原文链接:机器学习之模型
Linear Model 在之前讨论了那么多有的没的,其实和机器学习这门技术本身的实现没有太大的关系,不能说没有关系,可是我们的重点还是,如何实现一个机器学习模型,那么,我们就从一个最简单的线性模型开始吧,考虑如下数据集 房价 值得买 1 1 2 0 1.5 1 1.75 0 1.25 1 这是一个关于房价和是否值得买的问题,我们可以简单地把这个数据分为一个二分问题,即,当价格大于1.25以后,就不值得买,这就是一个最简单的模型,对于这个模型的描述,我们可以用下面这个公式 当Y大于0时,不值得买,反之值得,这就是一个简化后的很简单的模型,但是实际情况不可能这么简单,我们还需要考虑诸如通勤、环境、周边等多种因素,于是这个模型就会变得越来越复杂,但是我们还是可以使用线性模型来描述它,现在我们设影响值不值得买的因素有n个,每一个记为Xn,那么表达式可以表示为 数学家们为了图方便,会将这个形式表达为 然后继续简化为 其中,A和X分别为 学过线代的同学应该很容易看出来他们是啥意思,可以说数学家们是真的喜欢偷懒啊=,= 现在我们就碰到了第一个问题,没有训练用数据怎么办?我们虽然还不知道要训练个什么玩意,但是不管是什么数据,还是得先有一个数据,这里使用的就是sklearn这个库里的数据,那么先装一下环境吧,我这里使用的ubuntu-no-vnc的docker环境,所以比较纯净 apt-get install python3 apt-get install python3-pip 现在环境就ok了,接下来考虑使用sklearn中的diabets数据集,这是一个糖尿病人的数据集,里面包含了年龄、BMI、T细胞数量等等数据,可以先看一下这个数据集具体长什么样 import matlablib as mt import numpy as np from sklearn import datasets, linear_model, model_selection X, y = datasets.load_diabetes(return_X_y=True) #X = X[:, np.newaxis, 2] print(X.shape) #(442, 10) 这是一个10维的数据,有442行,这就是我们分析用的数据,而y是一个一维的数据,包含了病人是否是糖尿病患者,或者说糖尿病情况如何的数据,之后我们需要为y打上标签,因为现在是监督学习(意思就是我们现在是打标签工程师,我们给病人通过y打上标签以后,ML就知道了这个病人是不是糖尿病人) 但是现在,我们先不考虑10维的数据,我们就单独考虑1维的数据,选取第2维 X = X[:, np.newaxis, 2] 接下来,分离测试集和训练集,啥意思呢,ML需要两个集合,一个是训练集,可以说,ML训练出来的模型都是基于训练集的,但是ML还需要测试自己训练的结果是否正确,因此,还需要测试集来鞭策自己(不是 所以,我们分离训练集和测试集,直接用了sklearn中的model_selection模块的train_test_split,这个函数会根据test_size分离训练集和测试集 X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) 现在,我们根据训练集创建线性回归模型(简单理解就是利用数学上的线性回归,来生成一条最适合数据分割的曲线) model = linear_model.LinearRegression() model.fit(X_train, y_train) 最后,使用这个模型的预测功能来预测测试集,并且最终对比测试集 from matplotlib import pyplot as plt import matplotlib import numpy as np from sklearn import datasets, linear_model, model_selection matplotlib.use('TKAGG') X, y = datasets.load_diabetes(return_X_y=True) X = X[:, np.newaxis, 2] X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) model = linear_model.LinearRegression() model.fit(X_train, y_train) pred_y = model.predict(X_test) plt.scatter(X_test, y_test, color='black') plt.plot(X_test, pred_y, color='red', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease progression') plt.show() print(X_train.shape) 可以发现啊,在一定程度上,预测线确实是分布在这些黑点点中间的,一定程度上来说没有什么问题,但很明显,我们也能发现它的不足,它做不到完美的预测,一个最要的问题就是,咱们的数据是多维的,现在才用了BMI这一维度呢
| 



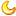
 发表于 2023-2-2 10:16:24
发表于 2023-2-2 10:16:24