差,只能通过最土的办法慢慢提升,另一方面是自己的个人学习笔记,并分享出来希望大家批评和指正。希望这篇文章对您有所帮助,这些大佬是真的值得我们去学习,献上小弟的膝盖~fighting!
  编辑 编辑
文章目录:
- 一.论文实验图表的重要性
- 二.柱状图绘制
- 三.饼图绘制
- 四.折线图绘制
- 五.条形图绘制
- 六.词云图绘制
- 七.方框图绘制
- 八.重点:四象限图绘制
- 九.重点:演员关系图谱绘制
- 十.总结
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正。同时,前期翻译提升为主,后续随着学习加强会更多分享论文的精华和创新,在之后是复现和论文撰写总结分析。希望自己能在科研路上不断前行,不断学习和总结更高质量的论文。虽然自己科研很菜,但喜欢记录和分享,也欢迎大家给我留言评论,学术路上期待与您前行,加油~
前文推荐:
一.论文实验图表的重要性个人认为,实验部分同样重要,更重要是如何通过实验结果、对比实验、图表描述来支撑你的创新点,让审稿老师觉得,就应该这么做,amazing的工作。作为初学者,我们可能还不能做到非常完美的实验,但一定要让文章的实验足够详细,力争像该领域的顶级期刊或会议一样,并且能够很好的和论文主题相契合,这样文章的价值也体现出来了。
- 对于结果的呈现,作图是特别重要的,一张好图胜过千言万语。
图/表的十个关键点(10 key points)
- 说明部分要尽量把相应图表的内容表达清楚
- 图的说明一般在图的下边
- 表的说明一般在标的上边
- 表示整体数据的分布趋势的图不需太大
- 表示不同方法间细微差别的图不能太小
- 几个图并排放在一起,如果有可比性,并排图的取值范围最好一致,利于比较
- 实验结果跟baseline在绝对数值上差别不大,用列表黑体字
- 实验结果跟baseline在绝对数值上差别较大,用柱状图/折线图视觉表现力更好
- 折线图要选择适当的颜色和图标,颜色选择要考虑黑白打印的效果
- 折线图的图标选择要有针对性:比如对比A, A+B, B+四种方法:
A和A+的图标要相对应(例如实心圆和空心圆),B和B+的图标相对应(例如实心三角形和空心三角形)
说明部分要尽量把相应图表的内容表达清楚

图的说明一般在图的下边;表的说明一般在表的上边;表示整体数据的分布趋势的图不需太大;表示不同方法间细微差别的图不能太小。
几个图并排放在一起,如果有可比性,并排图的x/y轴的取值范围最好一致,利于比
较。
实验结果跟baseline在绝对数值上差别不大,用列表加黑体字;实验结果跟baseline在绝对数值上差别较大,用柱状图/折线图视觉表现力更好。
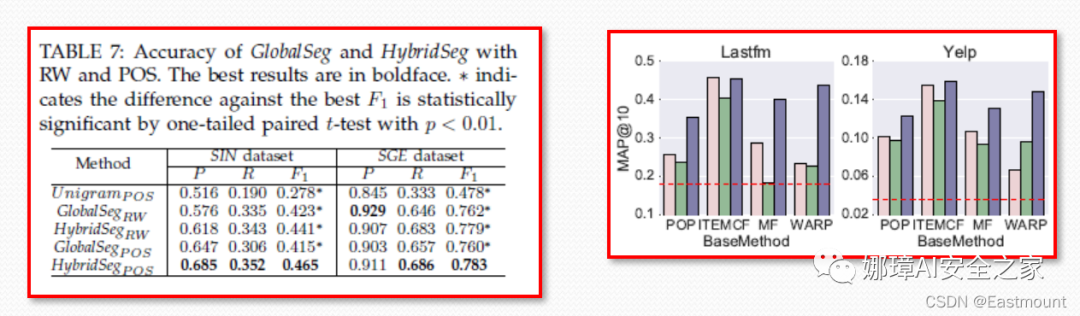
折线图要选择适当的颜色和图标,颜色选择要考虑黑白打印的效果;折线图的图标选择要有针对性,比如对比A, A+,B, B+四种方法。

二.柱状图绘制
Office办公软件具有强大的功能,尤其是绘图方面,包括Excel、PPT、Visio等。下图展示WPS Excel常见的图表类型。
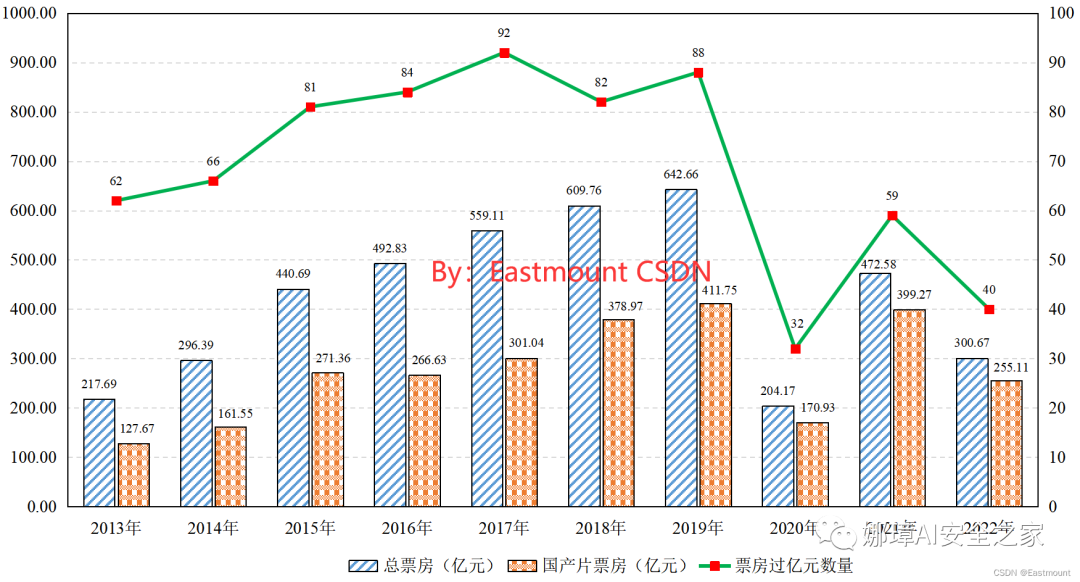
本文以2022年中国电影市场数据为例,介绍基于Excel可视化分析的论文实验图表绘制方法。首先是柱状图,其效果如下图所示。
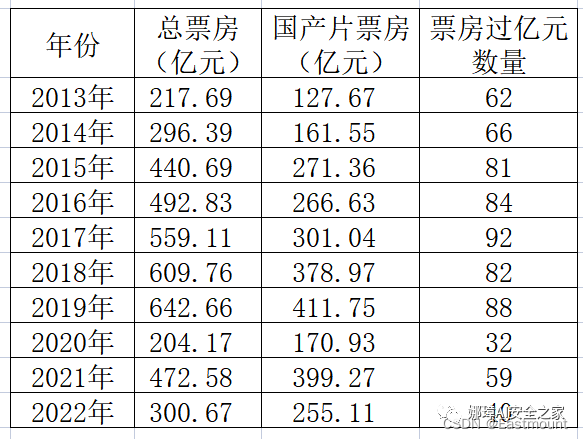
第一步:假设存在如图所示的近十年总票房、国产片票房和票房过亿元电影数量。
第二步:选中表格数据,点击“插入”=>“全部图表”,然后选择包含柱状图和折线图的组合图。
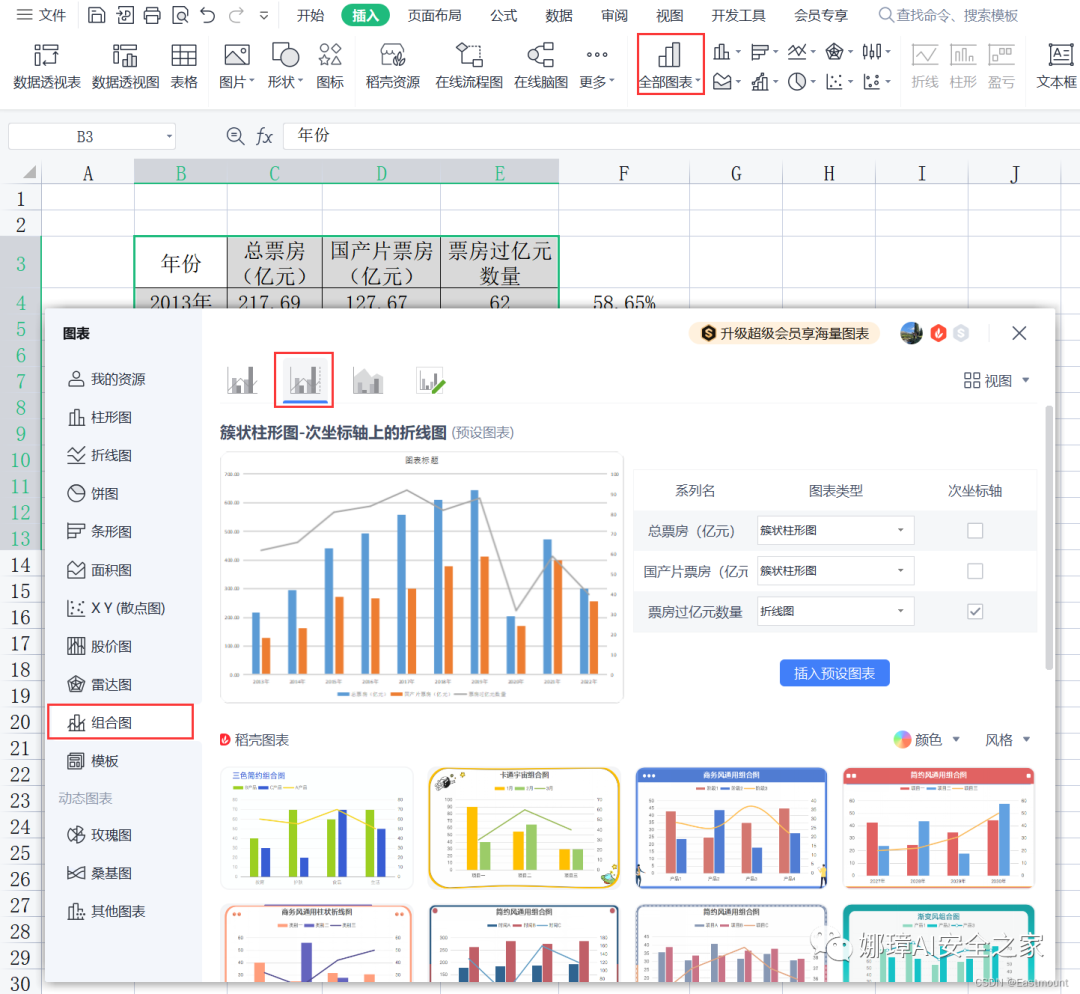
生成结果如下图所示。
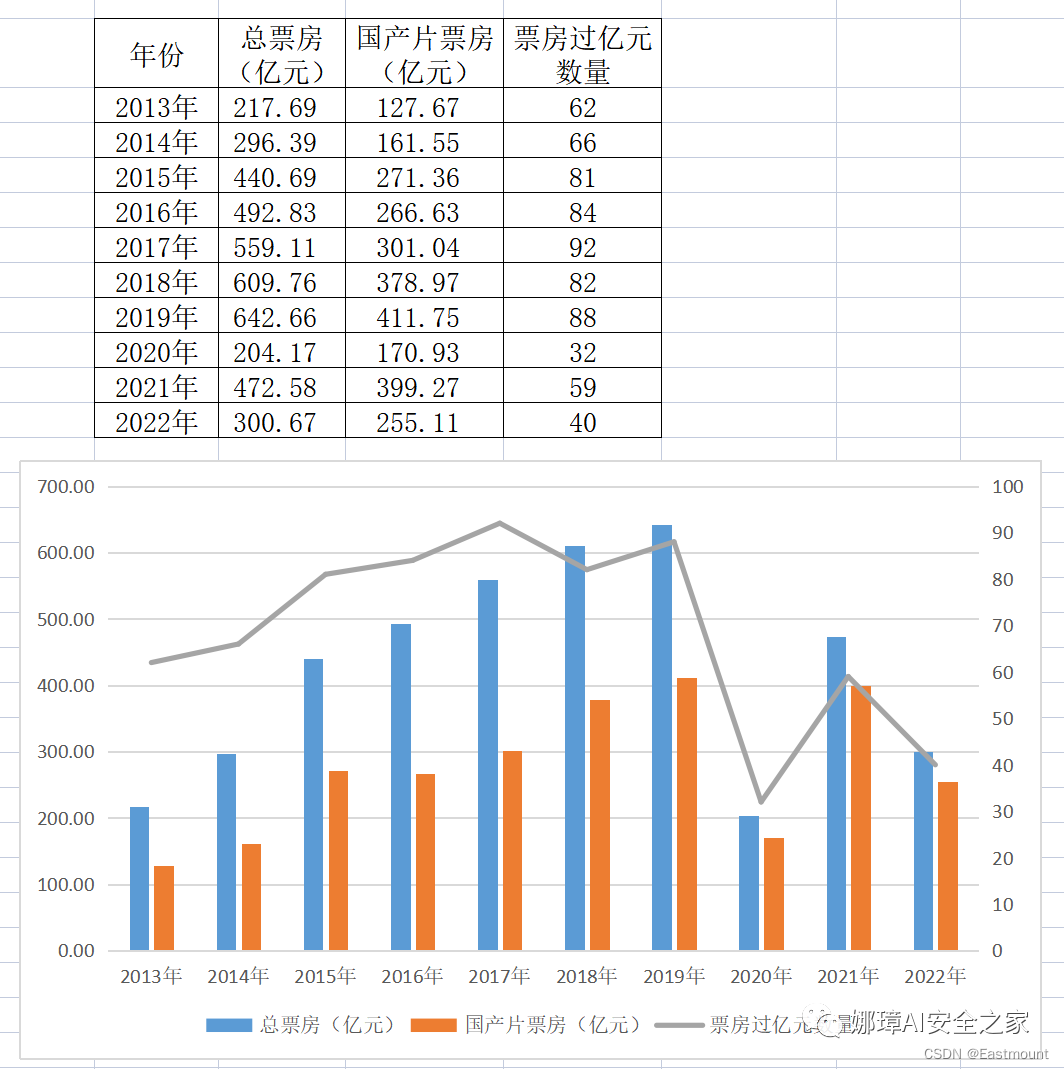
第三步:选中图片,右键“设置数据系列格式”,然后设置字体颜色、表格线条等内容。
设置颜色如下图所示:
第四步:设置柱状图的填充图案、间距、线条等内容,设置左右坐标轴的刻度,让图像更饱满。
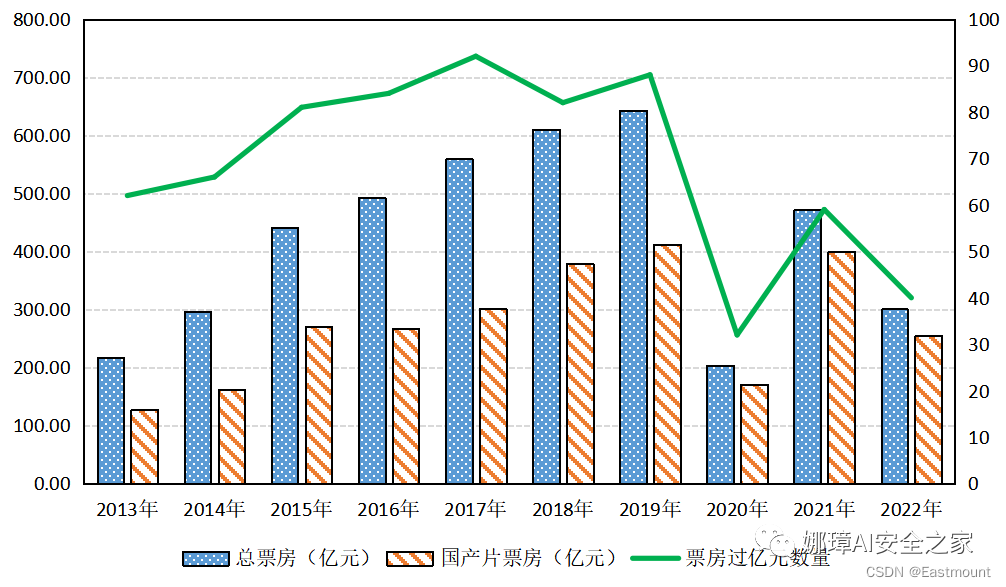
此时效果图如下所示:
第五步:添加数据标签,这里需要设置折线图节点的形状,在“填充与线条”=>“标记”的“数据标记选项”中设置,如下图所示:
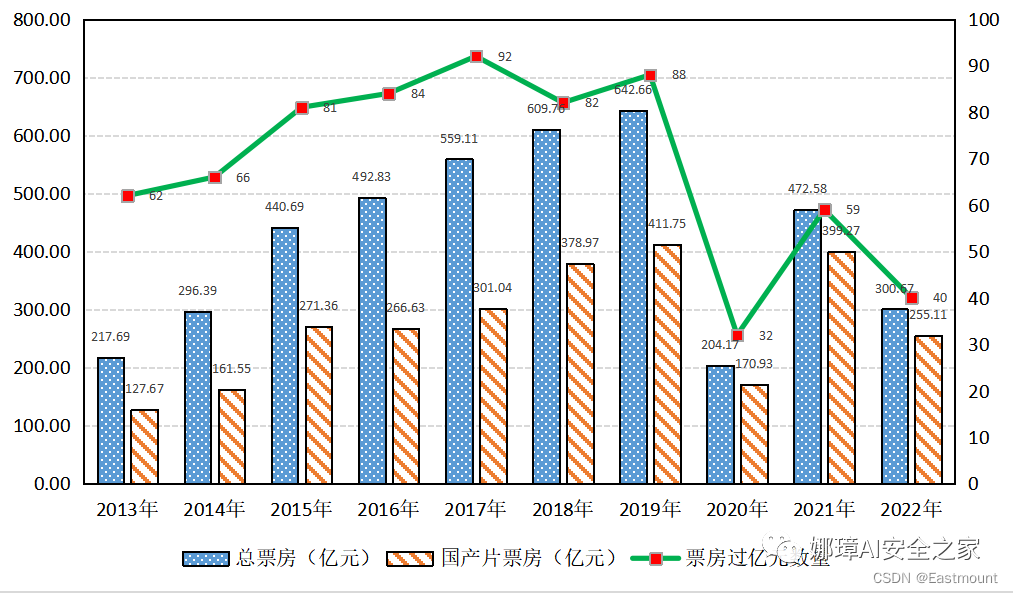
最终效果如图所示:
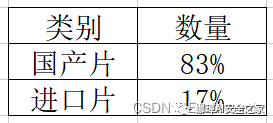
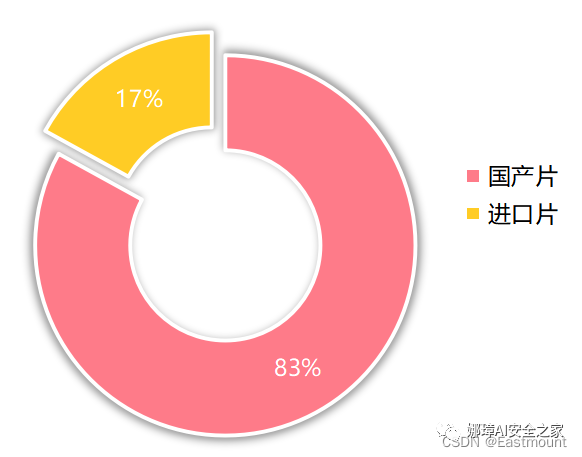
三.饼图绘制饼图绘制效果如下图所示:

第一步:假设存在2022年国产片和进口片的占比。
第二步:选中表格数据,点击“插入”=>“全部图表”,然后选择饼图。
第三步:为更好地区分区域,设置形状及格式即可。
四.折线图绘制折线图绘制效果如下图所示:
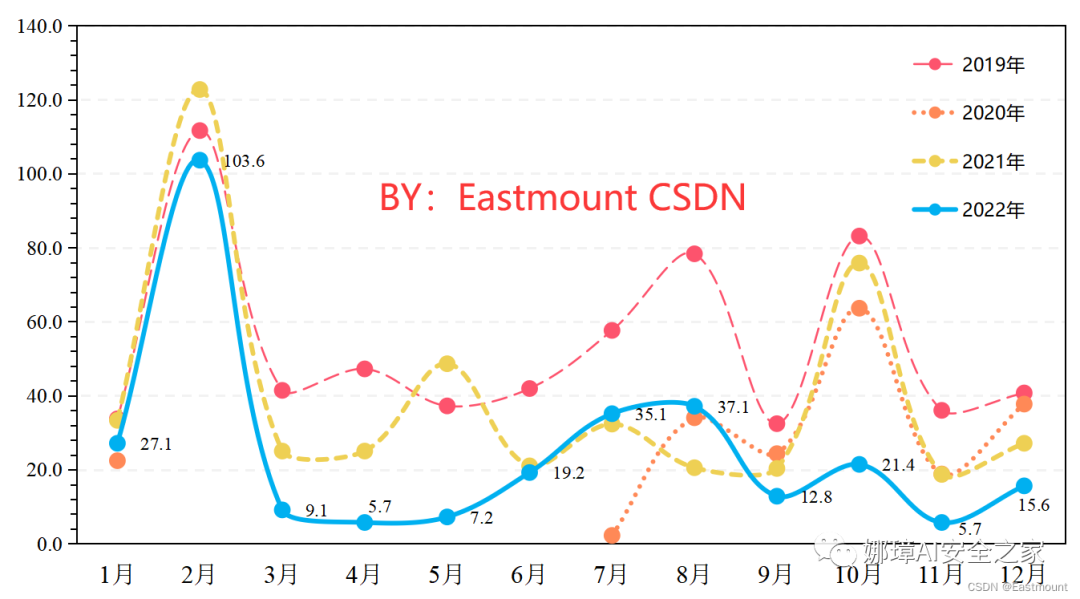
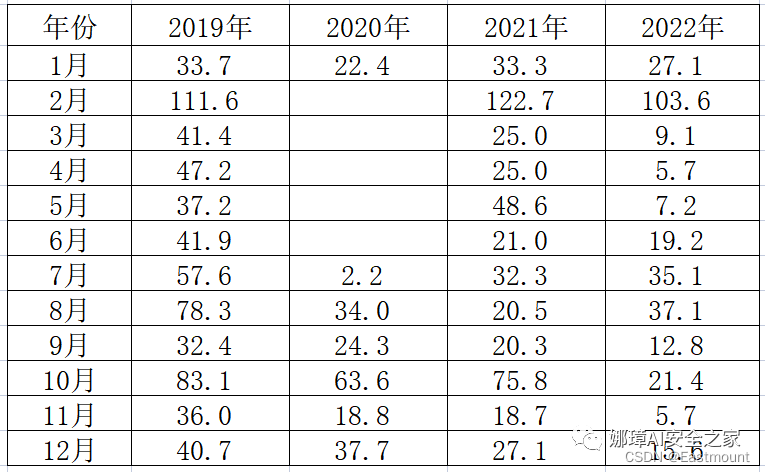
第一步:假设存在近四年中国内地电影市场每月票房数据,如下图所示,我们需要对比折线图变化趋势。
第二步:选中表格数据,点击“插入”=>“全部图表”,然后选择带节点的平缓折线图。
如下图所示:
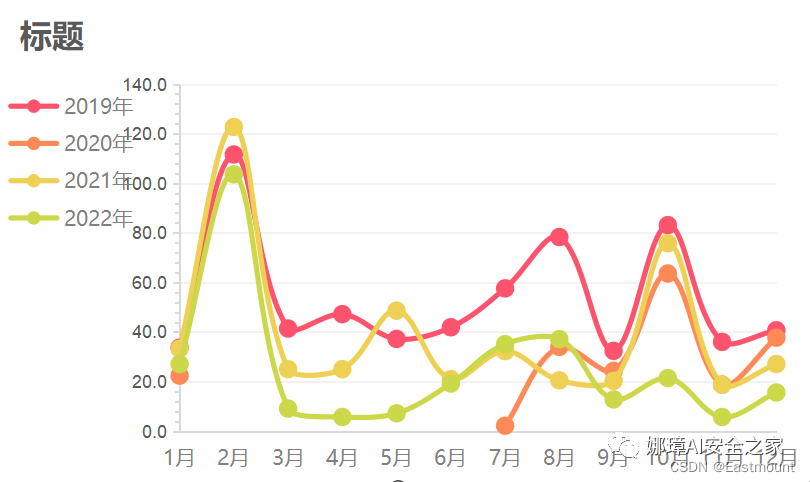
第三步:设置折线的形状、格式并添加数据标签。
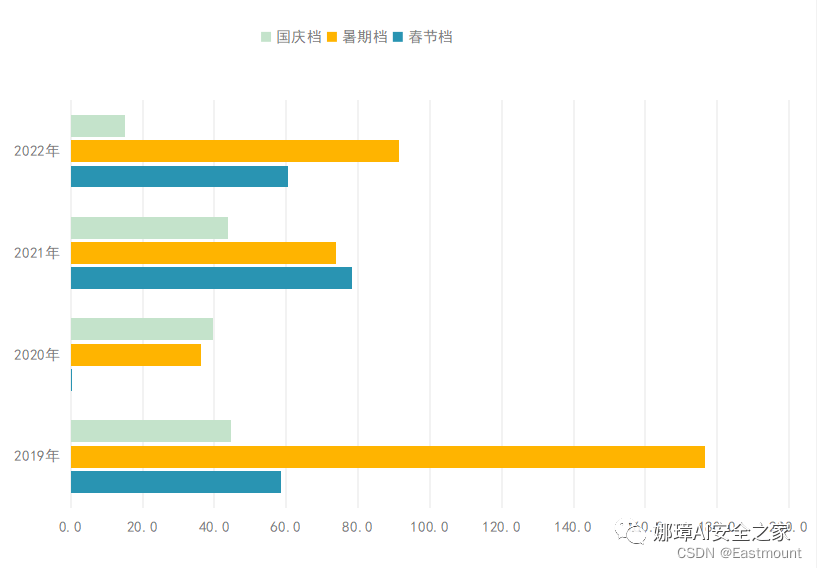
五.条形图绘制为更好地比较近四年三大黄金档期票房,绘制如下图所示的条形图。

第一步:假设存在近四年中国内地电影市场三大黄金档期票房。
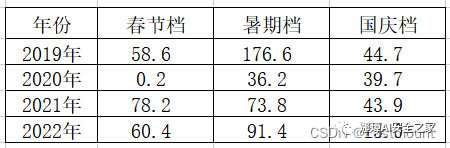
第二步:选中表格数据,点击“插入”=>“全部图表”,然后选择条形图。
第三步:设置条形图的格式即可。
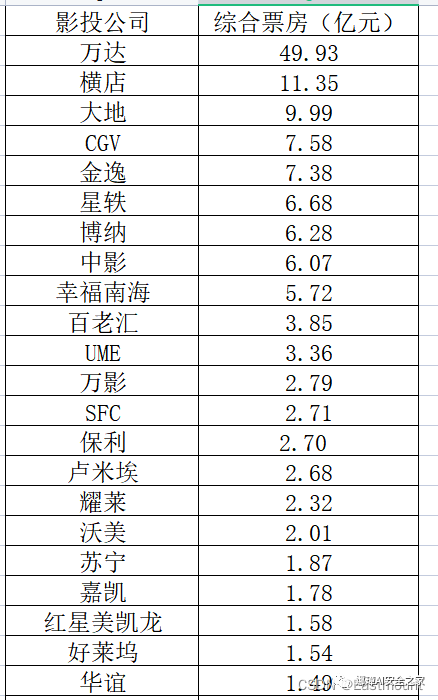
六.词云图绘制为更好地评估影投公司2022年对中国电影的贡献,绘制如下图所示的词云图。先前的词云通常利用Python调用WordCloud库或PyEcharts实现,Excel如今也具备该功能。

第一步:假设存在影投公司的综合票房数据。
第二步:选中表格数据,点击“插入”=>“全部图表”,然后从其它图表中选择词云图。
此时的效果如下图所示:

第三步:选择图像右键,设置不同字体的颜色及格式。
七.方框图绘制玫瑰方框图绘制效果如下图所示:
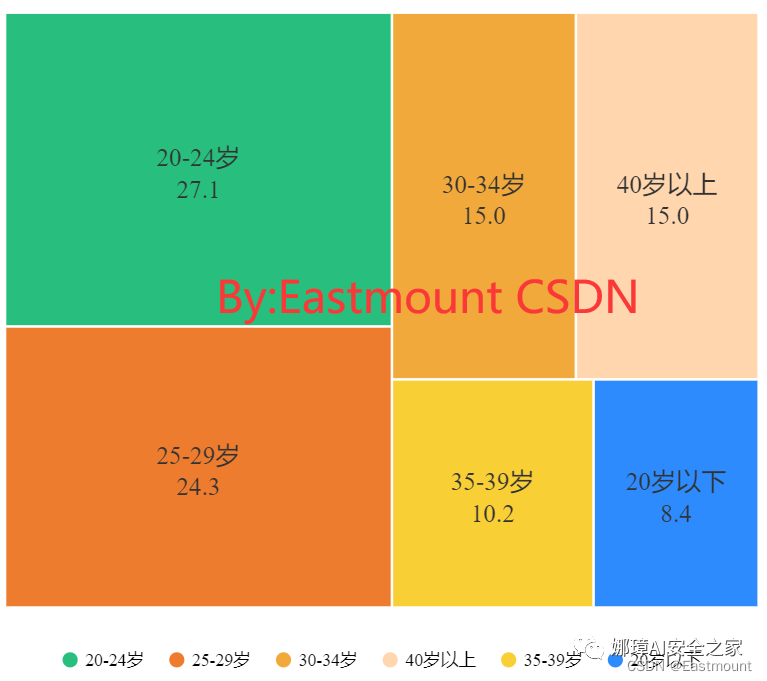
第一步:假设2022年总票房前十的观众年龄画像如下图所示。
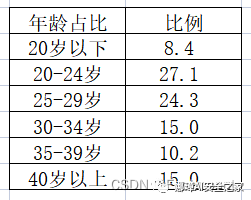
第二步:选中表格数据,点击“插入”=>“全部图表”,然后从其它图表中选择方框图。

第三步:设置字体大小及垂直居中即可。
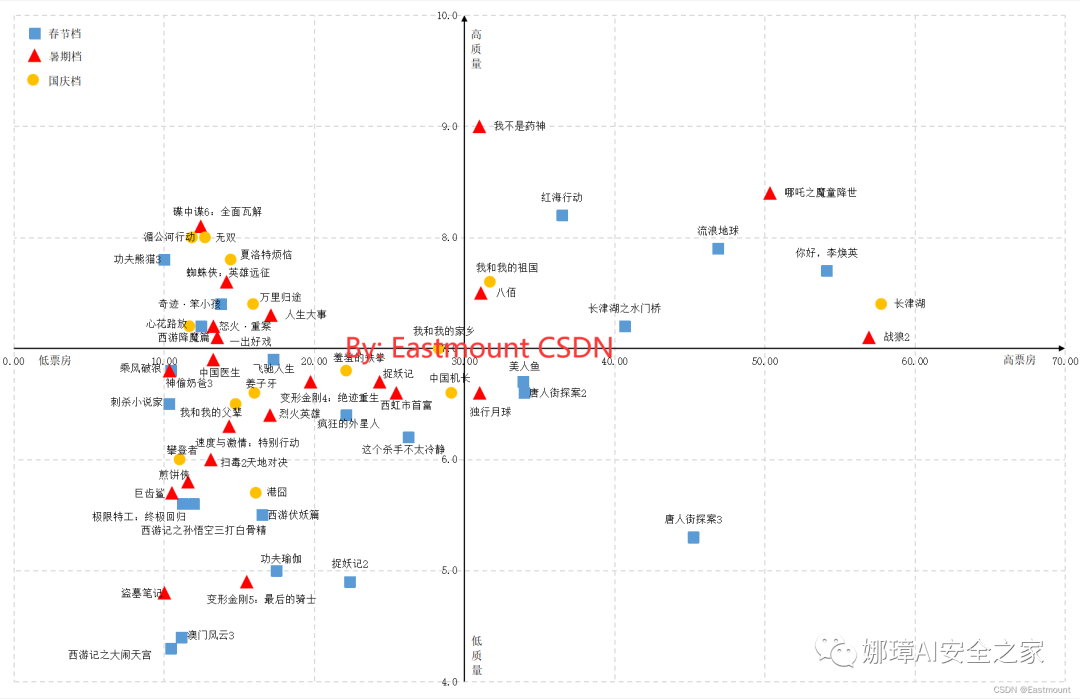
八.重点:四象限图绘制如果读者认为Excel仅能绘制简单的图形,那就错了。接下来我们利用Excel绘制一个比较难的图形——四象限图,通过该图来评估电影的用户画像,从票房和豆瓣评分两个角度介绍,也是本文的重点。效果图如下所示:
第一步:假设存在春节档和国庆档电影票房超10亿元的影评信息,如下图所示。我们将票房大于30亿元的定位超高票房电影,豆瓣评分大于7的认为高质量电影。那么,如何绘制四象限图呢?
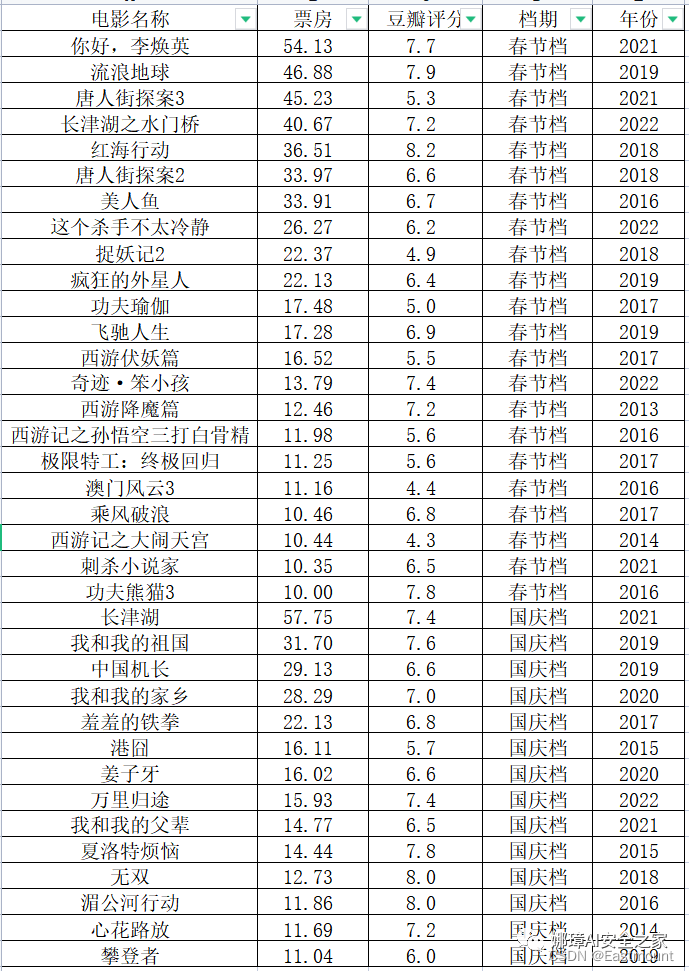
第二步:选中春节档票房和豆瓣评分两列电影数据,然后添加带坐标的散点图。
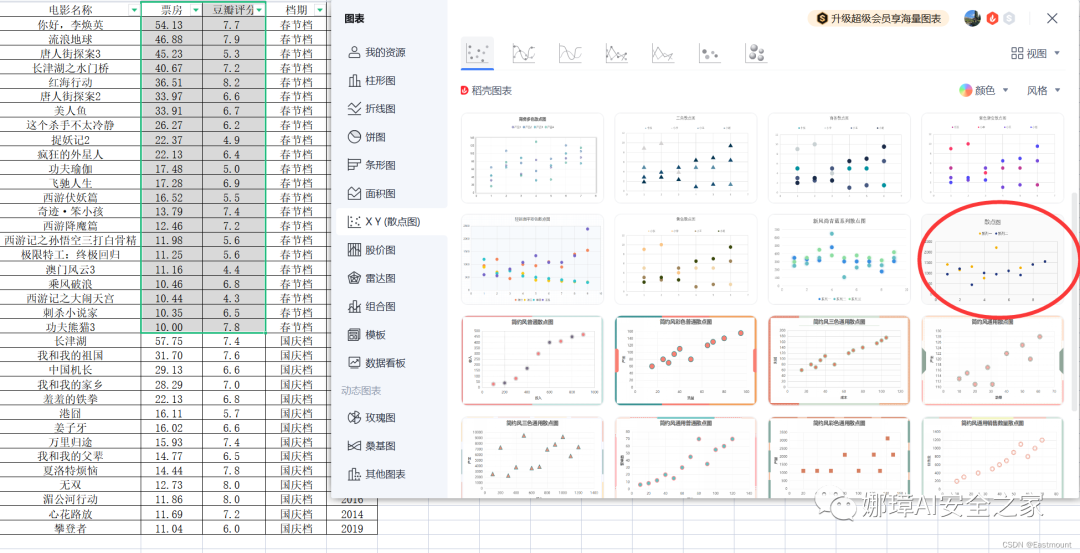
如下图所示:
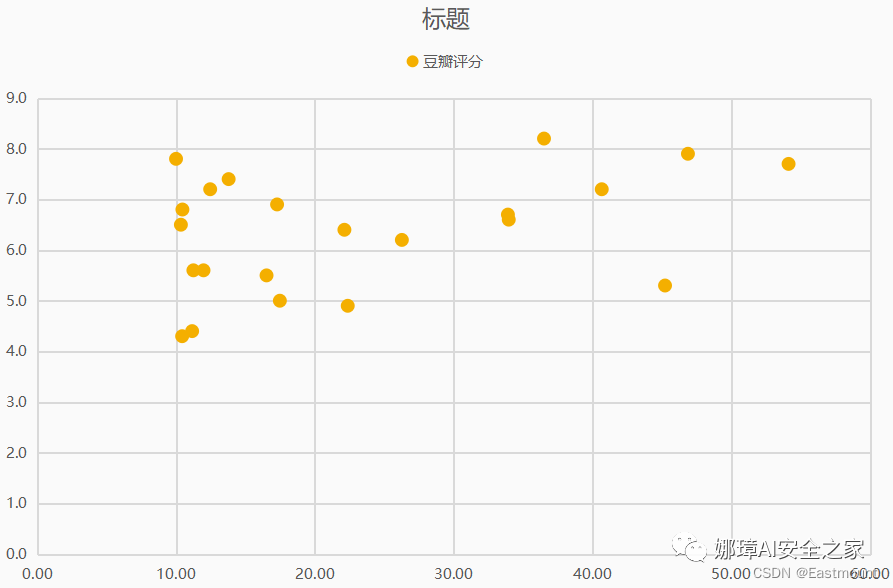
第三步:选中坐标轴右键“设置坐标轴格式”,设置横坐标(票房)“坐标轴值”为30亿元。
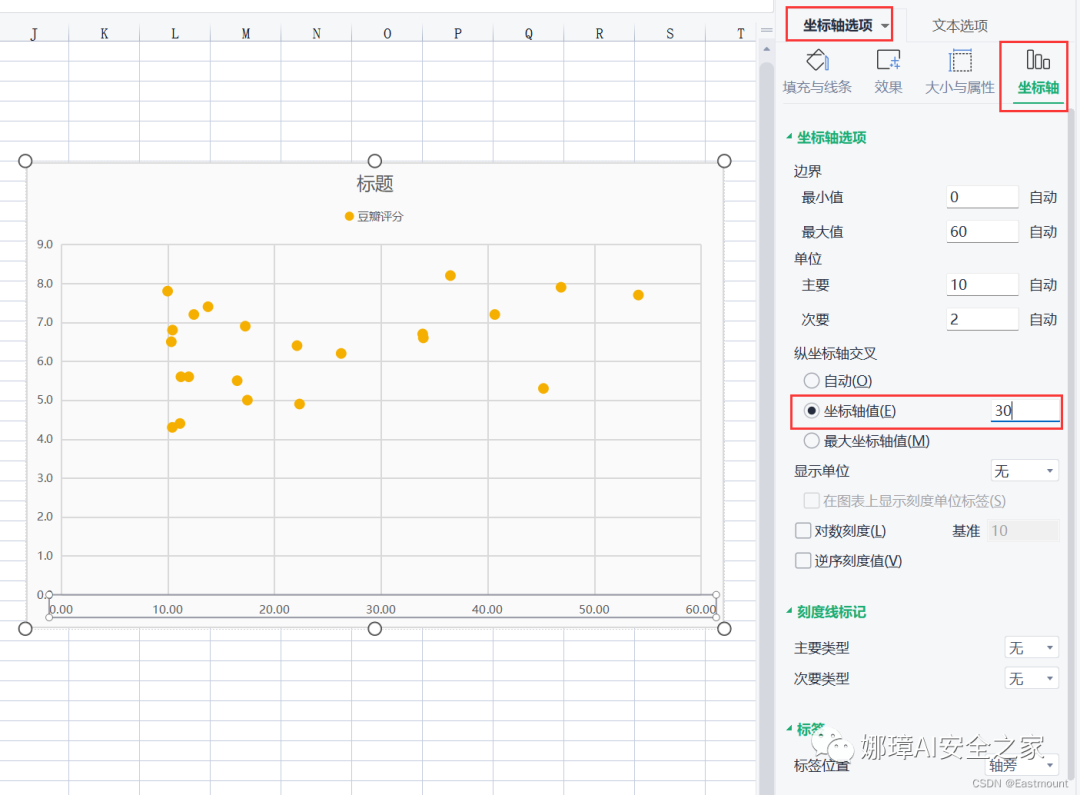
接着设置评分为7,此时效果如图所示。
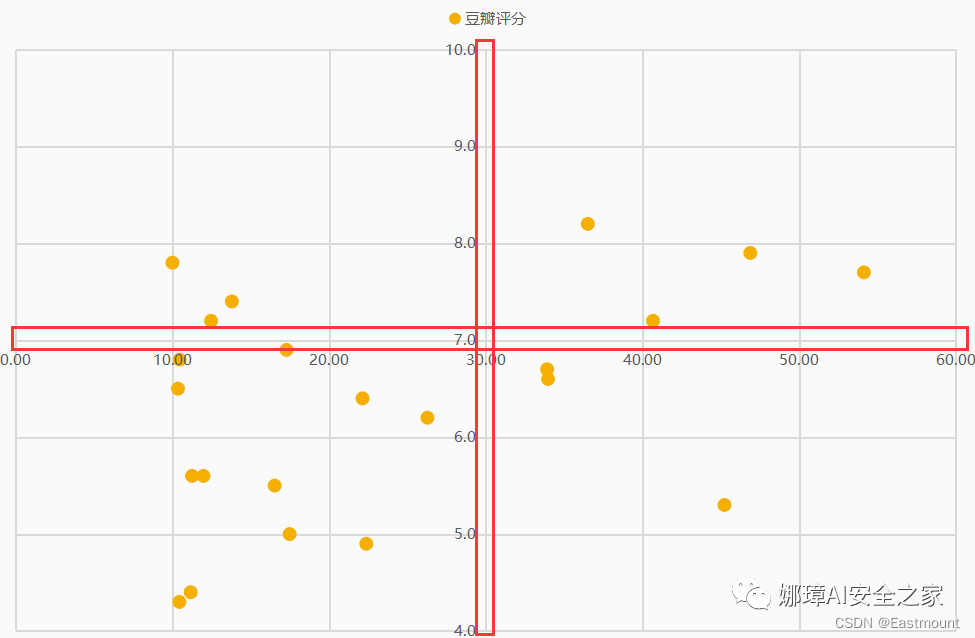
第四步:为节点添加标签,即电影名称。右键选中节点,然后添加数据标签,如下图所示。那么,如何将评分替换为电影名称呢?
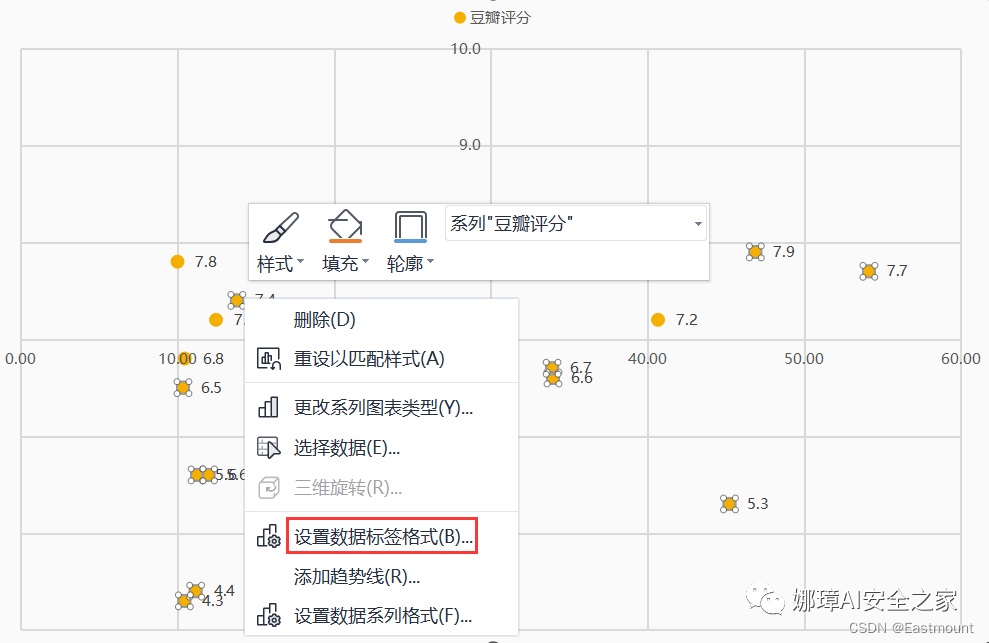
第五步:继续选中节点,右键“设置数据标签格式”。在“标签包括”选项中勾选“单元格中的值”。
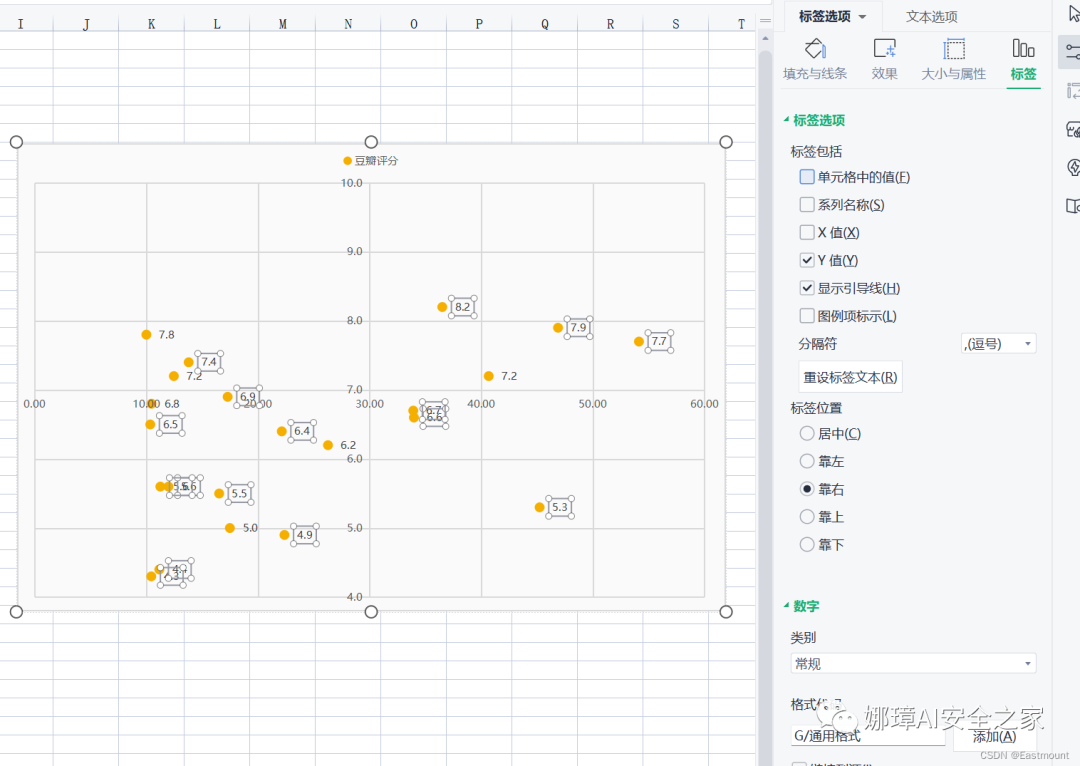
然后选择在弹出的数据标签区域中选择电影名称,如下图所示:
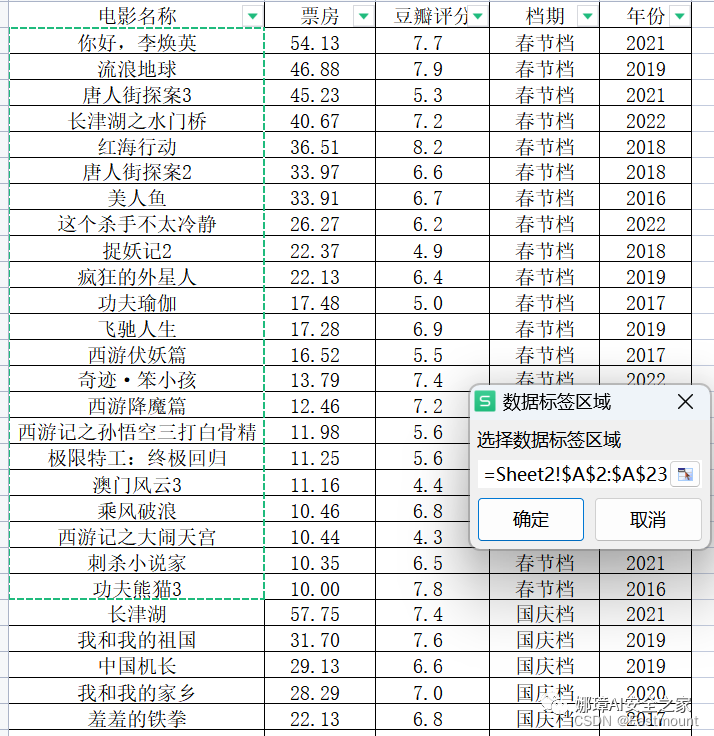
接着在右类标签设置中仅显示“单元格中的值”,显示效果如下图所示:
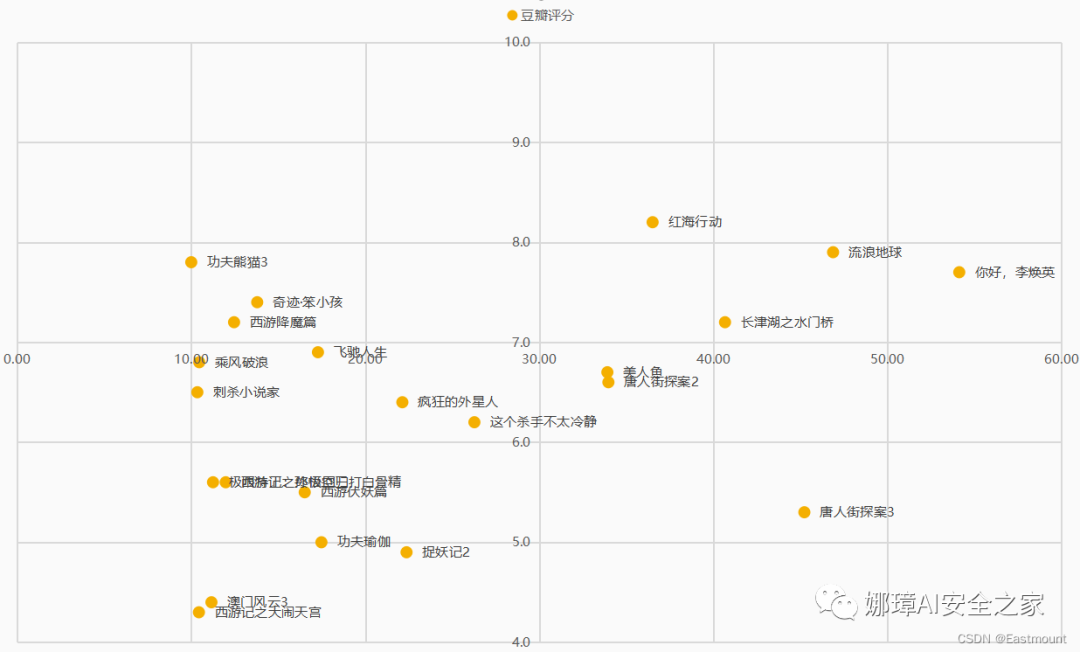
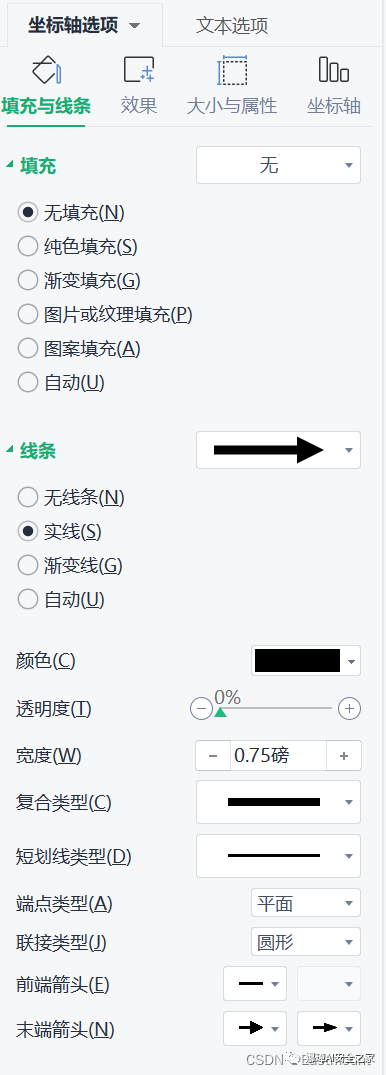
第六步:设置坐标轴的格式,含颜色、字体、线条等类型,并添加箭头。
此外,重合的标签区分下,显示效果如下图所示:
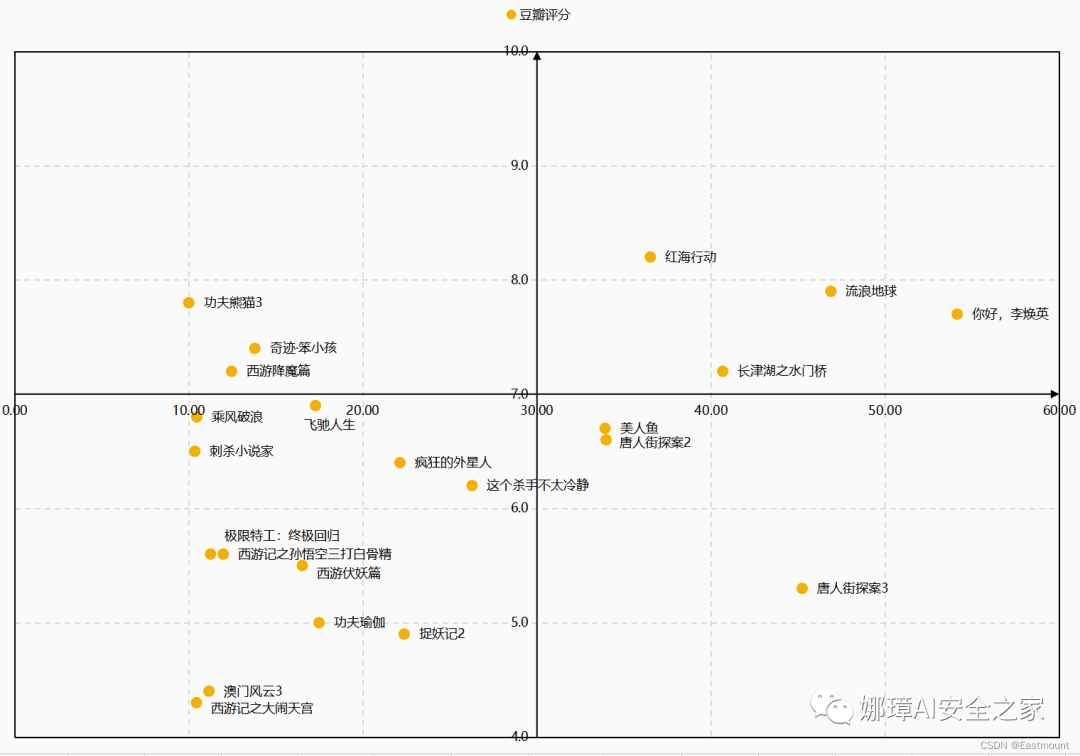
第七步:添加国庆档的数据,按照上述方法再进行设置。右键“选择数据”。

添加数据。
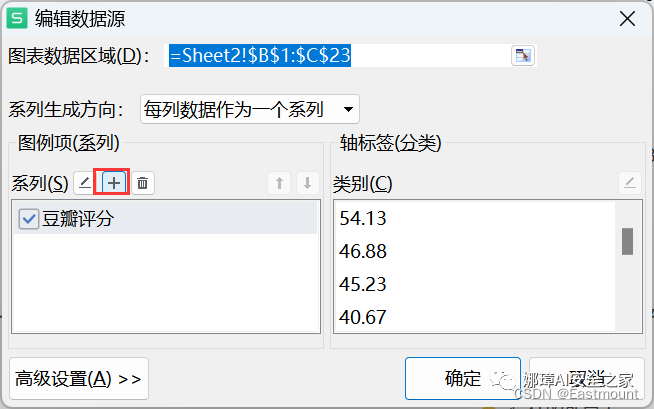
选择两列对应数据。
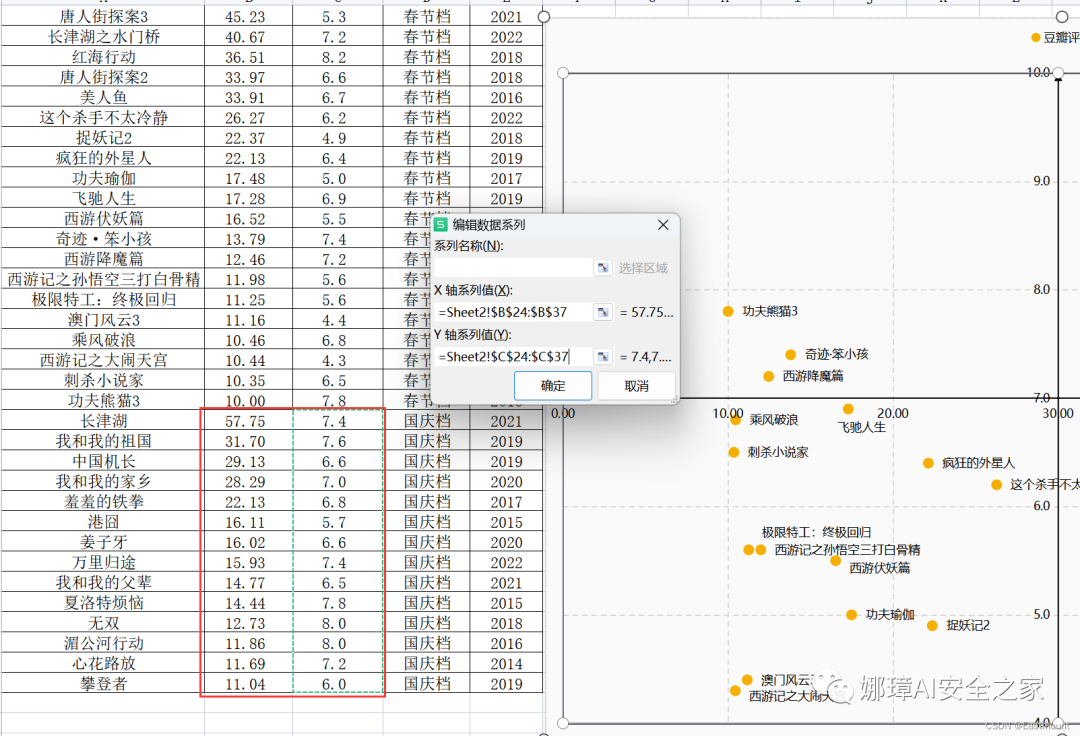
点击确定后新增节点,如下图所示。
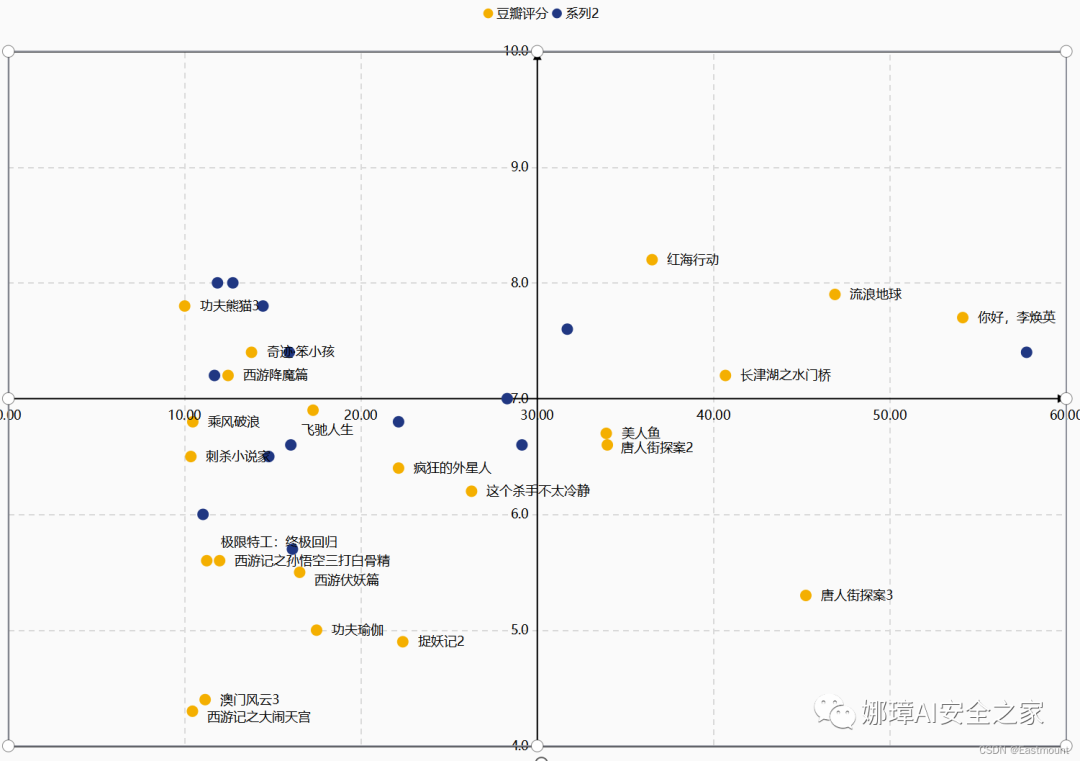
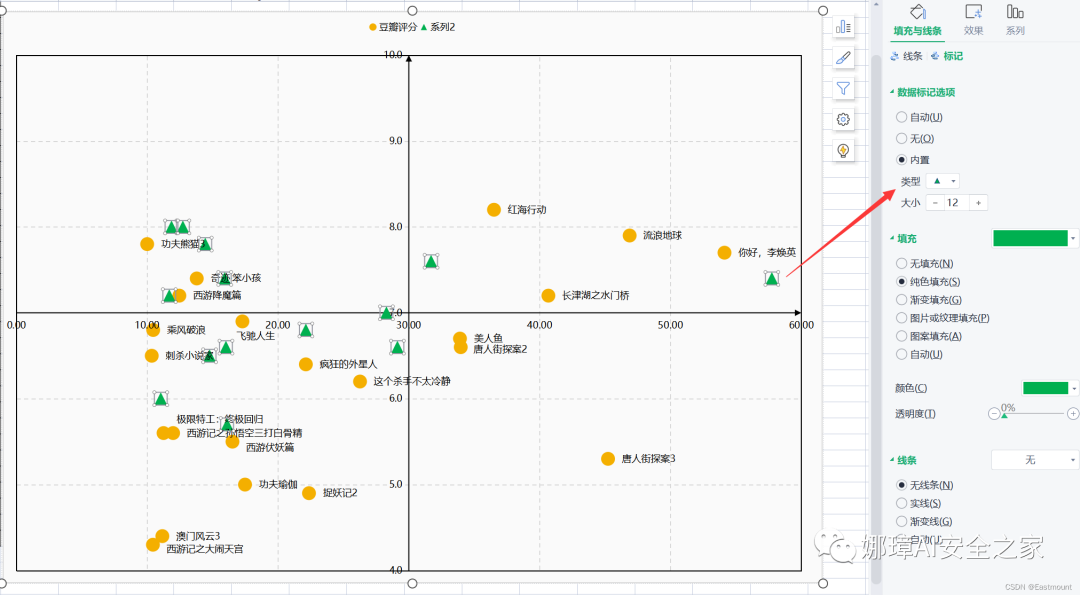
第八步:设置节点格式,以区分春节档和国庆档。
最终通过上述设置如下图所示:
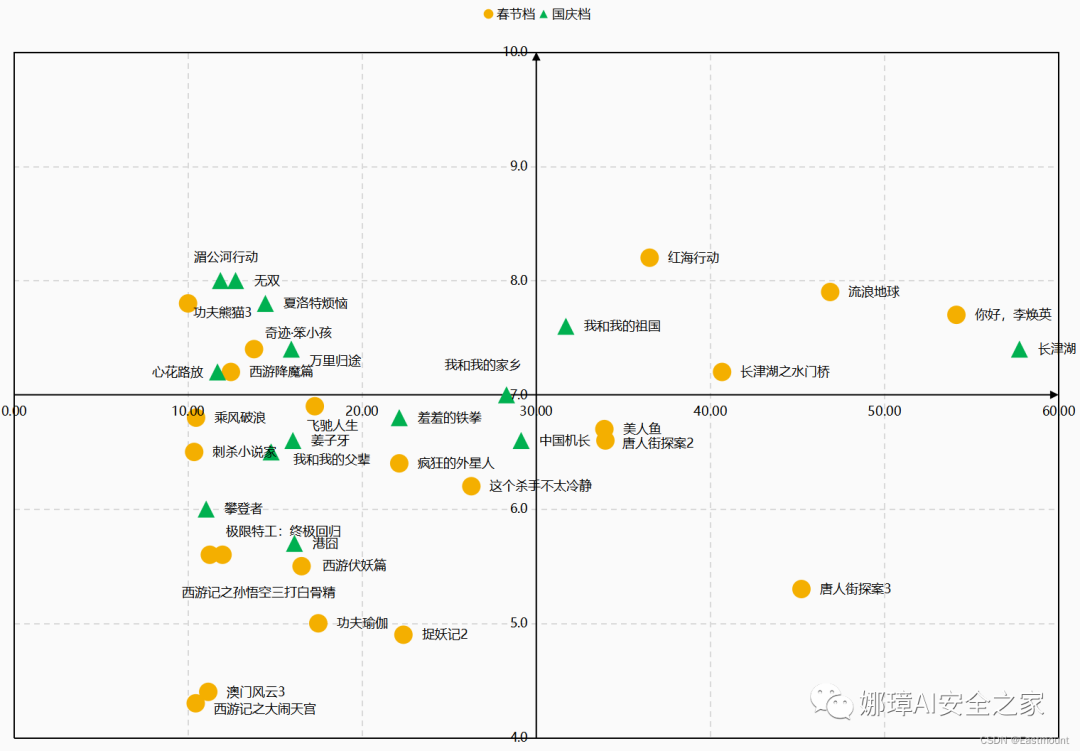
三个档期对比图如下所示:
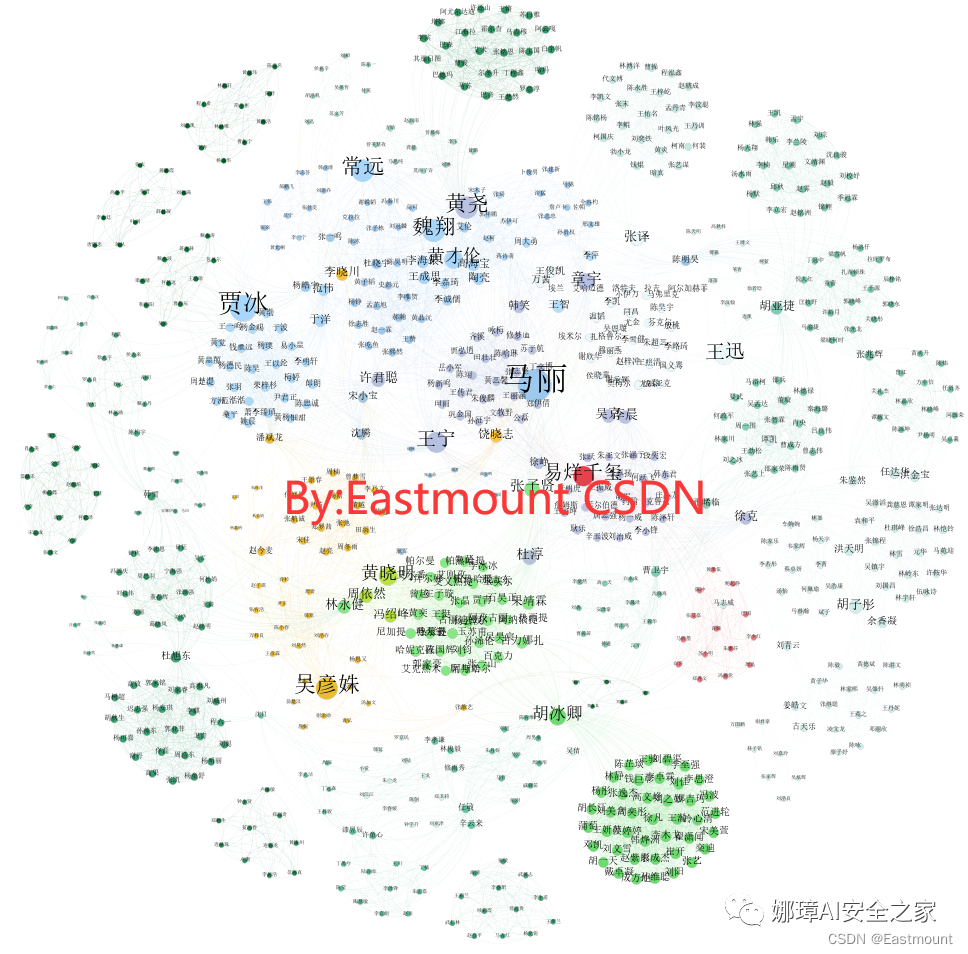
九.重点:演员关系图谱绘制最后,本文将补充演员关系图谱,它也是电影产业分析的重要内容,如下图所示。
第一步:假设存在2022年所有电影的演员统计表,如下图所示。演员和导演可以通过豆瓣填写。
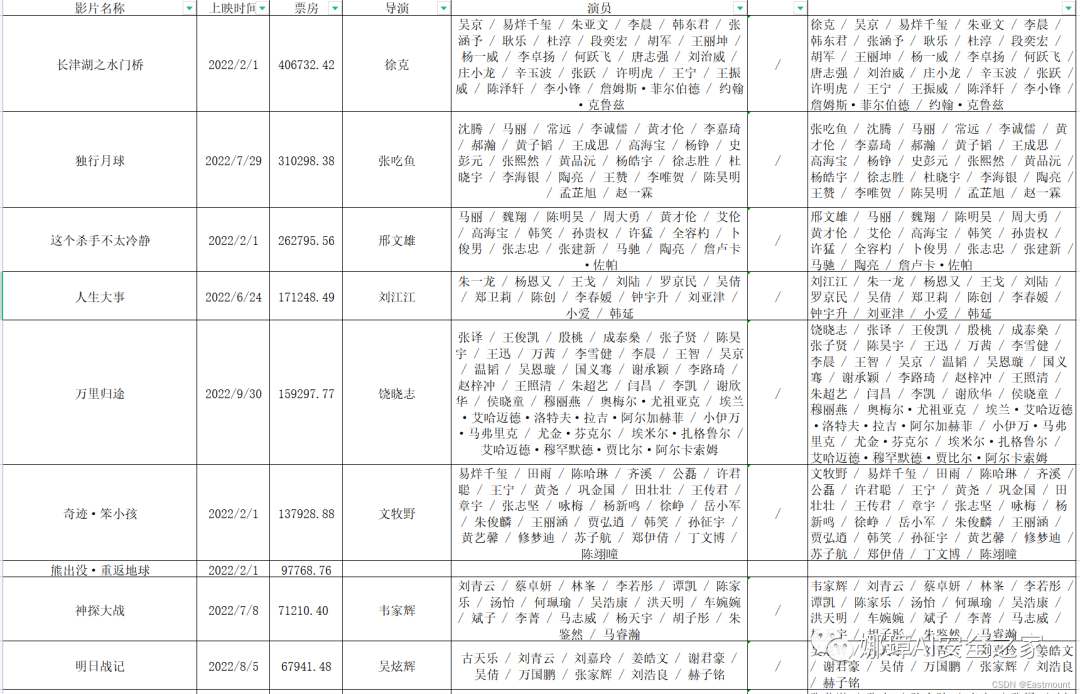
第二步:将演员信息复制到data.txt中(仅部分),然后撰写代码提取演员两两合作关系。

- #coding:utf-8
- import csv
- import os
- import time
- import numpy as np
- from scipy.sparse import coo_matrix
- from collections import Counter
- def get_feature(fr_name,fw_name):
-
- #记录关键词
- word = []
- all_str = ""
- fr = open(fr_name,"r",encoding="utf-8")
- #---------------------------------------------------------------------------
- #读取数据
- for line in fr.readlines():
- line = line.strip()
- line = line.replace("\n", "")
- all_str += line + "/"
- for n in line.split("/"):
- if n not in word:
- word.append(n)
-
- fr.close()
- print(len(word)) #关键词总数
- print(word)
- #数量统计
- all_words = all_str.split("/")
- c = Counter()
- for x in all_words:
- if len(x)>1 and x != '\r\n':
- c[x] += 1
- print('\n词频统计结果:')
- for (k,v) in c.most_common(20):
- print("%s:%d"%(k,v))
- #采用coo_matrix函数解决该MemoryError矩阵过大汇报内存错误
- word_vector = coo_matrix((len(word),len(word)), dtype=np.int32).toarray()
- print(word_vector.shape)
-
- #---------------------------------------------------------------------------
- #计算共现矩阵
- fr = open(fr_name,"r",encoding="utf-8")
- num = 0
- line = fr.readline()
- while line:
- line = line.strip()
- line = line.replace("\n", "")
- nums = line.split("/")
- #print(nums)
- #循环遍历关键词所在位置 设置word_vector计数
- i,j = 0,0
- while i<len(nums): #ABCD共现 AB AC AD BC BD CD加1
- j = i + 1
- w1 = nums[i] #第一个单词
- while j<len(nums):
- w2 = nums[j] #第二个单词
- k = 0
- n1 = 0
- while k<len(word): #从word数组中找到单词对应的下标
- if w1==word[k]:
- n1 = k
- break
- k = k +1
- #寻找第二个关键字位置
- k = 0
- n2 = 0
- while k<len(word):
- if w2==word[k]:
- n2 = k
- break
- k = k +1
- #重点:词频矩阵赋值 只计算上三角
- if n1<=n2:
- word_vector[n1][n2] = word_vector[n1][n2] + 1
- else:
- word_vector[n2][n1] = word_vector[n2][n1] + 1
- j = j + 1
- #print(w1,w2,n1,n2)
- i = i + 1
- num += 1
- line = fr.readline()
- fr.close()
- print("next:",num)
- #---------------------------------------------------------------------------
- #CSV文件写入
- fw = open(fw_name,"w",encoding="utf-8",newline="")
- writer = csv.writer(fw)
- writer.writerow(['Word1', 'Word2', 'Weight'])
- i = 0
- while i<len(word):
- w1 = word[i]
- j = 0
- while j<len(word):
- w2 = word[j]
- #判断两个词是否共现 共现词频不为0的写入文件
- if word_vector[i][j]>0:
- #写入文件
- templist = []
- templist.append(w1)
- templist.append(w2)
- templist.append(str(int(word_vector[i][j])))
- writer.writerow(templist)
- j = j + 1
- i = i + 1
- else:
- fw.close()
- #共现分析
- fr_name = "data.txt"
- fw_name = "keywords-rela.csv"
- get_feature(fr_name,fw_name)
- print(fw_name)
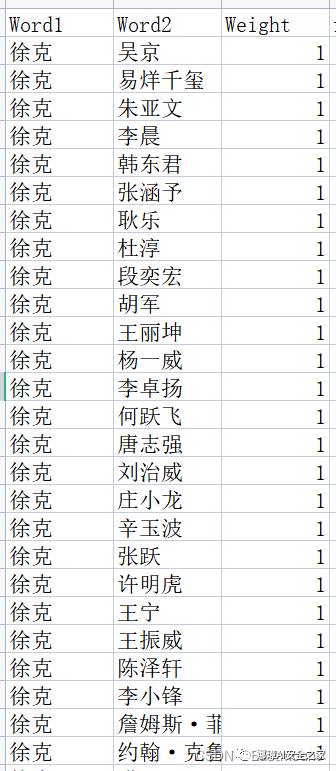
第三步:构建实体和关系数据集,按照gephi格式,如下图所示。
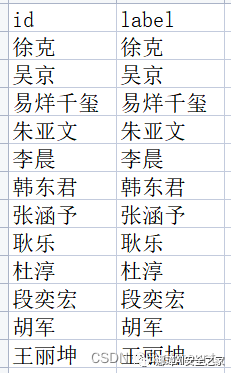

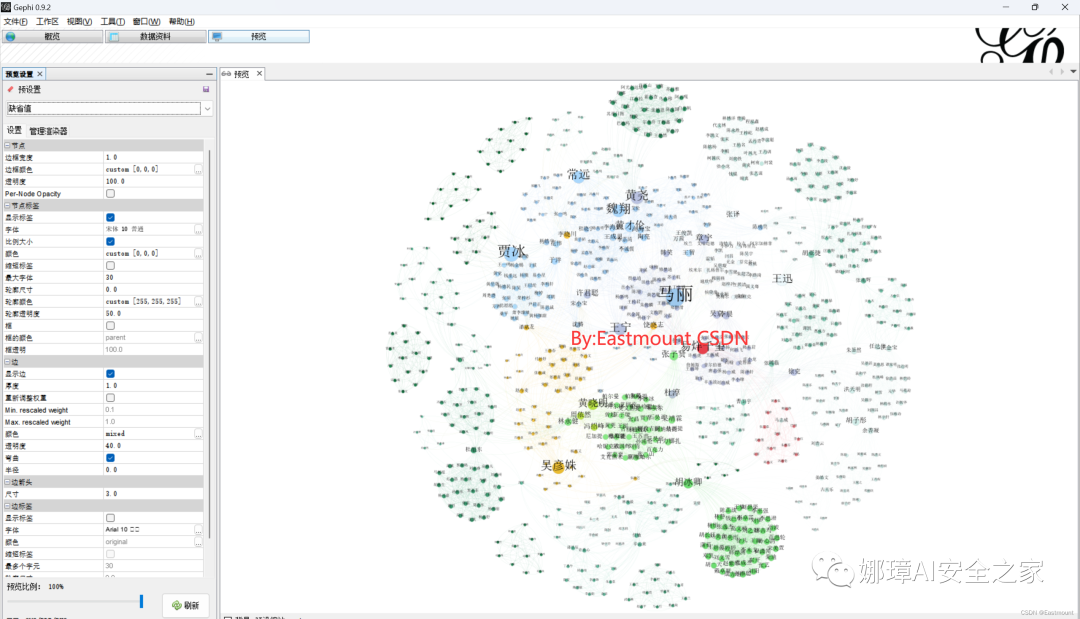
第四步:利用Gephi绘制知识图谱,导入数据至该软件并调整参数,详见作者前文。
- [Pyhon大数据分析] 五.人民网新闻话题抓取及Gephi构建主题知识图谱
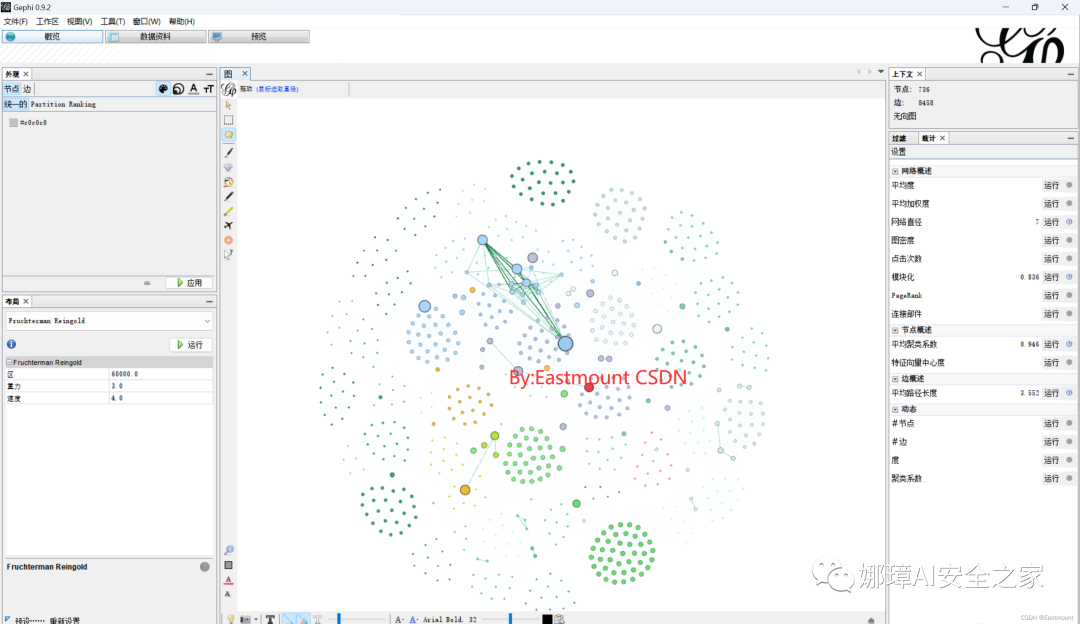
最终结果如下图所示:
十.总结写到这里,这篇文章就分享结束了,希望对您有所帮助,写得不好的地方,还请各位老师和博友批评指正。
提前祝大家新年快乐,也祝大家在读博和科研的路上不断前行。项目学习再忙,也要花点时间读论文和思考,这些大佬真心值得我们学习,加油!这篇文章就写到这里,希望对您有所帮助。由于作者英语实在太差,论文的水平也很低,写得不好的地方还请海涵和批评。同时,也欢迎大家讨论,继续努力!感恩遇见,且看且珍惜。
|
|




 发表于 2023-1-23 22:35:19
发表于 2023-1-23 22:35:19