|
|
原文链接:反汇编代码还原之加减乘
- 目录
- 一. 加法
- 1.1 加法的高级代码与反汇编
- 1.2 加法中的流水线优化
- 1.3 加法的lea指令优化
- 1.4 加法中用到了常量折叠,常量传播
- 1.5 高版本中的汇编
-
- 二. 减法
- 2.1 减法的高级代码与反汇编
- 2.2 补码转换与lea指令
-
- 三. 乘法的x86x64优化以及反汇编
- 3.1乘法的可优化选项与汇编
- 3.2 Vc6.0乘法核心代码反汇编x86
- 3.2.1核心汇编对应
- 3.2.2 lea指令对乘法的优化
- 3.2.3 lea指令与sub指令的优化
- 3.3 Visual Studio 2019 乘法核心代码反汇编x86
- 3.3.1 核心代码反汇编
- 3.3.2 SHL+sub的指令优化
- 3.4 Visual Studio 2019乘法核心代码反汇编x64
- 3.4.1核心代码反汇编x86
- 3.4.2 核心代码反汇编x64
-
- 四. 总结
系列文章
反汇编技术之熟悉IDA工具https://bbs.pediy.com/thread-224499.htm
反汇编逆向技术之寻找Main入口点https://bbs.pediy.com/thread-224500.htm
反汇编代码还原之优化方式
一、加法
1. 加法的高级代码与反汇编
而加法也特别简单,配合上一篇讲解的优化方式,可以很好的还原。
- 加法对应的 汇编 **add** 指令. 如果是加1 有可能就会使用 **inc** 指令
- int main(int argc, char* argv[])
- {
- /*
- 加法
- */
- int NumberOne = 10;
- int NumberTwo = 10;
- //scanf是防止优化
- scanf("%d",&NumberOne);
- scanf("%d",&NumberOne);
- int Count = NumberOne + NumberTwo;
-
- int Count1 = 1 + 2;
- int Count2 = NumberOne + 2;
- int Count3 = NumberTwo + 3;
-
- printf("%d",Count1,Count2,Count3);
-
- //防止优化编译器优化是很强的.虽然我们取地址了但是后续没有改变就会给我们优化掉.所以这里防止优化,但是防止优化也要能骗过编译器.比如我们可以在下面反汇编中看到.我们的count变量有得已经全部优化掉了
- scanf("%d",&Count1);
- scanf("%d",&Count2);
- scanf("%d",&Count3);
- printf("%d%d%d",&Count1,&Count2,&Count3);
- system("pause");
-
- return 0;
- }
有如下汇编代码:
- 1000 ; int __cdecl main(int argc, const char **argv, const char **envp)
- .text:00401000 _main proc near ; CODE XREF: start+AF↓p
- .text:00401000
- .text:00401000 var_10 = dword ptr -10h
- .text:00401000 var_C = dword ptr -0Ch
- .text:00401000 var_8 = dword ptr -8
- .text:00401000 var_4 = dword ptr -4
- .text:00401000 argc = dword ptr 4
- .text:00401000 argv = dword ptr 8
- .text:00401000 envp = dword ptr 0Ch
- .text:00401000 arg_C = byte ptr 10h
- .text:00401000
- .text:00401000 sub esp, 10h
- .text:00401003 lea eax, [esp+0]
- .text:00401007 mov [esp+10h+var_10], 0Ah
- .text:0040100F push eax
- .text:00401010 push offset aD ; "%d"
- .text:00401015 call _scanf
- .text:0040101A lea ecx, [esp+8]
- .text:0040101E push ecx
- .text:0040101F push offset aD ; "%d"
- .text:00401024 call _scanf
- .text:00401029 mov edx, [esp+10h]
- .text:0040102D push 13
- .text:0040102F mov [esp+24h+var_4], 3
- .text:00401037 mov [esp+24h+var_C], 13
- .text:0040103F lea eax, [edx+2]
- .text:00401042 push eax
- .text:00401043 push 3
- .text:00401045 push offset aD ; "%d"
- .text:0040104A mov [esp+30h+var_8], eax
- .text:0040104E call _printf
- .text:00401053 lea eax, [esp+30h+var_4]
- .text:00401057 push eax
- .text:00401058 push offset aD ; "%d"
- .text:0040105D call _scanf
- .text:00401062 lea ecx, [esp+38h+var_8]
- .text:00401066 push ecx
- .text:00401067 push offset aD ; "%d"
- .text:0040106C call _scanf
- .text:00401071 lea edx, [esp+40h+var_C]
- .text:00401075 push edx
- .text:00401076 push offset aD ; "%d"
- .text:0040107B call _scanf
- .text:00401080 lea eax, [esp+48h+var_C]
- .text:00401084 lea ecx, [esp+48h+var_8]
- .text:00401088 push eax
- .text:00401089 lea edx, [esp+4Ch+var_4]
- .text:0040108D push ecx
- .text:0040108E push edx
- .text:0040108F push offset aDDD ; "%d%d%d"
- .text:00401094 call _printf
- .text:00401099 add esp, 48h
- .text:0040109C push offset aPause ; "pause"
- .text:004010A1 call _system
- .text:004010A6 xor eax, eax
- .text:004010A8 add esp, 14h
- .text:004010AB retn
- .text:004010AB _main endp
1.2 加法中的流水线优化
第一段汇编查看:
- .text:00401000 sub esp, 10h
- .text:00401003 lea eax, [esp+0]
- .text:00401007 mov [esp+10h+var_10], 0Ah
- .text:0040100F push eax
- .text:00401010 push offset aD ; "%d"
- .text:00401015 call _scanf
这一段代码我们明显就能看出是有流水线优化的。 正常排序后的汇编代码应该如下:
- .text:00401000 sub esp, 10h
- .text:00401007 mov [esp+10h+var_10], 0Ah
-
- .text:00401003 lea eax, [esp+0]
- .text:0040100F push eax
- .text:00401010 push offset aD ; "%d"
- .text:00401015 call _scanf
这里是赋值指令所以直接使用mov了。单独拿出这一段是想告诉大家,第一篇是基础但也是你学习反汇编的前提。
如果以后有除法、乘法等,他们都有单独的优化。再配合流水线优化,往往就让你发觉很难,导致无法入门。
1.3 加法的lea指令优化
看下核心汇编代码,去掉scanf等:
- .text:00401007 mov [esp+10h+var_10], 0Ah
- .text:00401029 mov edx, [esp+20h+var_10]
- .text:0040103F lea eax, [edx+2]
- 我们使用scanf去掉优化后,我们的高级代码:
- int Count2 = NumberOne + 2;
直接变成了 lea指令 ,lea指令在这里并不是取地址的指令,而是计算的指令。计算的是 edx +2 结果再返回给 eax。 这是加法的一种优化方式:lea 指令优化。 所以在我们还原的时候可以还原为如下:- eax = edx + 2; edx = var10 var10 = 0xA
- 继续变化
- edx = 0xA
- eax = edx + 2
- 继续变化
- eax = 10 + 2
此时我们就反推出了加法原型。我不知道它人是否是这种反汇编风格,我是从下往上,按照上下文来进行还原。这种方法也很类似于 WG 找数据,从下向上找。
1.4 加法中用到了常量折叠,常量传播
看高级代码:
这句代码直接被我们优化为了3 符合常量折叠:
- int Count3 = NumberTwo + 3;
- .text:0040102F mov [esp+24h+var_4], 3
- .text:00401037 mov [esp+24h+var_C], 13
1.5 高版本中的汇编
Visual Studio 2019 看下反汇编:
- .text:00401080 sub_401080 proc near ; CODE XREF: start-8D↓p
- .text:00401080
- .text:00401080 var_10 = dword ptr -10h
- .text:00401080 var_C = dword ptr -0Ch
- .text:00401080 var_8 = dword ptr -8
- .text:00401080 var_4 = dword ptr -4
- .text:00401080
- .text:00401080 push ebp
- .text:00401081 mov ebp, esp
- .text:00401083 sub esp, 10h
- .text:00401086 lea eax, [ebp+var_4]
- .text:00401089 mov [ebp+var_4], 0Ah
- .text:00401090 push eax
- .text:00401091 push offset unk_41ECDC
- .text:00401096 call sub_401050
- .text:0040109B lea eax, [ebp+var_4]
- .text:0040109E push eax
- .text:0040109F push offset unk_41ECDC
- .text:004010A4 call sub_401050
- .text:004010A9 mov eax, [ebp+var_4]
- .text:004010AC add eax, 2
- .text:004010AF mov [ebp+var_10], 3
- .text:004010B6 push 0Dh
- .text:004010B8 push eax
- .text:004010B9 push 3
- .text:004010BB push offset unk_41ECDC
- .text:004010C0 mov [ebp+var_C], eax
- .text:004010C3 mov [ebp+var_8], 0Dh
- .text:004010CA call sub_401020
- .text:004010CF lea eax, [ebp+var_10]
- .text:004010D2 push eax
- .text:004010D3 push offset unk_41ECDC
- .text:004010D8 call sub_401050
- .text:004010DD lea eax, [ebp+var_C]
- .text:004010E0 push eax
- .text:004010E1 push offset unk_41ECDC
- .text:004010E6 call sub_401050
- .text:004010EB lea eax, [ebp+var_8]
- .text:004010EE push eax
- .text:004010EF push offset unk_41ECDC
- .text:004010F4 call sub_401050
- .text:004010F9 lea eax, [ebp+var_8]
- .text:004010FC push eax
- .text:004010FD lea eax, [ebp+var_C]
- .text:00401100 push eax
- .text:00401101 lea eax, [ebp+var_10]
- .text:00401104 push eax
- .text:00401105 push offset aDDD ; "%d%d%d"
- .text:0040110A call sub_401020
- .text:0040110F add esp, 48h
- .text:00401112 push offset aPause ; "pause"
- .text:00401117 call sub_4048F7
- .text:0040111C add esp, 4
- .text:0040111F xor eax, eax
- .text:00401121 mov esp, ebp
- .text:00401123 pop ebp
- .text:00401124 retn
- .text:00401124 sub_401080 endp
高版本代码变多,函数使用了EBP寻址 vc6.0 使用了esp寻址,所以我们才会看到很多调整指令。 核心汇编位置:- .text:00401089 mov [ebp+var_4], 0Ah
- .text:004010A9 mov eax, [ebp+var_4]
- .text:004010AC add eax, 2
在VC6.0中使用了 lea指令优化,在VS2019中就使用了add+mov的方式进行优化。 本质是没有改变的,但是两种都要明白。 加法的这个例子特别适合代码还原,而且不复杂。认识了流水线优化、常量传播、常量折叠,就会还原的很简单。如果有常量传播以及常量折叠,直接按照常量来还原即可。 例如:- int a = 10;
- int b = a + 1;
- printf("%d",b);
- 在汇编中反汇编后.你可能直接变成了如下
- printf("%d",11);
二、减法
2.1 减法的高级代码与反汇编
减法对应指令sub。如果是自减,那么对应的指令可能就会有 dec 指令。 计算机只会做加法,而不会做减法,所以对减法的优化,就是变为加法。 高级代码:- int main(int argc, char* argv[])
- {
- /*
- 加法
- */
- int NumberOne = argc;
- int NumberTwo = argc;
-
-
- int Count = NumberOne - NumberTwo;
-
- int Count1 = NumberOne - 2;
- int Count2 = NumberOne - 5;
- int Count3 = NumberTwo - NumberOne;
-
- printf("%d",Count1,Count2,Count3);
-
- //防止优化
- scanf("%d",&Count1);
- scanf("%d",&Count2);
- scanf("%d",&Count3);
-
- printf("%d%d%d",&Count1,&Count2,&Count3);
- system("pause");
-
- return 0;
- }
Vc6.0汇编:
- text:00401000 ; int __cdecl main(int argc, const char **argv, const char **envp)
- .text:00401000 _main proc near ; CODE XREF: start+AF↓p
- .text:00401000
- .text:00401000 var_8 = dword ptr -8
- .text:00401000 var_4 = dword ptr -4
- .text:00401000 argc = dword ptr 4
- .text:00401000 argv = dword ptr 8
- .text:00401000 envp = dword ptr 0Ch
- .text:00401000
- .text:00401000 sub esp, 8
- .text:00401003 mov eax, [esp+8+argc]
- .text:00401007 xor edx, edx
- .text:00401009 push edx
- .text:0040100A mov [esp+0Ch+argc], edx
- .text:0040100E lea ecx, [eax-2]
- .text:00401011 add eax, 0FFFFFFFBh
- .text:00401014 push eax
- .text:00401015 push ecx
- .text:00401016 push offset aD ; "%d"
- .text:0040101B mov [esp+18h+var_4], ecx
- .text:0040101F mov [esp+18h+var_8], eax
- .text:00401023 call _printf
- .text:00401028 lea eax, [esp+18h+var_4]
- .text:0040102C push eax
- .text:0040102D push offset aD ; "%d"
- .text:00401032 call _scanf
- .text:00401037 lea ecx, [esp+20h+var_8]
- .text:0040103B push ecx
- .text:0040103C push offset aD ; "%d"
- .text:00401041 call _scanf
- .text:00401046 lea edx, [esp+28h+argc]
- .text:0040104A push edx
- .text:0040104B push offset aD ; "%d"
- .text:00401050 call _scanf
- .text:00401055 lea eax, [esp+30h+argc]
- .text:00401059 lea ecx, [esp+30h+var_8]
- .text:0040105D push eax
- .text:0040105E lea edx, [esp+34h+var_4]
- .text:00401062 push ecx
- .text:00401063 push edx
- .text:00401064 push offset aDDD ; "%d%d%d"
- .text:00401069 call _printf
- .text:0040106E push offset aPause ; "pause"
- .text:00401073 call _system
- .text:00401078 xor eax, eax
- .text:0040107A add esp, 44h
- .text:0040107D retn
- .text:0040107D _main endp
2.2 补码转换与lea指令
看下核心汇编:
- .text:00401000 sub esp, 8
- .text:00401003 mov eax, [esp+8+argc] eax = argc
-
- .text:00401007 xor edx, edx
- .text:00401009 push edx
- .text:0040100A mov [esp+0Ch+argc], edx argc = 0
-
- .text:0040100E lea ecx, [eax-2]
- .text:00401011 add eax, 0FFFFFFFBh
- .text:00401014 push eax
- .text:00401015 push ecx
- .text:00401016 push offset aD ; "%d"
- .text:0040101B mov [esp+18h+var_4], ecx
- .text:0040101F mov [esp+18h+var_8], eax
第一种方式跟加法一样,使用 lea进行计算 。
第二种方式 使用了add指令,加了一个很大的数0FFFFFFFBh。 其实这个地方就是对减法的优化这个很大的数是补码。 这里补充下基础知识:
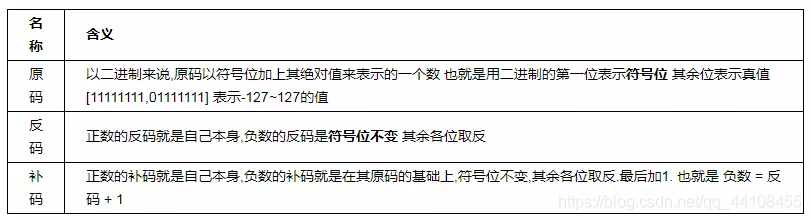 
其实负数就变成了补码了 。补码的变化就是负数取反 + 1,那么还原也是。 Not(0FFFFFFFBh) + 1 就会得出真实的值。 其余减法优化就会配合第一篇讲的,各种优化方式进行代码优化。 如果代码还原请谨记: 如果add 操作数使用了负数的表现形式,那么就可以还原为减法,因为执行的操作是减法而不是加法。
三. 乘法的x86x64优化以及反汇编
3.1乘法的可优化选项与汇编
乘法对应指令 Imul 以及对应指令 Mul 分别是有符号乘法以及无符号乘法。两个数都是变量的时候,且不满足前面所讲的变量去除优化选项,那么是无法进行优化的。乘法对于2的幂是可以进行优化的,会使用指令较短的周期来进行优化。 高级代码:- int main(int argc, char* argv[])
- {
- /*
- 乘法
- */
- int NumberOne = argc;
- int NumberTwo = argc;
-
-
-
- scanf("%d",&NumberOne);
- scanf("%d",&NumberTwo);
-
-
- int Count1 = NumberOne * NumberTwo; //不满足变量去除则就会使用原生除法指令优化
-
- int Count2 = NumberOne * 4;
-
- int Count3 = NumberTwo * 15;
-
- int Count4 = NumberOne + 4 * 3; //混合运算
-
- int Count5 = NumberTwo * 7 + 5; //混合运算
-
-
-
- printf("%d%d%d%d%d",Count1,Count2,Count3,Count4,Count5);
- system("pause");
-
- return 0;
- }
VC6.0 对应汇编:
- .text:00401000 ; int __cdecl main(int argc, const char **argv, const char **envp)
- .text:00401000 _main proc near ; CODE XREF: start+AF↓p
- .text:00401000
- .text:00401000 var_4 = dword ptr -4
- .text:00401000 argc = dword ptr 4
- .text:00401000 argv = dword ptr 8
- .text:00401000 envp = dword ptr 0Ch
- .text:00401000
- .text:00401000 push ecx
- .text:00401001 mov eax, [esp+4+argc]
- .text:00401005 mov [esp+4+var_4], eax
- .text:00401009 mov [esp+4+argc], eax
- .text:0040100D lea eax, [esp+4+var_4]
- .text:00401011 push eax
- .text:00401012 push offset aD ; "%d"
- .text:00401017 call _scanf
- .text:0040101C lea ecx, [esp+0Ch+argc]
- .text:00401020 push ecx
- .text:00401021 push offset aD ; "%d"
- .text:00401026 call _scanf
- .text:0040102B mov eax, [esp+14h+argc]
- .text:0040102F mov ecx, [esp+14h+var_4]
- .text:00401033 lea edx, ds:0[eax*8]
- .text:0040103A sub edx, eax
- .text:0040103C add edx, 5
- .text:0040103F push edx
- .text:00401040 lea edx, [ecx+12]
- .text:00401043 push edx
- .text:00401044 lea edx, [eax+eax*2]
- .text:00401047 imul eax, ecx
- .text:0040104A lea edx, [edx+edx*4]
- .text:0040104D push edx
- .text:0040104E lea edx, ds:0[ecx*4]
- .text:00401055 push edx
- .text:00401056 push eax
- .text:00401057 push offset aDDDDD ; "%d%d%d%d%d"
- .text:0040105C call _printf
- .text:00401061 push offset aPause ; "pause"
- .text:00401066 call _system
- .text:0040106B xor eax, eax
- .text:0040106D add esp, 30h
- .text:00401070 retn
- .text:00401070 _main endp
- .text:00401080 sub_401080 proc near ; CODE XREF: start-8D↓p
- .text:00401080
- .text:00401080 var_4 = dword ptr -4
- .text:00401080 arg_0 = dword ptr 8
- .text:00401080
- .text:00401080 push ebp
- .text:00401081 mov ebp, esp
- .text:00401083 push ecx
- .text:00401084 mov eax, [ebp+arg_0]
- .text:00401087 mov [ebp+var_4], eax
- .text:0040108A mov [ebp+arg_0], eax
- .text:0040108D lea eax, [ebp+var_4]
- .text:00401090 push eax
- .text:00401091 push offset unk_41ECDC
- .text:00401096 call sub_401050
- .text:0040109B lea eax, [ebp+arg_0]
- .text:0040109E push eax
- .text:0040109F push offset unk_41ECDC
- .text:004010A4 call sub_401050
- .text:004010A9 mov edx, [ebp+arg_0]
- .text:004010AC mov ecx, [ebp+var_4]
- .text:004010AF lea eax, ds:0[edx*8]
- .text:004010B6 sub eax, edx
- .text:004010B8 add eax, 5
- .text:004010BB push eax
- .text:004010BC lea eax, [ecx+0Ch]
- .text:004010BF push eax
- .text:004010C0 mov eax, edx
- .text:004010C2 shl eax, 4
- .text:004010C5 sub eax, edx
- .text:004010C7 imul edx, ecx
- .text:004010CA push eax
- .text:004010CB lea eax, ds:0[ecx*4]
- .text:004010D2 push eax
- .text:004010D3 push edx
- .text:004010D4 push offset aDDDDD ; "%d%d%d%d%d"
- .text:004010D9 call sub_401020
- .text:004010DE push offset aPause ; "pause"
- .text:004010E3 call sub_4048C7
- .text:004010E8 add esp, 2Ch
- .text:004010EB xor eax, eax
- .text:004010ED mov esp, ebp
- .text:004010EF pop ebp
- .text:004010F0 retn
- .text:004010F0 sub_401080 endp
- .text:00000001400010D0 sub_1400010D0 proc near ; CODE XREF: sub_140001268+107↓p
- .text:00000001400010D0 ; DATA XREF: .pdata:000000014002700C↓o ...
- .text:00000001400010D0
- .text:00000001400010D0 var_18 = dword ptr -18h
- .text:00000001400010D0 var_10 = dword ptr -10h
- .text:00000001400010D0 arg_0 = dword ptr 8
- .text:00000001400010D0 arg_10 = dword ptr 18h
- .text:00000001400010D0
- .text:00000001400010D0 sub rsp, 38h
- .text:00000001400010D4 mov [rsp+38h+arg_10], ecx
- .text:00000001400010D8 lea rdx, [rsp+38h+arg_10]
- .text:00000001400010DD mov [rsp+38h+arg_0], ecx
- .text:00000001400010E1 lea rcx, unk_140022760
- .text:00000001400010E8 call sub_140001080
- .text:00000001400010ED lea rdx, [rsp+38h+arg_0]
- .text:00000001400010F2 lea rcx, unk_140022760
- .text:00000001400010F9 call sub_140001080
- .text:00000001400010FE mov edx, [rsp+38h+arg_0]
- .text:0000000140001102 mov eax, [rsp+38h+arg_10]
- .text:0000000140001106 imul r10d, edx, 7
- .text:000000014000110A imul r9d, edx, 0Fh
- .text:000000014000110E imul edx, eax
- .text:0000000140001111 lea ecx, [rax+0Ch]
- .text:0000000140001114 lea r8d, ds:0[rax*4]
- .text:000000014000111C add r10d, 5
- .text:0000000140001120 mov [rsp+38h+var_10], r10d
- .text:0000000140001125 mov [rsp+38h+var_18], ecx
- .text:0000000140001129 lea rcx, aDDDDD ; "%d%d%d%d%d"
- .text:0000000140001130 call sub_140001020
- .text:0000000140001135 lea rcx, aPause ; "pause"
- .text:000000014000113C call sub_140004584
- .text:0000000140001141 xor eax, eax
- .text:0000000140001143 add rsp, 38h
- .text:0000000140001147 retn
- .text:0000000140001147 sub_1400010D0 endp
3.2 Vc6.0乘法核心代码反汇编x86
3.2.1核心汇编对应
- .text:0040102B mov eax, [esp+14h+argc] 变量赋值
- .text:0040102F mov ecx, [esp+14h+var_4]
-
- .text:00401033 lea edx, ds:0[eax*8] lea指令计算
- .text:0040103A sub edx, eax 减法计算
- .text:0040103C add edx, 5 混合运算
-
- .text:00401040 lea edx, [ecx+12]
- .text:00401044 lea edx, [eax+eax*2] 3eax
- .text:00401047 imul eax, ecx
- .text:0040104A lea edx, [edx+edx*4] 3eax + 3eax * 4 eax15
- .text:0040104E lea edx, ds:0[ecx*4]
高级代码与汇编对应:
- int NumberOne = argc;
- int NumberTwo = argc;
-
- .text:0040102B mov eax, [esp+14h+argc] 变量赋值
- .text:0040102F mov ecx, [esp+14h+var_4]
-
- int Count5 = NumberTwo * 7 + 5; //混合运算
- .text:00401033 lea edx, ds:0[eax*8] lea指令计算
- .text:0040103A sub edx, eax 减法计算
- .text:0040103C add edx, 5 混合运算
-
- int Count4 = NumberOne + 4 * 3; //混合运算
- .text:00401040 lea edx, [ecx+12]
-
- int Count1 = NumberOne * NumberTwo;
- .text:00401047 imul eax, ecx
-
- int Count3 = NumberTwo * 15;
- .text:00401044 lea edx, [eax+eax*2] 3eax
- .text:0040104A lea edx, [edx+edx*4] 3eax + 3eax * 4
-
- int Count2 = NumberOne * 4;
- .text:0040104E lea edx, ds:0[ecx*4]
通过上面我们去掉流水线优化,人肉反汇编可以看出,在乘法优化中大部分使用lea指令进行优化,特别是混合运算。
3.2.2 lea指令对乘法的优化
首先我们根据上面汇编先讲解下lea指令对乘法的优化。 高级代码:
- int Count3 = NumberTwo * 15;
对应汇编:
- .text:00401044 lea edx, [eax+eax*2] 3eax
- .text:0040104A lea edx, [edx+edx*4] 3eax + 3eax * 4
在这里lea是计算指令而不是取地址。第一行汇编,我们产生了定式,也就是eax *2 + eax 等价于3eax。 那么第二行汇编又依赖于第一行的输出,那么产生的定式也就是: 3eax + 3eax * 4 先算乘法得出 3eax + 12eax 继续计算 得出 15eax 那么我们就可以还原高级代码为eax * 15,而eax我们也看到赋值了,也就是argc变量。 所以最终代码就是argc * 15,我们原来的代码应该是NumberTwo。这里也是被编译器给优化掉了。 所以乘法的优化一定要明白lea指令,包括我们的加法也会使用。一定要认识lea 以及自己会换算。
3.2.3 lea指令与sub指令的优化
lea指令我们已经知道了。其实这里着重讲解一下sub指令优化。 高级代码与反汇编:
- int Count5 = NumberTwo * 7 + 5;
-
- .text:00401033 lea edx, ds:0[eax*8] lea指令计算
- .text:0040103A sub edx, eax 减法计算
- .text:0040103C add edx, 5 混合运算
lea指令我们说了,在括号内是计算一个值。通过汇编我们也可以得出lea得出的结果是8eax。而这里又使用sub来减去自己本身,等价于 8eax - eax = 7eax 最后再加5。 eax我们知道是argc 所以得出的反汇编为:7eax + 5 <===> 7 argc + 5 == argc + 7 + 5 这里是首先使用lea换算成2的幂来进行优化的,然后减去自己本身。这样也比直接用IMUL或者MUL执行效率高。 其他基本上都是使用lea指令进行优化了,熟悉lea看一眼即可。
- int Count5 = NumberTwo * 7 + 5;
-
- .text:00401033 lea edx, ds:0[eax*8] lea指令计算
- .text:0040103A sub edx, eax 减法计算
- .text:0040103C add edx, 5 混合运算
3.3 Visual Studio 2019 乘法核心代码反汇编x86
3.3.1 核心代码反汇编
- 获取变量到寄存器用于计算
- .text:004010A9 mov edx, [ebp+arg_0]
- .text:004010AC mov ecx, [ebp+var_4]
-
- int Count5 = NumberTwo * 7 + 5; //混合运算
- .text:004010AF lea eax, ds:0[edx*8]
- .text:004010B6 sub eax, edx
- .text:004010B8 add eax, 5
-
- int Count4 = NumberOne + 4 * 3;
- .text:004010BC lea eax, [ecx+0Ch]
-
- int Count3 = NumberTwo * 15;
- .text:004010C0 mov eax, edx
- .text:004010C2 shl eax, 4
- .text:004010C5 sub eax, edx
-
- int Count1 = NumberOne * NumberTwo;
- .text:004010C7 imul edx, ecx
-
- int Count2 = NumberOne * 4;
- .text:004010CB lea eax, ds:0[ecx*4]
观看反汇编,除了NumberTwo * 15 有所变化其余的全部同Vc6.0一样,所以说在编译器优化上并不是越高级的编译器越好的IDE是最好的。底层是一样的,优化方式还是同几十年前的VC6.0。
3.3.2 SHL+sub的指令优化
其实之前说过对于2的幂,编译器可能会选择使用移位来进行优化。这里也就出现了,也是先优化为2的幂减去自己本身。
- int Count3 = NumberTwo * 15;
- .text:004010C0 mov eax, edx
- .text:004010C2 shl eax, 4
- .text:004010C5 sub eax, edx
SHL eax,4 = eax *4 = 16eax 然后使用sub 16eax - eax = 15 eax 那么就得出计算的值了。 总结来说原理还是同vc6.0优化一样,所以要熟悉汇编。
3.4 Visual Studio 2019乘法核心代码反汇编x64
3.4.1核心代码反汇编x86
在x64下如果你还是使用x86写代码的形式,那么可能都不用优化了。优化的前提是两个操作数相乘,结果可能溢出,所以有时候会用两个寄存器表示。
而在64位下如果你还是使用两个32位操作数相乘,那么基本上就不给你优化了,原因是32*32 顶多跟64位的数相等。
那么我直接使用指令进行操作了,代码如下:
- .text:00000001400010FE mov edx, [rsp+38h+arg_0]
- .text:0000000140001102 mov eax, [rsp+38h+arg_10]
-
- 混合运算直接imul计算并想加
- .text:0000000140001106 imul r10d, edx, 7
- .text:000000014000111C add r10d, 5
-
- 以下都是直接使用imul 或者 lea进行计算了.没有可讲的
- .text:000000014000110A imul r9d, edx, 0Fh
-
- .text:000000014000110E imul edx, eax
-
- .text:0000000140001111 lea ecx, [rax+0Ch]
-
- .text:0000000140001114 lea r8d, ds:0[rax*4]
3.4.2 核心代码反汇编x64
之前高级代码都是32位数,那么我们已_int64的操作数来进行查看。 高级代码:
- __int64 NumberOne = argc;
- __int64 NumberTwo = argc;
-
-
-
- scanf("%I64d", &NumberOne);
- scanf("%I64d", &NumberTwo);
-
-
- __int64 Count1 = NumberOne * NumberTwo; //不满足变量去除则就会使用原生除法指令优化
-
- __int64 Count2 = NumberOne * 4;
-
- __int64 Count3 = NumberTwo * 15;
-
- __int64 Count4 = NumberOne + 4 * 3; //混合运算
-
- __int64 Count5 = NumberTwo * 7 + 5; //混合运算
-
-
-
- printf("%I64d%I64d%I64d%I64d%I64d", Count1, Count2, Count3, Count4, Count5);
- system("pause");
- .text:0000000140001103 mov rdx, [rsp+38h+arg_10]
- .text:0000000140001108 mov rax, [rsp+38h+arg_18]
- .text:000000014000110D imul r10, rdx, 7
- .text:0000000140001111 imul r9, rdx, 0Fh
- .text:0000000140001115 imul rdx, rax
- .text:0000000140001119 lea rcx, [rax+0Ch]
- .text:000000014000111D add r10, 5
- .text:0000000140001121 mov [rsp+38h+var_10], r10
- .text:0000000140001126 lea r8, ds:0[rax*4]
- .text:000000014000112E mov [rsp+38h+var_18], rcx
但是发现还是同上,换个大点的数看看:
- __int64 Count3 = NumberTwo * 161 * 256 *323 * NumberOne;
- .text:000000014000110F imul rax, [rsp+28h+arg_18]
- .text:0000000140001115 imul rdx, rax, 0CB2300h
其实可以发现,首先常量是直接配合常量折叠,已经给算出来了。而其它直接使用Imul进行计算了。 无符号大家可以自己建立工程查看,原理同上。
四. 总结
我们学习了乘法、加法、减法,那么可以进行总结: 1. lea 指令是比较常见与乘法的计算以及加法的计算; 2. 减法指令是可以转为补码,优化为加法。 还是那句话,高手复习,新手学习。
|
|




 发表于 2020-9-19 20:11:28
发表于 2020-9-19 20:11:28