|
|
原文链接:对一道ctf赛题的详细分析
0x01 前言最近身边有萌新想打ctf,我作为一个曾经接触过一点点ctf的业余菜鸡,就索性做了一道Web题。这篇文章主要是面向想开始打ctf的萌新,所以很多地方可能都比较简单。如有错误之处,欢迎各位指正。
0x02 Flask 简介Flask库是一个非常小型的Python Web开发框架。它有两个主要依赖:路由、调试和 Web 服务器网关接口(Web Server Gateway Interface,WSGI)子系统由 Werkzeug(http://werkzeug.pocoo.org/)提供;模板系统由 Jinja2(http://jinja.pocoo.org/)提供。Werkzeug 和 Jinjia2 都是由 Flask 的核心开发者开发而成。这里我们要重点了解一下路由。Flask需要知道对每个 URL 请求该运行哪些代码,所以保存了一个 URL 到Python 函数之间的映射关系。处理 URL 和函数之间关系的程序称为路由。在 Flask 程序中定义路由的最简便方式,是使用程序实例提供的 app.route 修饰器,把修饰的函数注册为路由。下面的例子说明了如何使用这个修饰器声明路由:
- @app.route('/')
- def index():
- return '<h1>Hello World!</h1>'
这个例子就是把 index() 函数注册为程序根地址的处理程序。如果部署程序的服务器域名为 www.example.com,在浏览器中访问 http://www.example.com 后,会触发服务器执行 index() 函数。这个函数的返回值称为响应,是客户端接收到的内容。如果客户端是 Web 浏览器,响应就是显示给用户查看的文档。
要启动服务器也很简单,程序实例用 run 方法启动 Flask 集成的开发 Web 服务器即可:
- if __name__ == '__main__':
- app.run(debug=True)
其中,name=='main' 是 Python 的惯常用法,在这里确保直接执行这个脚本时才启动开发Web 服务器。服务器启动后,会进入轮询,等待并处理请求。轮询会一直运行,直到程序停止,比如按Ctrl-C 键。有一些选项参数可被 app.run() 函数接受用于设置 Web 服务器的操作模式。在开发过程中启用调试模式会带来一些便利,比如说激活调试器和重载程序。要想启用调试模式,我们可以把 debug 参数设为 True。要想让所有主机都可以访问,可以设置参数host="0.0.0.0"。
0x03 详细分析赛题如下:
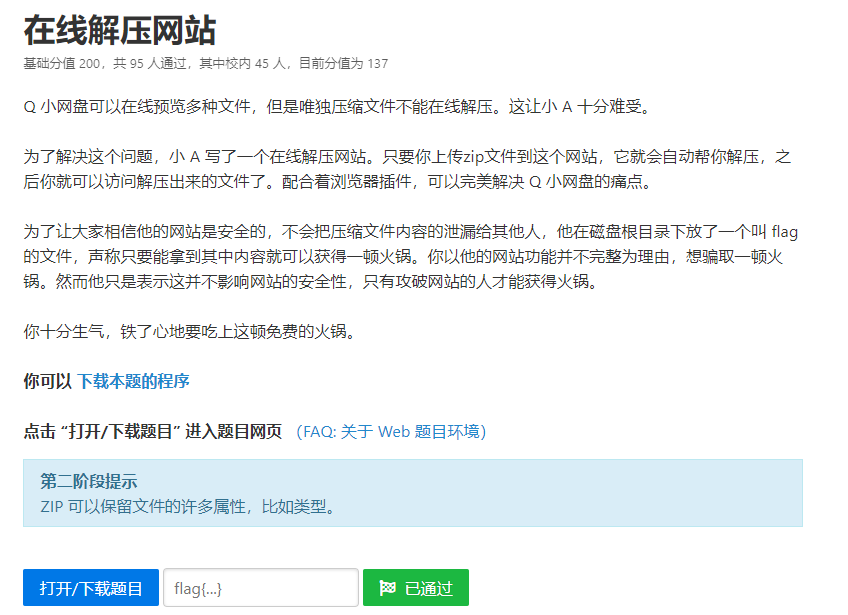 
该Web题下载下来以后源码如下:
- import os
- import json
- from shutil import copyfile
- from flask import Flask,request,render_template,url_for,send_from_directory,make_response,redirect
- from werkzeug.middleware.proxy_fix import ProxyFix
- from flask import jsonify
- from hashlib import md5
- import signal
- from http.server import HTTPServer, SimpleHTTPRequestHandler
- os.environ['TEMP']='/dev/shm'
- app = Flask("access")
- app.wsgi_app = ProxyFix(app.wsgi_app, x_for=1 ,x_proto=1)
- @app.route('/',methods=['POST', 'GET'])
- def index():
- if request.method == 'POST':
- f=request.files['file']
- os.system("rm -rf /dev/shm/zip/media/*")
- path=os.path.join("/dev/shm/zip/media",'tmp.zip')
- f.save(path)
- os.system('timeout -k 1 3 unzip /dev/shm/zip/media/tmp.zip -d /dev/shm/zip/media/')
- os.system('rm /dev/shm/zip/media/tmp.zip')
- return redirect('/media/')
- response = render_template('index.html')
- return response
- @app.route('/media/',methods=['GET'])
- @app.route('/media',methods=['GET'])
- @app.route('/media/<path>',methods=['GET'])
- def media(path=""):
- npath=os.path.join("/dev/shm/zip/media",path)
- if not os.path.exists(npath):
- return make_response("404",404)
- if not os.path.isdir(npath):
- f=open(npath,'rb')
- response = make_response(f.read())
- response.headers['Content-Type'] = 'application/octet-stream'
- return response
- else:
- fn=os.listdir(npath)
- fn=[".."]+fn
- f=open("templates/template.html")
- x=f.read()
- f.close()
- ret="<h1>文件列表:</h1><br><hr>"
- for i in fn:
- tpath=os.path.join('/media/',path,i)
- ret+="<a href='"+tpath+"'>"+i+"</a><br>"
- x=x.replace("HTMLTEXT",ret)
- return x
- os.system('mkdir /dev/shm/zip')
- os.system('mkdir /dev/shm/zip/media')
- app.run(host="0.0.0.0",port=8080,debug=False,threaded=True)
接下来就开始详细介绍。这是一个用来实现文件在线解压的网站,首先看首页对应的index函数,当访问网站首页时,可以采用GET和POST请求两种方式,对应的响应函数为index函数。题目里还有两个html文档,一个用来当上传文件时,一个用来渲染页面,这里就不贴出来了。当在首页通过html上传文档时,会执行index函数,会执行如下命令来删除文件:
rm -rf /dev/shm/zip/media/
然后拼接路径,并将上传的文件保存到这个路径:/dev/shm/zip/media/tmp.zip
之后执行命令解压:
timeout -k 1 3 unzip /dev/shm/zip/media/tmp.zip -d /dev/shm/zip/media/
解压后将压缩文件删除:
rm /dev/shm/zip/media/tmp.zip
第二个函数是media函数,有三种url请求都由这个函数来响应,其中有一个需要特别关注的,就是
@app.route('/media/<path>',methods=['GET'])
这是动态路由,就是当请求的时候如果在media的后面再加上一个字符串,可以将这个字符串作为参数传递给path变量,执行media函数中的内容:
- def media(path=""):
- npath=os.path.join("/dev/shm/zip/media",path)
- if not os.path.exists(npath):
- return make_response("404",404)
- if not os.path.isdir(npath):
- f=open(npath,'rb')
- response = make_response(f.read())
- response.headers['Content-Type'] = 'application/octet-stream'
- return response
- else:
- fn=os.listdir(npath)
- fn=[".."]+fn
- f=open("templates/template.html")
- x=f.read()
- f.close()
- ret="<h1>文件列表:</h1><br><hr>"
- for i in fn:
- tpath=os.path.join('/media/',path,i)
- ret+="<a href='"+tpath+"'>"+i+"</a><br>"
- x=x.replace("HTMLTEXT",ret)
- return x
仔细观察可以看到,path作为参数会被拼接到npath变量中,然后当npath不存在时,返回404;当npath不是目录时,会使用open函数打开,并返回给请求者。题目中提到了flag位于根目录,而path我们又可以控制,那么我们只要能够通过一种方式,将npath变成/flag是不是就可以了呢?心里想,直接用相对路径../实现路径穿越不就妥了?这么简单的吗?0x04 峰回路转说干就干,我把path设置成../../../../flag,直接在浏览器请求http://example.com/media/../../../../flag 结果发现不对,浏览器直接把我这些../全去掉了?url变成了http://example.com/media/flag,whatfuck? 第一反应是浏览器的问题,那就换个浏览器,结果发现也不行,然后想了想,那就用burp suite吧,结果还是不行。
最后,我在自己电脑上运行这个代码,开始各种调试,最后发现把斜杠换成两个反斜杠就可以了,能够实现路径穿越,读取上一层的文件内容,可是换成题目中就是不行。我仔细想了想应该是因为我本地是windows,而服务器是Linux,所以才不行的。眼看着时间不早了该睡觉了,还是没搞出来,于是喝了一杯茶,想了想,最后灵机一动,还是没想出来怎么搞。算了,睡觉吧。
到了第二天早上,我觉得这个必须得搞定。于是,我想到了Linux中的软链接!突然一下子就明白该怎么搞了!于是,打开我尘封已久的kali虚拟机,然后慢慢悠悠的敲下了如下命令:
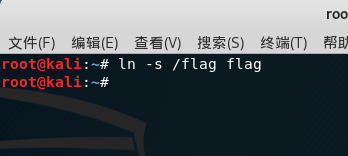
成功创建了一个指向/flag的软链接,但是这个软链接怎么利用呢?这个网站既然是用来在线解压的,那我就把软链接打成一个压缩包传上去,它直接就会被解压到当前目录。然后我直接点击该文件,直接就下载下来一个车文件,打开即可看到flag内容为:
flag{NeV3r_trUSt_Any_C0mpresSeD_file}
最后终于搞定了,这一刻还是很开心的。作为一个业余ctf菜鸡选手,实在是不容易。还是要多做题,多开阔眼界,学习各种骚操作!
|
|




 发表于 2021-11-24 11:06:38
发表于 2021-11-24 11:06:38